Python爬虫-----下载B站视频
Posted SamRol
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫-----下载B站视频相关的知识,希望对你有一定的参考价值。
声明:本教程只供学习,不用于商业用途。教程中的视频是博主自己发布的,不存在版权问题。
目录
一、找到下载的url-----思路
案例url:炸炉后遗症_哔哩哔哩bilibili_CSGO
打开网页,按F12,进入开发者工具,选择网络,然后按F5刷新网页进行抓包。

抓完包后,根据我的经验,我们要找的包在预览中看到的是一堆乱码并且有红点的,它有可能就是我们要的音频或者视频,为了验证这个想法,我们可以用IDM这个下载工具做测试。

我们复制这段url到IDM的下载地址里,看下图操作。



复制到Address里,点击OK、Start Download,开始下载。

诶~,报错了,意料之中,它说服务器回应我们没有权限下载这个文件,点击确定,不急解决方法很简单。

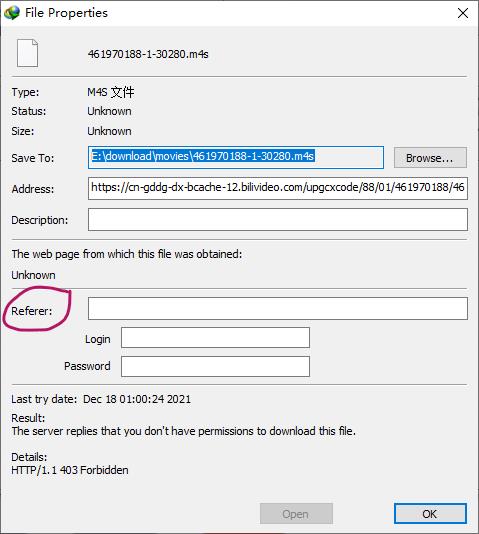
我们双击这项任务,弹出了这个窗口,映入眼帘的是我们亲爱的Referer------俗称:防盗链。接下来懂得都懂。
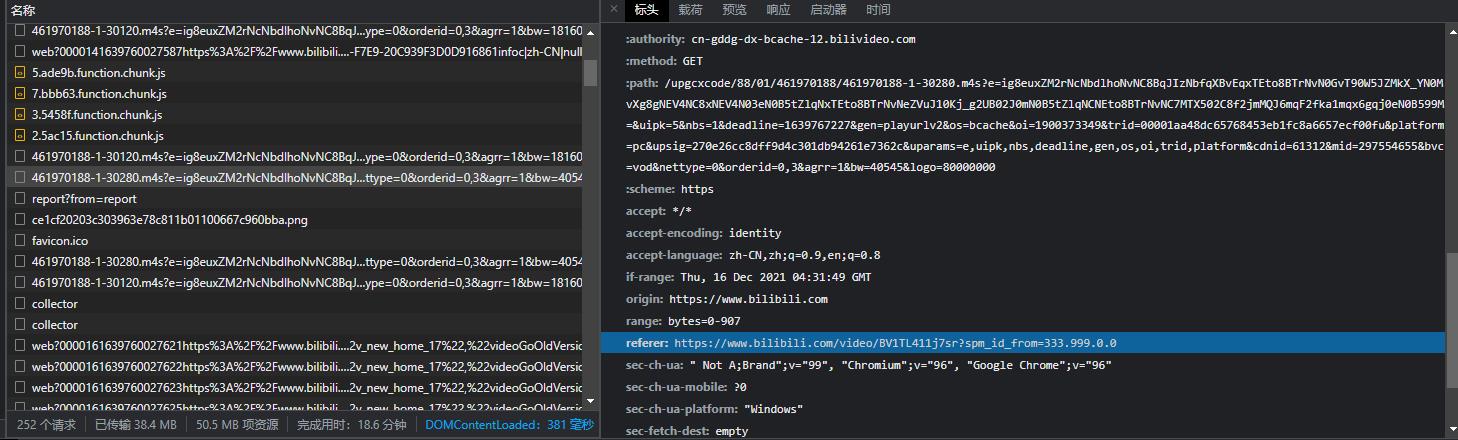
复制请求标头里面的防盗链值到刚刚那里,点击OK,再次Resume重新下载。
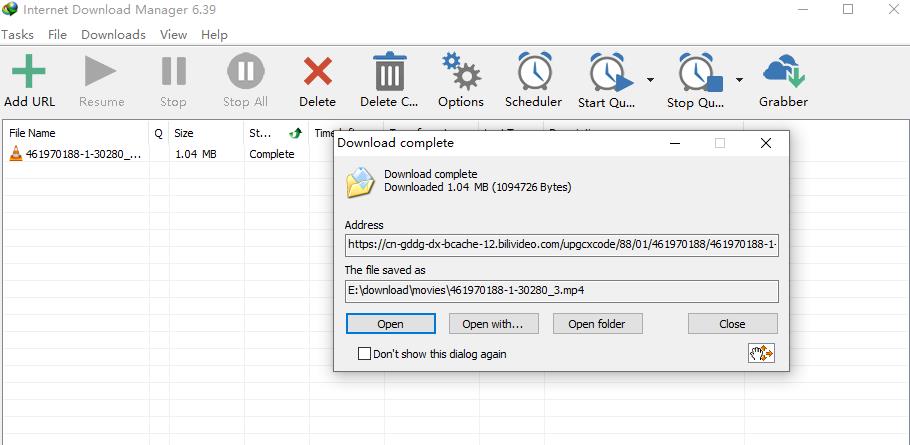
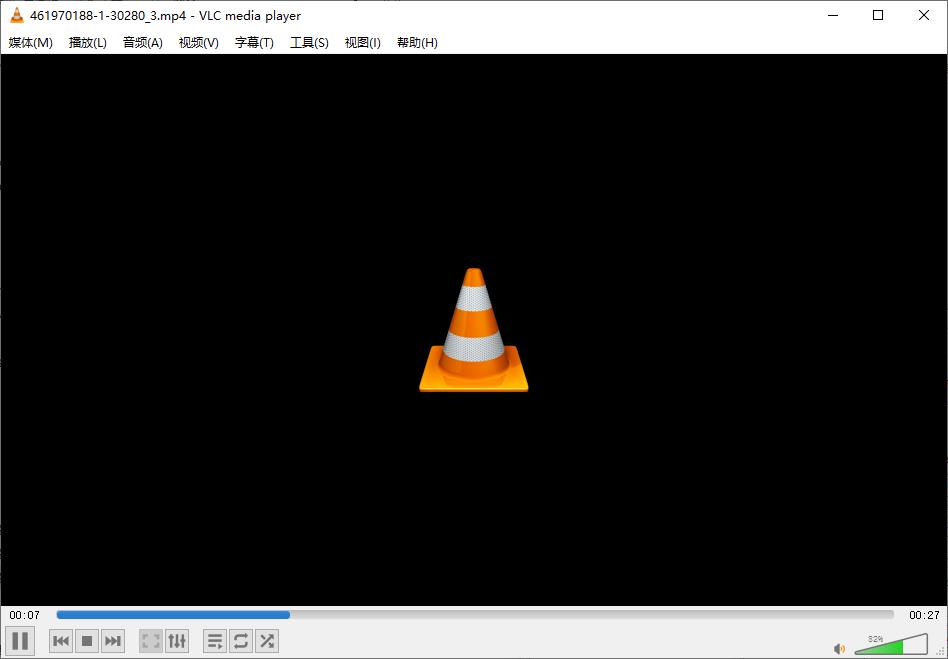 OK这次下载成功了,打开看看,我下载到的是视频文件但它里面播放的是音频,那么就是说,B站的视频和音频的url是分开的,并且说明了我刚刚的推测是对的。
OK这次下载成功了,打开看看,我下载到的是视频文件但它里面播放的是音频,那么就是说,B站的视频和音频的url是分开的,并且说明了我刚刚的推测是对的。

我们把目光转到这个刚刚用来下载的url上,发现“.m4s”这串字符,根据我的测试带有这个字符的都是可以下载的视频文件。接下来我们要看这些url会不会在页面中出现,如果有我们就可以用正则快速的获取这些url。

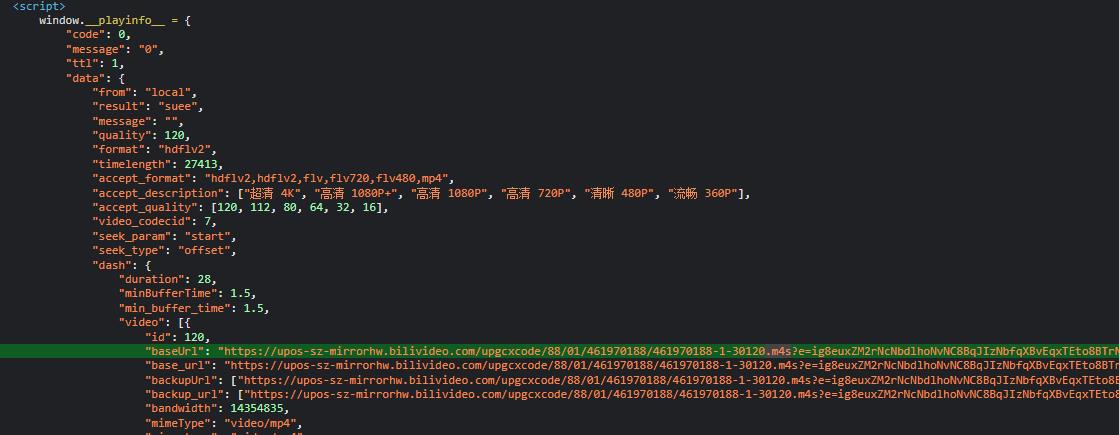 在页面源代码中的确有这些url,那就好办了!
在页面源代码中的确有这些url,那就好办了!
重点来了:通过测试可得,这些url是有分布规律的,页面中第一次出现的.m4s的url,是清晰度的最高的,如果你是b站大会员并且视频支持4K的话,那么第一条url的清晰度就是4K,第二条则是第一条url的备用链接,也就是说第三条url才是1080P高码率,以此类推直到清晰度是360p时,它下一条url就是只有音频的视频文件。当然这个规律只是暂时的而已,具体哪个是视频哪个是音频还需要自己做测试。
说到这里下面我们就可以开始用Python爬取视频了。
二、用python PA到视频文件
1.导入模块
import requests
import re2.请求表头设置
headers =
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/96.0.4664.45 Safari/537.36",
"referer": "https://www.bilibili.com/video/BV1TL411j7sr?spm_id_from=333.999.0.0",
"cookie": "输入你自己的cookie"
3.拿到页面源代码
url = "https://www.bilibili.com/video/BV1TL411j7sr?spm_id_from=333.999.0.0"
resp = requests.get(url=url,headers=headers).text
#跳过识别不了的gbk字符
resp = resp.encode("gbk","ignore").decode("gbk", "ignore")4.写正则拿url和视频名
obj = re.compile(r'"baseUrl":"(.*?)"',re.S)
obj2 = re.compile(r'<span class="tit">(.*?)</span>',re.S)
voide_url = obj.findall(resp)
voide_name = obj2.findall(resp)5.请求url并下载页面内容(下载视频文件)
resp_video = requests.get(voide_url[0],headers=headers)#第一个url视频清晰度最高
resp_audio = requests.get(voide_url[7],headers=headers)#以此类推第八个就是自有音频的视频文件
with open("0.mp4".format(voide_name[0]), mode="wb") as f:
f.write(resp_video.content)
#这里直接把视频文件保存为mp3的音频格式
with open("0.mp3".format(voide_name[0]), mode="wb") as f:
f.write(resp_audio.content)
三、运行结果

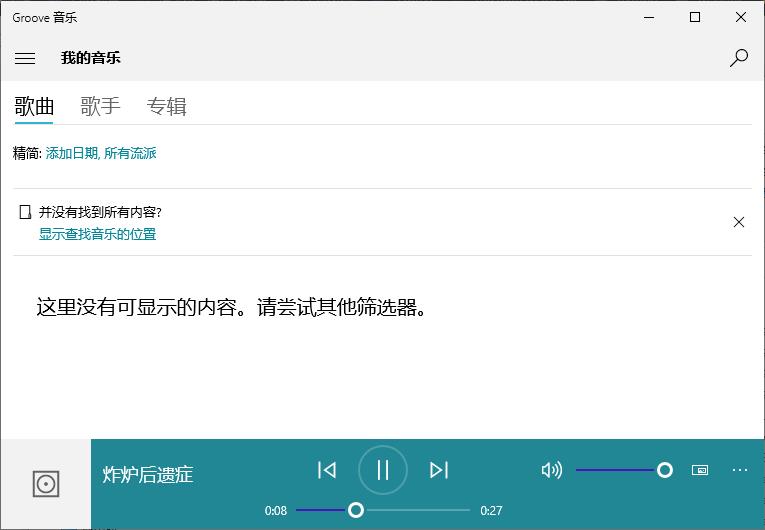
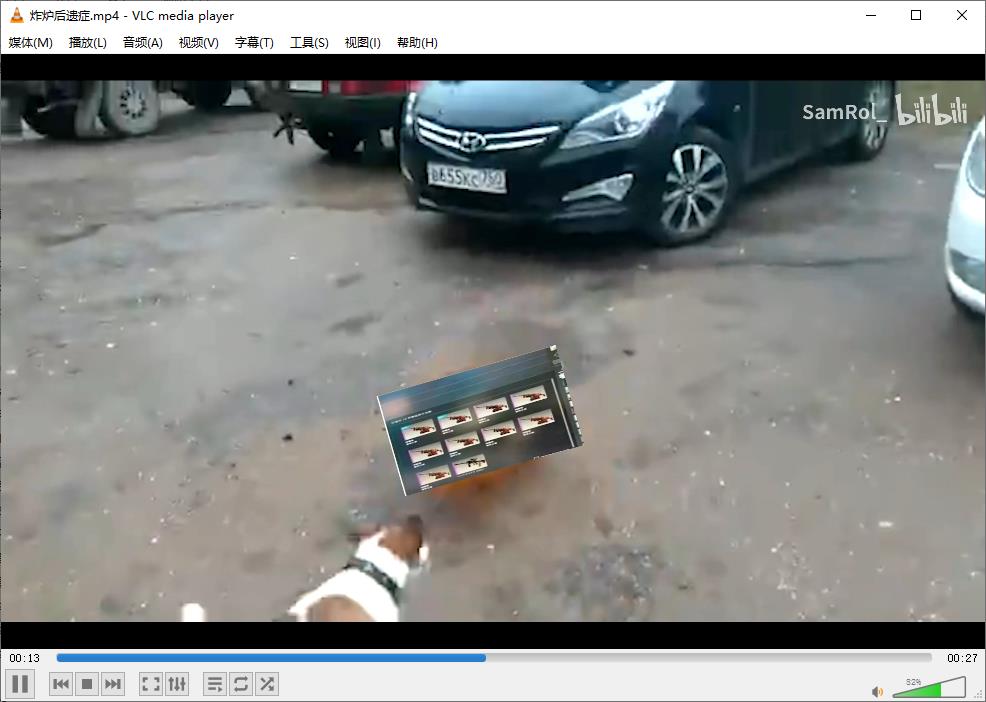
拿到并能正常播放文件,最后用一些软件合并两个文件就是一个完整的视频了。
以上是关于Python爬虫-----下载B站视频的主要内容,如果未能解决你的问题,请参考以下文章