Flink基于Java的WordCount,根据滑动窗口动态排序实现
Posted 牌牌_琪
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink基于Java的WordCount,根据滑动窗口动态排序实现相关的知识,希望对你有一定的参考价值。
背景
刚学习Flink没多久,之前用Spark做WordCount实现排序很简单,因为Spark做的WC是简单的批处理,直接排序就完事了,但是Flink的流处理需要考虑到状态(Stateful),并且时间语义我选择的是ProcessingTime,走了几次坑之后终于实现。
需求
使用Flink统计Kafka的数据,需要按照滑动窗口统计最近窗口5min的数据,每1min输出一次结果。
技术选型:Java,Kafka,Flink
实现
首先需要新建一个Maven项目,pom文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>fule</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.12</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.70</version>
</dependency>
</dependencies>
</project>
Java代码
package com.jd.wordcount;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.*;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011;
import org.apache.flink.util.Collector;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
/**
* @author 牌牌_琪
* @date 2021/12/16 17:05
*/
public class WordCount
public static void main(String[] args) throws Exception
// 创建环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
env.enableCheckpointing(60000);
// kafka配置
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("group.id", "consumer-group");
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("auto.offset.reset", "latest");
DataStream<String> dataStream = env.addSource(new FlinkKafkaConsumer011<String>("test", new SimpleStringSchema(), properties));
// 使用flatmap将生数据转成元组型,如(spark,1),(kafka,1)
DataStream<Tuple2<String, Integer>> flatMap = dataStream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>()
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception
String[] words = value.split(" ");
for (String word : words)
out.collect(new Tuple2<>(word, 1));
);
// 水位线,因为使用processingTime,所以watermark没用到
// flatMap.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<Tuple2<String, Integer>>(Time.seconds(2))
// @Override
// public long extractTimestamp(Tuple2<String, Integer> element)
// return getCurrentWatermark().getTimestamp();
//
// );
// 按单词就行分组
KeyedStream<Tuple2<String, Integer>, Tuple> keyBy = flatMap.keyBy(0);
// 建立滑动窗口,窗口大小5min,每1min滑动一次
WindowedStream<Tuple2<String, Integer>, Tuple, TimeWindow> window = keyBy.window(SlidingProcessingTimeWindows.of(Time.minutes(5), Time.minutes(1)));
// 统计单词的词频,并转成Word对象(考虑到后边要用窗口时间触发onTimer,所以将数据转成了对象)
DataStream<Word> apply = window.apply(new WindowFunction<Tuple2<String, Integer>, Word, Tuple, TimeWindow>()
@Override
public void apply(Tuple tuple, TimeWindow window, Iterable<Tuple2<String, Integer>> input, Collector<Word> out) throws Exception
long end = window.getEnd();
int count = 0;
String word = input.iterator().next().f0;
for (Tuple2<String, Integer> tuple2 : input)
count += tuple2.f1;
out.collect(Word.of(word, end, count));
);
// 按照windowEnd属性分组
KeyedStream<Word, Tuple> windowEnd = apply.keyBy("windowEnd");
// 注意此步使用 KeyedProcessFunction 而不是 ProcessFunction ,因为 State 和 Timers 只能 keyedStream 触发
SingleOutputStreamOperator<List<Word>> process = windowEnd.process(new KeyedProcessFunction<Tuple, Word, List<Word>>()
private transient ValueState<List<Word>> valueState;
// 设置State
@Override
public void open(Configuration parameters) throws Exception
ValueStateDescriptor<List<Word>> VSDescriptor = new ValueStateDescriptor<>("list-state1",
TypeInformation.of(new TypeHint<List<Word>>()
)
);
valueState = getRuntimeContext().getState(VSDescriptor);
// 处理State,按条件触发ontimer
@Override
public void processElement(Word value, Context ctx, Collector<List<Word>> out) throws Exception
List<Word> buffer = valueState.value();
if (buffer == null)
buffer = new ArrayList<>();
buffer.add(value);
valueState.update(buffer);
// 触发条件:滑动窗口的窗口结束时间+1
// 比如,窗口时间是1000-2000,数据的windowEnd是2000,
// 如果下一条进来的windowEnd是3000,就会触发1000-2000窗口的onTimer
ctx.timerService().registerProcessingTimeTimer(value.getWindowEnd() + 1);
// 触发,对valueState中的数据按词频从大到小排序且输出
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<List<Word>> out) throws Exception
List<Word> value = valueState.value();
value.sort((a, b) -> (int) (b.getCount() - a.getCount()));
valueState.clear();
out.collect(value);
);
// 打印出来
process.print();
// 执行任务,不执行不会做任何操作
env.execute("WordCount");
package com.jd.wordcount;
/**
* @author 牌牌_琪
* @date 2021/12/16 17:28
*/
public class Word
private String word;
private long windowEnd;
private int count;
public static Word of(String word, long windowEnd,int count)
Word word1 = new Word();
word1.word = word;
word1.windowEnd = windowEnd;
word1.count = count;
return word1;
public String getWord()
return word;
public void setWord(String word)
this.word = word;
public int getCount()
return count;
public void setCount(int count)
this.count = count;
public long getWindowEnd()
return windowEnd;
public void setWindowEnd(long windowEnd)
this.windowEnd = windowEnd;
@Override
public String toString()
return "Word" +
"word='" + word + '\\'' +
", windowEnd=" + windowEnd +
", count=" + count +
'';
执行结果
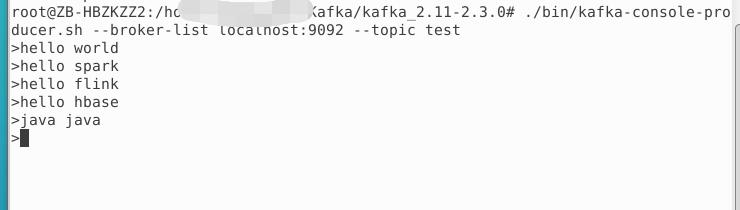
①前三条是0-1min发送的
②第四条是2-3min发送的
③第五条是5-6min发送的
flink任务每一分钟执行一次统计前五分钟的数据结果如下

说明:
第一条输出统计的①
第二条输出统计的①
第三四五输出统计的①②
第六条输出统计的②③
希望可以帮助你
以上是关于Flink基于Java的WordCount,根据滑动窗口动态排序实现的主要内容,如果未能解决你的问题,请参考以下文章