机器学习笔记:常用数据集之scikit-learn内置玩具数据集
Posted 笨牛慢耕
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习笔记:常用数据集之scikit-learn内置玩具数据集相关的知识,希望对你有一定的参考价值。
目录
1. 前言
机器学习算法是以数据为粮食的,所以机器学习开发的第一步就是数据的准备。数据预处理和特征工程是机器学习中不显眼(没有像算法开发那样亮丽)但是往往是涉及工作量最大的一部分。
对机器学习算法的学习和开发人员的一个福音是互联网上有很多开源的数据集,scikit-learn也内置了一部分简单的规模较小的数据(toy datasets,玩具数据集),并且为其它规模较大的数据集准备了相应的获取(下载)的API。这些数据集已经经过了适当的预处理,可以使得机器学习算法的学习和开发人员可以回避掉数据采集和处理的“吃力不讨好”的过程而聚焦于机器学习算法本身。
此外,scikit-learn还有自动生成面向各种机器学习问题的随机数据集的工具。这些随机生成的数据集虽然不是来源于实际测量,但是由于可以很简单地生成,而且其统计特征是受控的,所以对于机器学习的学习者或者机器学习算法的早期开发验证也是非常有用。
本系列简要介绍这几种数据集的生成、加载和/或获取方式,以及相应的基于scikit-learn的处理方法。
本文作为本系列的第一篇,先介绍scikit-learn内置的一些玩具数据集。
2. Scikit-learn内置数据集
Scikit-learn中内置了一些非常经典的小规模的数据集(称为toy datasets, 玩具数据集),这些数据集可以用sklearn.dataset模块中load_xyz系列函数进行加载(其中'xyz'表示数据集的名称)。
详细参见: 7.1. Toy datasets — scikit-learn 1.0.1 documentation
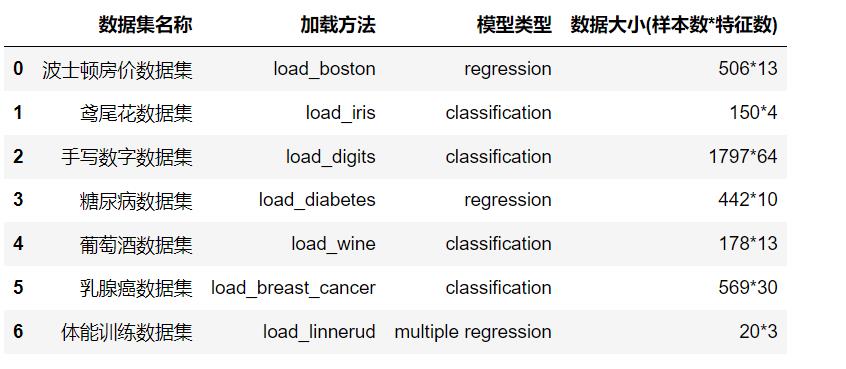
以上这个表格是用以下代码在Jupyter Notebook中生成的。 这也算是对Pandas DataFrame的一种妖娆的用法了^-^.
import pandas as pd
dataset = pd.DataFrame()
dataset['数据集名称'] = ['波士顿房价数据集','鸢尾花数据集','手写数字数据集','糖尿病数据集','葡萄酒数据集','乳腺癌数据集','体能训练数据集']
dataset['加载方法'] = ['load_boston','load_iris','load_digits','load_diabetes','load_wine','load_breast_cancer','load_linnerud']
dataset['模型类型'] = ['regression','classification','classification','regression','classification','classification','multiple regression']
dataset['数据大小(样本数*特征数)'] = ['506*13','150*4','1797*64','442*10','178*13','569*30','20*3']
dataset3. 数据加载示例
例1:鸢尾花数据集
from sklearn.datasets import load_iris, load_digits, load_diabetes
from sklearn.datasets import get_data_home
iris = sklearn.datasets.load_iris()
print(type(iris))
#print(iris.DESCR)
print(list(iris))
print(iris['data'].shape, iris['target'].shape)
print(iris['frame'])
print(iris['feature_names'])
print(iris['filename'])
print(iris['data_module'])<class 'sklearn.utils.Bunch'> ['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'] (150, 4) (150,) None ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)'] iris.csv sklearn.datasets.data
如以上例子所示,sklearn通过load_xyz()加载的数据集以Bunch的格式返回,与Python中的dict很像,里面包含键值对(key-value pair)。
首先我们可以通过list()调用观察所加载的数据集有哪些键。
需要注意的是,并不是每个数据集都具有完全相同的键集。比如说iris数据集有8个键值,而波斯顿房价数据集则只有6个。但是'data','target','DESCR'大家都有,而且可能最常用的可能就是这3个。'DESCR'包含了该数据集的描述性信息。'data','target'则顾名思义分别是指数据样本及对应的标签。
例2:糖尿病数据集
考虑到可能Pandas DataFrame可能更加为人熟知,也可以把Bunch数据转换为Pandas Dataframe然后再做进一步的处理。如下所示,DataFrame的显示更养眼一些。
当然,其实每个函数都有一个参数'as_frame',如果这个参数被设置为True的话,下载时就顺便转换成Pandas DataFrame,而不需要下载后再显式地转换了。
diabetes = sklearn.datasets.load_diabetes()
#print(df.DESCR)
print(list(diabetes))
print(diabetes['data'].shape, diabetes['target'].shape)
# 转化为df
df = pd.DataFrame.from_records(data=diabetes.data, columns=data.feature_names)
df['data', 'target', 'frame', 'DESCR', 'feature_names', 'data_filename', 'target_filename', 'data_module'] (442, 10) (442,)

例3:手写数字数据集
手写数字数据集由于其原始数据其实是二维图像,所以其中还有'images'这一项,对应了数据样本的二维表示,可以用imshow()作为图像显示出来。
from matplotlib.pyplot import imshow
df = sklearn.datasets.load_digits()
#print(df.DESCR)
print(list(df))
imshow(df['images'][10])['data', 'target', 'frame', 'feature_names', 'target_names', 'images', 'DESCR']

如上图可以看出,‘手写数字数据集’中的数字只有8∗8的大小(比之MNIST的28∗28要小得多),所以人眼看上去很难辨认,但是机器算法能够做到!
以上是关于机器学习笔记:常用数据集之scikit-learn内置玩具数据集的主要内容,如果未能解决你的问题,请参考以下文章