用C/C++自己写一个宋词生成器,气质一下子就上来了呀
Posted 流楚丶格念
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用C/C++自己写一个宋词生成器,气质一下子就上来了呀相关的知识,希望对你有一定的参考价值。
文章目录
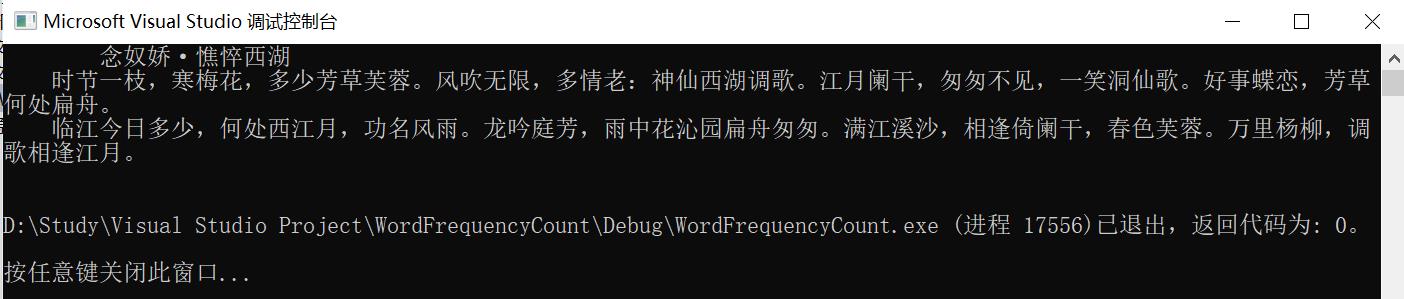
成果
先看一下我自动生成的宋词


一、模型设计
1.1 词频统计:
1.1.1 基本理论:
利用计算机统计宋词中汉字出现的频率,并通过对大量语料的学习,利用宋词自身的特性,在经过大量语料学习后,使用在宋词当中出现频率较高的词语或者单字排列组合来生成宋词。
1.1.2 算法基本思想:
- 按顺序获取宋词语料中中文汉字信息。
- 按顺序依次截取一个中文字符,并统计相同的中文字符出现的频率,按顺序保存到文件中,直到语料被截取完毕。
- 按顺序依次截取两个中文字符,并统计相同的中文字符出现的频率,按顺序保存到文件中,直到语料被截取完毕。
- 按顺序依次截取三个中文字符,并统计相同的中文字符出现的频率,按顺序保存到文件中,直到语料被截取完毕。
- 获取在宋词中,不同词牌所对应的宋词生成规律。
- 从之前所获得的的一个、两个、三个中文字符中,分别抽取一定数量的出现频率较高的中文字符。
- 按照 E 中所获得的规律,生成相应词牌所对应的宋词。
1.1.3 算法评价:
由于此算法需要频繁查找已有的中文字符,所以使用哈希表作为存储结构,这样将每次查询的时间复杂度控制在 O(1),那么整个算法的复杂度在 O(n)的时间内即可完成。当然,使用哈希表的缺点便是,占用很大的内存资源。
1.2 宋词生成
1.2.1 生成规则定义
自己可以定义要输入的格式,例如
·220--22,12,222。22,21:222。22,22,23。22,222。0--222,23,22。22,3222。22,23,22。22,222。0
其中:
| 字符 | 代表含义 |
|---|---|
| 1 | 此处应填入一个中文字符 |
| 2 | 此处应填入两个中文字符 |
| 3 | 此处应填入三个中文字符 |
| 0 | 回车换行 |
| - | 空格 |
| 其他字符 | 该词牌中相应位置应该填入的符号 |
1.2.2 生成宋词
根据自己定义的宋词输出规则,按顺序读取规则,根据当前规则的不同含义 从词频前一百的词组中 选出当前词语输出。
二、系统设计
2.1 词频统计:
2.1.1 数据结构:
pair<string, int> Pair_StrInt
词频记录:
string:中文字符
int:相对应的中文字符出现频率
// 定义诗词结构体
struct myNode
string Chant; // 词牌名
string Rules; // 格式
;
2.2.2 算法实现:
1、对用于生成词频的文件 Ci.txt,进行预处理。
- 将所有 Ci.txt 中的中文汉字信息按顺序放入变量 Text 中。
- 实现函数:void InitText(string _infile);
2、获取一个中文字的词频,并输出到文件。
-
文本中文字体编码格式采用 GB2312,一个汉字需要两个字节来表示,所以遍历 Text,每次截取两个字节,并用哈希表来保存每次截取的一个中文字,记录出现的频率。遍历结束,将哈希表中保存的数据转移到 vector 中,进行排序,调用输出函数,按词频由大到小输出到文件中。
-
实现函数:
void getOneWord(string out1);
3、获取两个中文字的词频,并输出到文件。
-
遍历 Text,每次截取四个字节(原因同上),并用哈希表来保存每次截取的两个中文字,记录出现的频率。遍历结束,将哈希表中保存的数据转移到 vector 中,进行排序,调用输出函数,按词频由大到小输出到文件中。
-
实现函数:
void getTwoWord(string out2);
4、获取三个中文字的词频,并输出到文件。
略,同上
5、遍历 Text,每次截取六个字节(原因同上),并用哈希表来保存每次截取的三个中文字,记录出现的频率。遍历结束,将哈希表中保存的数据转移到 vector 中,进行排序,调用输出函数,按词频由大到小输出到文件中。
- 实现函数:
void getThreeWord(string out3);
6、输出函数。
-
从 vector 中将保存的数据输出。
-
实现函数:void OutputFile(const vector<Pair_StrInt> &StrInt_Vec, string outfile)
7、生成词前的预处理。
-
分别抽取词频为前 100 的一个、两个、三个中文字。并对所选定的词牌进行定义。
字符 代表含义 1 此处应填入一个中文字符 2 此处应填入两个中文字符 3 此处应填入三个中文字符 0 回车换行 - 空格 其他字符 该词牌中相应位置应该填入的符号 -
实现函数:
void makePoetry(string out1, string out2, string out3);
8、自动生成并输出的词。
- 按照规则,以生成随机数在数组中定位中文字的方式自动生成并输出词。
- 实现函数:
void Poetry(string _strTmp);
2.2.3 算法评估:
- 理论上,由于采用哈希表作为存储结构,故算法时间复杂度为 O(n)。
三、系统演示
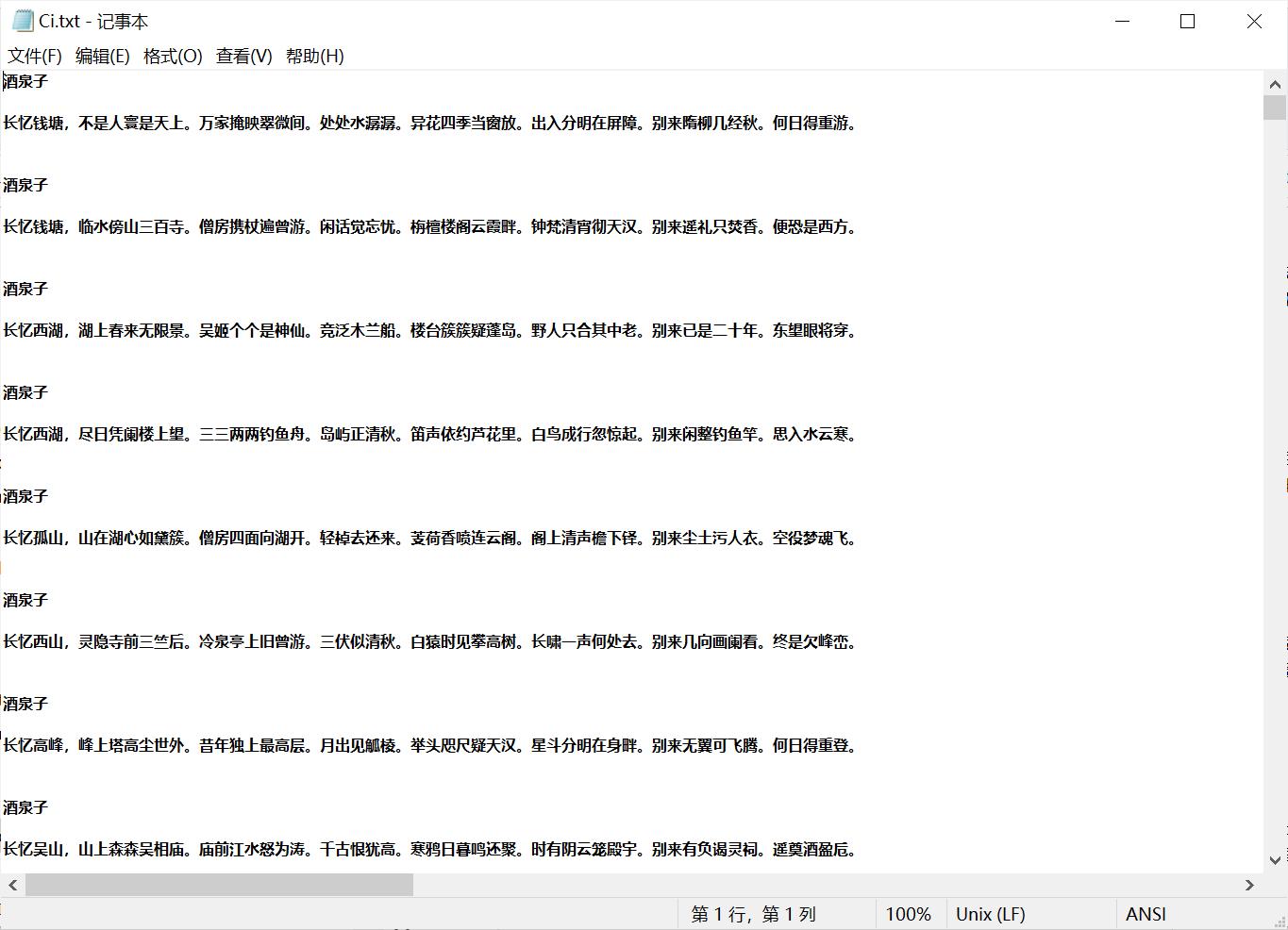
输入文件:
- Ci.txt
输出:
- 统计一个中文字的词频的文件

- 统计两个中文字的词频的文件

- 统计三个中文字的词频的文件

- 宋词生成
四、开发环境
操作系统:Windows 10
编程语言:C/C++
开发工具:Visual Studio 2017
五、源码
项目链接:
https://download.csdn.net/download/weixin_45525272/64813267
源代码
#include<iostream>
#include<functional>
#include<string>
#include<vector>
#include<map>
#include<unordered_map>
#include<fstream>
#include<sstream>
#include<algorithm>
#include <ctime>
using namespace std;
typedef long clock_time; // 程序运行时间
typedef pair<string, int> Pair_StrInt; // 词频记录:string中文字符,int相应中文字符出现频率
typedef vector<Pair_StrInt>::iterator Vec_Pair_StrInt_Itr; // 词频排序迭代器
#define ERROR_0 cerr<<"打开文件错误 !!!"<<endl;exit(1); // 警告:打开文件错误
#define ERROR_1 cerr<<"无法识别 !!!"<<endl;exit(1); // 警告:无法识别
#define Lim 100 // 用于生成古诗词的中文字符来源:词频为取前100的中文字符
string infile = "Ci.txt"; // 用于生成词频的中华古诗词文本
string outfile1 = "out1.txt"; // 统计一个中文字的词频的文件
string outfile2 = "out2.txt"; // 统计两个中文字的词频的文件
string outfile3 = "out3.txt"; // 统计三个中文字的词频的文件
string project_time = "project_time.txt"; // 存储整个程序所运行的时间的文件
string One_strArr[100]; // 用于生成古诗词,所用到的一个中文字符
string Two_strArr[100]; // 用于生成古诗词,所用到的两个中文字符
string Three_strArr[100]; // 用于生成古诗词,所用到的三个中文字符
ifstream filein;
ofstream fileout;
string Text;
/// 定义诗词结构体
struct myNode
string Chant; // 词牌名
string Rules; // 词格式
;
// 定义哈希类型的存储结构,每次查找的时间复杂度控制在 O(1)。
unordered_map<string, int> StrInt_Hash;
/// 预处理Ci.txt:将所有Ci.txt中的中文汉字信息按顺序放入变量Text 中
void InitText(string infile)
// 打开文件
filein.open(infile);
if (!filein)
ERROR_0;
// 将整个文件读入 string : 流迭代器
std::ostringstream tmp;
tmp << filein.rdbuf();
string text_tmp = tmp.str();
// 判断是否为中文编码字符
unsigned char str_judge;
string str_tmp;
int len = text_tmp.size();
for (int i = 0; i < len; )
str_judge = text_tmp[i];
// 采用GB2312编码,所有中文字符的编码范围:[0xB0, 0xF7]
if (str_judge >= 0xB0 && str_judge <= 0xF7)
str_tmp = text_tmp.substr(i, 2);
i += 2;
Text += str_tmp;
else
++i;
filein.close();
filein.clear();
/// 输出统计词频数据到文件
void OutputFile(const vector<Pair_StrInt> &StrInt_Vec, string outfile)
// 打开文件
fileout.open(outfile);
if (!fileout)
ERROR_0;
// 输入到文件
vector<Pair_StrInt>::const_iterator pair_itr;
for (pair_itr = StrInt_Vec.begin(); pair_itr != StrInt_Vec.end(); pair_itr++)
fileout << pair_itr->first << "\\t" << pair_itr->second << endl;
fileout.close();
fileout.clear();
/// 比较函数
bool Pair_StrInt_Cmp(const Pair_StrInt& p0, const Pair_StrInt& p1)
return p0.second > p1.second;
/// 获取一个中文字的词频
void getOneWord(string out1)
string str_tmp;
int str_len = Text.length();
// 两个字符拼成一个中文字符,要获取一个中文字,所以 +2 递增。
for (int i = 0; i < str_len; i += 2)
str_tmp = Text.substr(i, 2);
StrInt_Hash[str_tmp] += 1;
// 将哈希表里的数据放入临时 vector 中
vector<Pair_StrInt> StrInt_Vec_tmp(StrInt_Hash.begin(), StrInt_Hash.end());
StrInt_Hash.clear();
// 按词频排序:从大到小
std::sort(StrInt_Vec_tmp.begin(), StrInt_Vec_tmp.end(), Pair_StrInt_Cmp);
// 输出到文件中
OutputFile(StrInt_Vec_tmp, out1);
StrInt_Vec_tmp.clear();
/// 获取两个中文字的词频
void getTwoWord(string out2)
string str_tmp;
int str_len = Text.length();
// 两个字符拼成一个中文字符,要获取两个中文字,所以 +4 递增。
for (int i = 0; i < (str_len - 2); i += 2)
str_tmp = Text.substr(i, 4);
StrInt_Hash[str_tmp] += 1;
// 将哈希表里的数据放入临时 vector 中
vector<Pair_StrInt> StrInt_Vec_tmp(StrInt_Hash.begin(), StrInt_Hash.end());
StrInt_Hash.clear();
// 按词频排序:从大到小
std::sort(StrInt_Vec_tmp.begin(), StrInt_Vec_tmp.end(), Pair_StrInt_Cmp);
// 输出到文件中
OutputFile(StrInt_Vec_tmp, out2);
StrInt_Vec_tmp.clear();
/// 获取三个中文字的词频
void getThreeWord(string out3)
string str_tmp;
int str_len = Text.length();
// 两个字符拼成一个中文字符,要获取两个中文字,所以 +6 递增。
for (int i = 0; i < (str_len - 4); i += 2)
str_tmp = Text.substr(i, 6);
StrInt_Hash[str_tmp] += 1;
// 将哈希表里的数据放入临时 vector 中
vector<Pair_StrInt> StrInt_Vec_tmp(StrInt_Hash.begin(), StrInt_Hash.end());
StrInt_Hash.clear();
// 按词频排序:从大到小
std::sort(StrInt_Vec_tmp.begin(), StrInt_Vec_tmp.end(), Pair_StrInt_Cmp);
// 输出到文件中
OutputFile(StrInt_Vec_tmp, out3);
StrInt_Vec_tmp.clear();
// 定义自动生成一首词的规则
/*
为自动生成一首词,先根据不同词牌名,定义不同的格式。
在此:
1 代表 此处应填入一个中文字符
2 代表 此处应填入两个中文字符
3 代表 此处应填入三个中文字符
0 代表 回车换行
- 代表 空格
其他字符 代表 该词牌中相应位置应该填入的符号
据以上规则:
1)makePoetry(string out1, string out2, string out3) 函数对所选定的词牌进行定义。
2)Poetry(string _strTmp) 函数自动生成并输出的词。
*/
/// 自动生成词
void Poetry(string str_tmp)
int len = str_tmp.length();
int myRandom;
srand((unsigned)(time(NULL)));
for (int i = 0; i < len; i++)
switch (str_tmp[i])
case '1':
myRandom = rand() % Lim;
cout << One_strArr[myRandom];
break;
case '2':
myRandom = rand() % Lim;
cout << Two_strArr[myRandom];
break;
case '3':
myRandom = rand() % Lim;
cout << Three_strArr[myRandom];
break;
case '0':
cout << '\\n';
break;
case '-':
cout << " ";
break;
default:
cout << str_tmp.substr(i, 2);
++i;
break;
cout << endl;
/// 生成词前的预处理
void makePoetry(string out1, string out2, string out3)
ifstream fin1, fin2, fin3;
ofstream fout1, fout2, fout3;
fin1.open(out1);
if (!fin1)
ERROR_0;
fin2.open(out2);
if (!fin2)
ERROR_0;
fin3.open(out3);
if (!fin3)
ERROR_0;
string strTmp;
for (int i = 0; i < Lim; ++i)
getline(fin1, strTmp);
One_strArr[i] = strTmp.substr(0, 2);
getline(fin2, strTmp);
Two_strArr[i] = strTmp.substr(0, 4);
getline(fin3, strTmp);
Three_strArr[i] = strTmp.substr(0, 6);
myNode node0;
node0.Chant = "念奴娇";
node0.Rules = "·220--22,12,222。22,21:222。22,22,23。22,222。0--222,23,22。22,3222。22,23,22。22,222。0";
string strTmp0 = "----" + node0.Chant + node0.Rules; // "----"表示为生成的词设置格式
Poetry(strTmp0);
//system("pause");
void Solve()
InitText(infile);
ofstream fout;
fout.open(project_time);
clock_t myStart, myFinish;
double totaltime;
myStart = clock(); // 开始计时
getOneWord(outfile1); // 获取一个中文字的词频
getTwoWord(outfile2); // 获取两个中文字的词频
getThreeWord(outfile3); // 获取三个中文字的词频
myFinish = clock(); // 计时结束
totaltime = (double)(myFinish - myStart) / CLOCKS_PER_SEC; // 计算出程序总的运行时间
fout << "运行时间为: " << totaltime << " 秒。" << endl;
fout.close();
fout.clear();
makePoetry(outfile1, outfile2, outfile3); // 自动生成一首词
int main()
Solve();
return 0;
以上是关于用C/C++自己写一个宋词生成器,气质一下子就上来了呀的主要内容,如果未能解决你的问题,请参考以下文章