不会python,也可以开始爬虫
Posted FlyLolo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了不会python,也可以开始爬虫相关的知识,希望对你有一定的参考价值。
用爬虫竟然得到了所在学学同学的照片,还帮助哥们儿追其他系的女孩。
–引自 《python 3 网络爬虫开发实战》序言
1. 不会python怎么爬
听别人说爬虫,自己也一直想学学,苦于没弄过python,一直没有付诸行动。虽然通过别的语言也可以实现,总的原理就是获取网页内容、解析、存储,但现在好像说爬虫不用python就“不正宗”似的。
弄了本《python 3 网络爬虫开发实战》看看,在序言里就看到了这样一段话。大概浏览了一下书的内容,觉得是不是可以不学python,直接开始配环境,装框架,通过配置的方式达到目的。 **毕竟不是想做python专职开发,**只是想“爬一爬”,通过学习爬虫,顺带学一些python的知识。
不过一定要注意,不让爬的一定不能爬,爬公开的内容也要注意,尽量降低频率,像正常访问一样,别给人家服务器造成压力。
2. 我也去大学爬点“风景”
作者爬过的大学我就不爬了,突然脑子里就冒出来了山大,那就去看看,在官网菜单中大概浏览了一下,还真找到了,上地址:https://culture.sdu.edu.cn/sdyx/zxxq/17.htm
F12看一下html

结构比较简单,非常符合作为菜鸟的我开始学习的样例。
3. 安装python环境
安装环境及相关插件就全部采用最新版本吧,官网地址:https://www.python.org/
下载对应系统安装包,本文以Windows下为例,目前最新版本为3.10.1
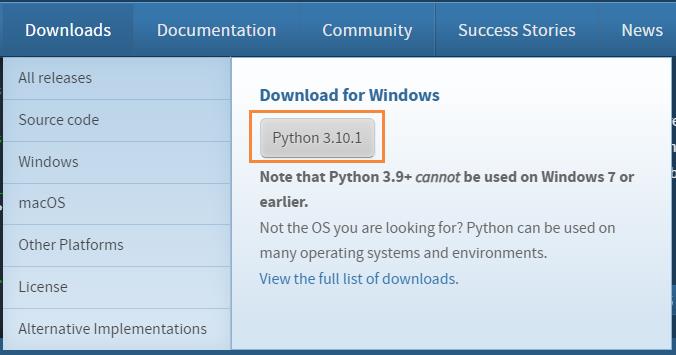
双击下载的python-3.10.1-amd64.exe文件开始安装。

勾选Add Python 3.10 to PATH, 添加对应的环境变量。
因为默认安装在AppData,改一下,选择Customize installation,进入下一步:

保持默认,继续下一步,

修改安装地址。点击Install按钮开始安装。
4. 安装Scrapy
Scrapy是适用于Python的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。
4.1 安装依赖
依次执行如下命令,安装依赖,类似其他包管理器一样
pip3 install lxml
pip3 install pyOpenSSL
pip3 install Twisted
pip3 install pyWin32
下载速度不快,慢慢等等安装完成即可:

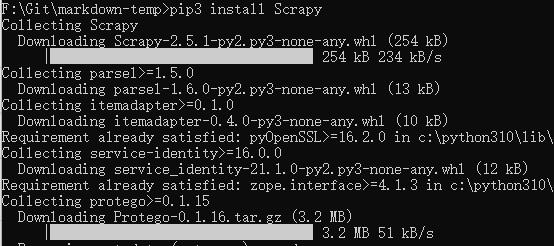
4.2 安装Scrapy
通用采用pip3命令安装:
pip3 install Scrapy
5. 创建Scrapy项目
执行scrapy startproject GetPhotos命令创建一个项目,名称暂定为“GetPhotos”
F:\\>scrapy startproject GetPhotos
New Scrapy project 'GetPhotos', using template directory 'C:\\Python310\\lib\\site-packages\\scrapy\\templates\\project', created in:
F:\\GetPhotos
You can start your first spider with:
cd GetPhotos
scrapy genspider example example.com
创建成功,在当前目录创建了一个以项目名名称的文件夹。并且给出了下一步的提示。
文件内容如下:

里面还有个同名”GetPhotos“的文件夹.
现在需要做一些配置性的工作,可以考虑用xcode打卡此目录,方便修改文件。(建议安装python插件)
5.1 修改Item字段
有个items.py文件,带如下
import scrapy
class GetphotosItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
我将它理解为Model,一个实体类贯穿全场,给他添加三个字段
class GetphotosItem(scrapy.Item):
name = scrapy.Field()
time = scrapy.Field()
src = scrapy.Field()
分别用于存储图片的标题、时间和原始地址。
5.2 创建spider
进入项目目录:
cd GetPhotos
创建spider
scrapy genspider GiveMePhotos culture.sdu.edu.cn

可以看到spiders文件夹下多了一个名为GiveMePhotos.py的文件,其内容如下
import scrapy
class GivemephotosSpider(scrapy.Spider):
name = 'GiveMePhotos'
allowed_domains = ['culture.sdu.edu.cn']
start_urls = ['http://culture.sdu.edu.cn/']
def parse(self, response):
pass
- name: spider的名称
- allowed_domains: 允许爬的域名
- start_urls:起始地址
- parse方法:即处理请求结果的方法
start_urls肯定要改成我们的目标地址:https://culture.sdu.edu.cn/sdyx/zxxq/17.htm
然后就是分析这个网页的元素,即parse方法,修改后的代码如下
import scrapy
class GivemephotosSpider(scrapy.Spider):
name = 'GiveMePhotos'
allowed_domains = ['culture.sdu.edu.cn']
start_urls = ['https://culture.sdu.edu.cn/sdyx/zxxq/17.htm']
def parse(self, response):
ul = response.css('.case_list_ul').xpath('./li')
for li in ul:
item = Test1Item()
item['name'] = li.xpath('./div/span[1]/text()').extract_first()
item['time'] = li.xpath('./div/span[2]/text()').extract_first()
item['src'] = response.urljoin(li.xpath('./div/div/img/@data-original').extract_first())
yield item
如果用过jQuery应该很容易理解这段代码,无非就是找到li标签,循环遍历,然后再提取对应的节点。最终将解析的内容给item实体。
5.3 下载图片
scrapy框架提供了相应的下载组件,如果不需要图片处理,用普通的文件下载FilesPipeline就行了,如果需要处理可以采用ImagessPipeline,这次只要下载就行了,修改pipelines.py文件
from scrapy.pipelines.files import FilesPipeline
import scrapy
class GetphotosPipeline(FilesPipeline):
def file_path(self, request, response=None, info=None, *, item=None):
#return request.url.split('/')[-1]
return item['name'] + ".jpg"
def get_media_requests(self, item, info):
yield scrapy.Request(item['src'])
代码含义是:
- 定义一个GetphotosPipeline类,继承自FilesPipeline
- 重写file_path方法,这是一个用于指定文件名的方法,可以通过Url截取,我试着用标题作为文件名。
- 重写get_media_requests方法,调用Request方法下载
5.4 项目配置
- 修改settings.py, 设置下载文件存放目录。
在settings.py中添加一行:
FILES_STORE = './imgs'
设置为子目录imgs。
- 设置FilesPipeline
找到ITEM_PIPELINES节点,
ITEM_PIPELINES =
'GetPhotos.pipelines.GetphotosPipeline': 300,
默认是用“#”号注释掉的,去掉注释。
6. 运行获取结果
执行命令:
scrapy crawl GiveMePhotos
在命令窗口可以看到爬虫启动、获取结果直到自动结束的过程。
项目目录自动多了一个imgs文件夹,如下图

7. 总结
至此,一个简要的爬虫就完成了,虽然实现的功能比较简单,但也可以说有一定的收获。
- 大概熟悉了scrapy框架,它提供了好多现成的组件。
- 进一步了解了爬虫的工作过程,为实现更复杂的功能打下基础。
虽然是本文篇幅也不算太短了,但实际上大部分都是在做安装配置的工作,实际上涉及python语法的都很少。
思考:如何自动翻页下载下一页呢?
注意:虽然是公开内容,但一定要慢慢爬。且此过程仅供学习,爬取内容不可作为其他用途。
以上是关于不会python,也可以开始爬虫的主要内容,如果未能解决你的问题,请参考以下文章
用python写网络爬虫 -从零开始 1 编写第一个网络爬虫
Python练习册 第 0013 题: 用 Python 写一个爬图片的程序,爬 这个链接里的日本妹子图片 :-),(http://tieba.baidu.com/p/2166231880)(代码片段