C/C++小案例:汉语自动分词器
Posted 流楚丶格念
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C/C++小案例:汉语自动分词器相关的知识,希望对你有一定的参考价值。
文章目录
成果
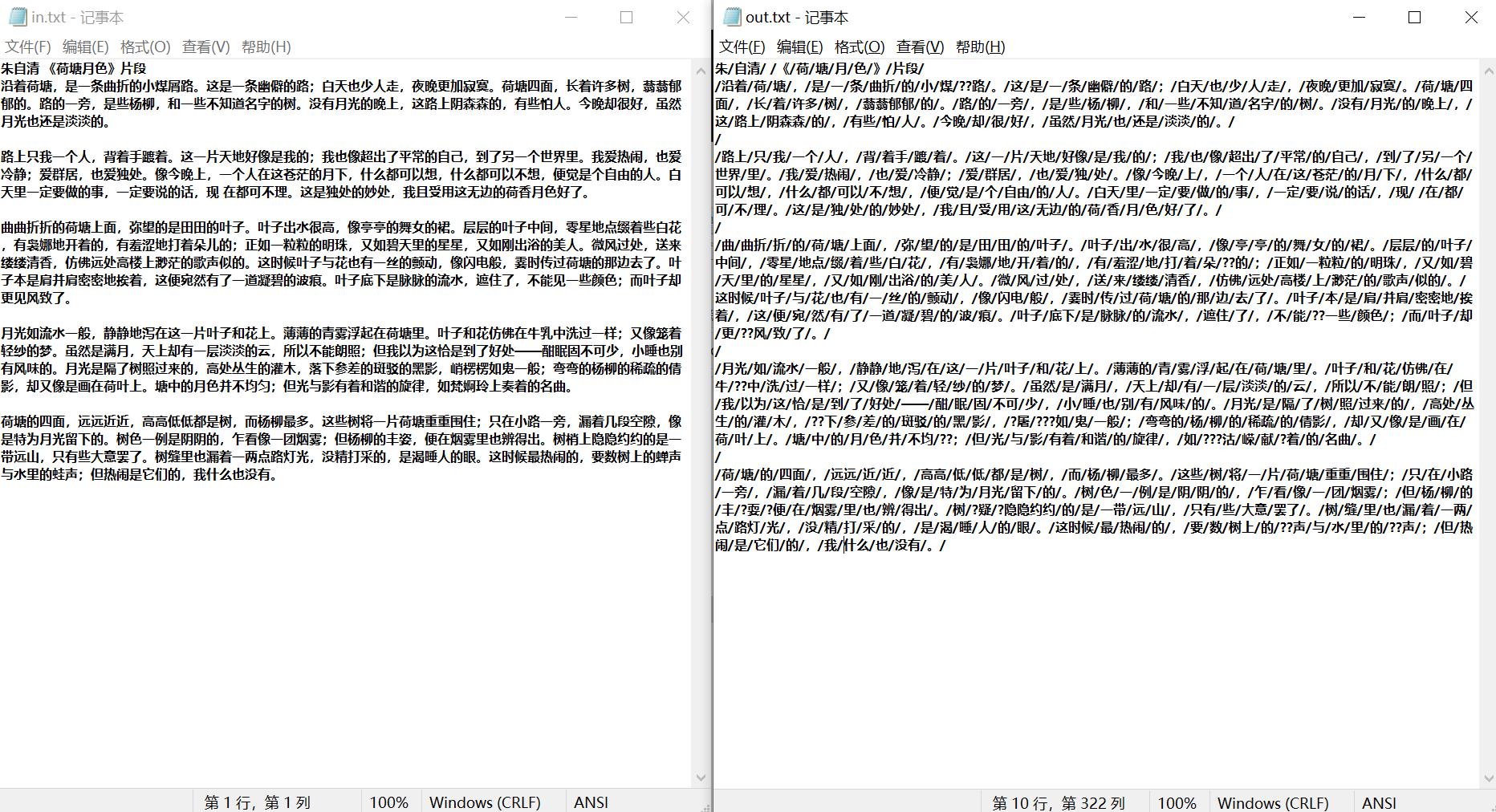
一、模型设计
1.1 汉语自动分词:
1.1.1 基本理论:
词是自然语言中能够独立运用的最小单位,是自然语言处理的基本单位。自动词法分析就是利用计算机对自然语言的形态 (morphology) 进行分析,判断词的结构和类别等。词性或称词类(Part-of-Speech, POS)是词汇最重要的特性,是连接词汇到句法的桥梁。
1.1.2 算法基本思想:
正向最大匹配算法 (Forward MaxMatch, FMM) 描述:
假设句子:S = c1c2…cn ,某一词:w = c1c2…cm,m 为词典中最长词的字数。
(1)令 i=0,当前指针 pi 指向输入字串的初始位置,执行下面的操作。
(2)计算当前指针 pi 到字串末端的字数(即未被切分字串的长度)n,如果 n=1,转 第四步,结束算法。否则,令 m=词典中最长单词的字数,如果 n<m, 令 m=n;
(3)从当前 pi 起取 m 个汉字作为词 wi,判断:
a.如果 wi 确实是词典中的词,则在 wi 后添加一个切分标志,转(c);
b.如果 wi 不是词典中的词且 wi 的长度大于 1,将wi 从右端去掉一个字,转(a)步;否则(wi 的长度等于 1),则在 wi 后添加一个切分标志(单字),执行 (c)步;
c.根据 wi 的长度修改指针 pi 的位置,如果 pi 指向字串末端,转(4),否则,i=i+1,返回第二步;
(4)输出切分结果,结束分词程序。
1.1.3 算法评价:
优点:
- 程序简单易行,开发周期短;
- 仅需要很少的语言资源(词表),不需要任何词法、句法、语义资源;
缺点:
-
歧义消解的能力差;
-
切分正确率不高,一般在 95%左右。
二、系统设计
2.1 汉语自动分词:
2.1.1 数据结构:
unordered_map<string, int> StrInt_Hash : 哈希表存储词典(便于查询)
2.1.2 算法实现:
-
对词典进行预处理,截取出所有中文汉字。
循环读入字符串(遇到空格刚好读出一个字符串),直到文件结束。在此过程中,记录下词典中最长词的字节数。
实现函数:
void InitText(string infile); -
正向最大匹配算法。
对汉语自动分词的正向匹配算法的实现(模型方法中有详细叙述),并将生成好的分词结果写入到文件中。
实现函数:
void PositiveMaxMatch(string _infile, string _outfile);
2.1.3 算法评估:
理论上,时间复杂度最差为:(Maxlen*Maxlen) (Maxlen 代表词典中最长词的字节数)
三、开发环境
操作系统:Windows 10
编程语言:C/C++
开发工具:Visual Studio 2017
四、源码
项目链接:
https://download.csdn.net/download/weixin_45525272/65216294
源代码:
#include <iostream>
#include <cstdlib>
#include <cstdio>
#include <string>
#include <fstream>
#include <sstream>
#include <unordered_map>
#include <ctime>
using namespace std;
/// 预处理
#define MAX(a,b) a>b?a:b // 获取两个值中最大的
#define MIN(a,b) a<b?a:b // 获取两个值中最小的
#define ERROR_0 cerr << "Open error !!!" << endl; exit(1); // 文件打开出错提示
int MaxLen; // 词典中最长词的字节数
unordered_map<string, int> StrInt_Hash; // 哈希表存储词典(便于查询)
const string ini_file = "1998-01-2003版-带音.txt"; // 词典
const string infile = "in.txt"; // 需要分词的文件
const string outfile = "out.txt"; // 分词后的文件
string project_time = "project_time.txt"; // 存储整个程序所运行的时间的文件
// 对词典进行预处理,截取出所有中文汉字
void InitText(string _infile)
// 打开文件
ifstream file_in;
file_in.open(_infile);
if (!file_in)
ERROR_0;
string str_tmp, str;
int pos;
MaxLen = 0;
// 循环读入字符串(遇到空格刚好读出一个字符串),直到文件结束。
// 在此过程中,记录下词典中最长词的字节数
while (file_in >>str_tmp)
pos = str_tmp.find("/");
str = str_tmp.substr(0,pos);
if (str.size() > MaxLen)
MaxLen = str.size();
StrInt_Hash[str] = 1;
// 关闭文件
file_in.close();
file_in.clear();
/// 正想最大匹配算法
void PositiveMaxMatch(string _infile, string _outfile)
// 初始化
InitText(ini_file);
// 打开文件
ifstream file_in;
ofstream file_out;
file_in.open(_infile);
file_out.open(_outfile);
if (!file_in)
ERROR_0;
if (!file_out)
ERROR_0;
// 开始计时
ofstream file_out_time;
file_out_time.open(project_time);
if (!file_out_time)
ERROR_0;
clock_t myStart, myFinish;
double time_total;
myStart = clock();
/// 匹配算法
std::ostringstream tmp;
tmp << file_in.rdbuf();
string text_tmp = tmp.str();
int myBegin = 0;
int myEnd = text_tmp.size();
while (myBegin< myEnd)
string str;
int num;
// 从最大长度的哈希元素进行查找,找不到长度-1,直到找到匹配的
for (num=MIN(MaxLen,(text_tmp.size()-myBegin));num>0;num--)
str = text_tmp.substr(myBegin,num);
// 如果在哈希表中能找到并且,那么就写进去
if (StrInt_Hash.find(str)!=StrInt_Hash.end())
file_out << str;
myBegin += num;
break;
// 如果没找到,那么不构成词,单独划分
if (0 == num)
file_out << text_tmp.substr(myBegin, 1);
myBegin += 1;
file_out << "/";
// 结束计时
myFinish = clock();
time_total = (double)(myFinish - myStart) / CLOCKS_PER_SEC; // 计算运行总时间
file_out_time << "运行时间为: " << time_total << " 秒。" << endl;
// 关闭文件
file_out_time.close();
file_out_time.clear();
file_out.close();
file_out.clear();
file_in.close();
file_in.clear();
int main()
PositiveMaxMatch(infile,outfile);
return 0;
以上是关于C/C++小案例:汉语自动分词器的主要内容,如果未能解决你的问题,请参考以下文章