线程池(ThreadPoolExecutor)源码解析
Posted 小志的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了线程池(ThreadPoolExecutor)源码解析相关的知识,希望对你有一定的参考价值。
目录
一、线程池概念介绍
1.1、什么是线程池
- 池化技术其实在技术生态圈中是比较常见的,比如:对象池、连接池等等。
- 为什么会有线程池这个东西存在呢?其实原因跟其他池化技术是一样的,都是由于创建对象、连接、线程等操作时是比较“重”的,耗时的,高成本的。针对与这种场景,我们都会采用能复用就复用,而不是每次都要重新的去创建一遍,那么在性能的提升、资源的利用率上,都能获得非常理想的效果。
- 在介绍线程池之前,我们先插入一个小内容,就是线程状态流转如下图:

1.2、线程池工作流程
-
线程池的工作原理大致分为4步,如下图所示:

-
【上图解释如下】
-
首先,当有任务要执行的时候,会计算线程池中存在的线程数量与核心线程数量(corePoolSize)进行比较,如果小于,则在线程池中创建线程,否则,进行下一步判断。
-
其次,如果不满足上面的条件,则会将任务添加到阻塞队列<>/font(1.6、 阻塞队列)中。等待线程池中的线程空闲下来后,获取队列中的任务进行执行。
-
然后,如果队列中也塞满了任务,那么会计算线程池中存在的线程数量与最大线程数量(maxnumPoolSize)进行比较,如果小于,则在线程池中创建线程。
-
最后,如果上面都不满足,则会执行对应的拒绝策略(1.5、拒绝策略)。
1.3、线程池的代码用例
-
如上已经了解到了线程池的基本工作流程,那么如何使用线程池呢?如下图实例了解如何使用线程池,才可以基于它对应的方法进行源码分析。

-
通过上面的使用例子,我们针对源码的解析就要针对红框的这两点进行深入探索,一个是ThreadPoolExecutor的构造函数,另一个就是execute方法。
二、源码解析——构造函数
2.1、线程池的构造函数及类的继承关系
-
首先,我们先要了解一下ThreadPoolExecutor线程池类的继承关系,好对它有一个宏观的认知,如下图所示:

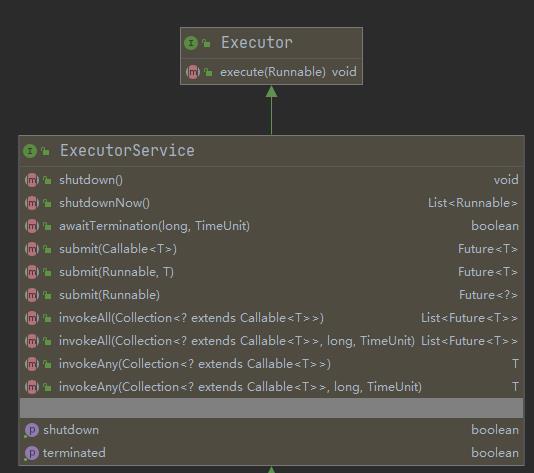
-
那么针对它的构造函数,其实我们能够发现,线程池的工作原理在构造函数的入参中都是有映射的,如下所示:

-
【上图解释如下】
-
corePoolSize: 核心线程数。
-
maximumPoolSize: 最大线程数。
-
keepAliveTime: 线程池中线程的最大闲置生命周期。
-
unit: 针对keepAliveTime的时间单位。
-
workQueue: 阻塞队列。
-
threadFactory: 创建线程的线程工厂。
-
handler: 拒绝策略。
2.2、Executors提供的线程池模板
-
在Executors中,已经给我们提供了很多种线程池的实现。如下图所示:
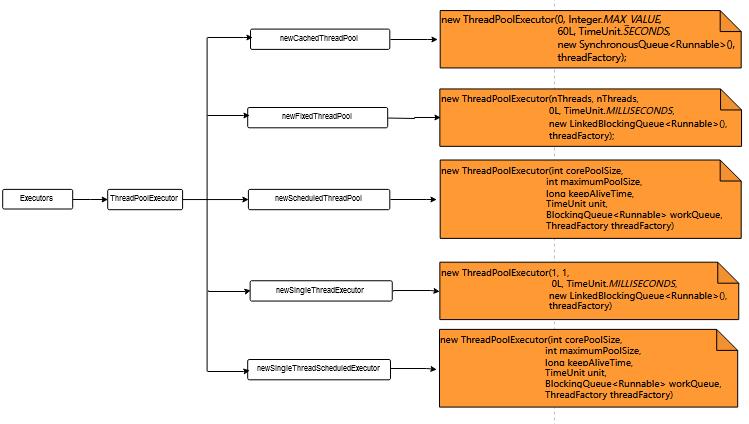
-
【上图解释如下】
-
newCachedThreadPool
创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。 -
newFixedThreadPool
创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。 -
newScheduledThreadPool
创建一个定长线程池,支持定时及周期性任务执行。 -
newSingleThreadScheduleExecutor
创建一个单线程执行程序,它可安排在给定延迟后运行命令或者定期地执行。(注意,如果因为在关闭前的执行期间出现失败而终止了此单个线程,那么如果需要,一个新线程会代替它执行后续的任务)。可保证顺序地执行各个任务,并且在任意给定的时间不会有多个线程是活动的。与其他等效的 newScheduledThreadPool(1) 不同,可保证无需重新配置此方法所返回的执行程序即可使用其他的线程。 -
newSingleThreadExecutor
创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
2.3、拒绝策略的实现
-
线程池中提供了如下拒绝策略:

-
【上图解释如下】
-
AbortPolicy
丢弃任务并抛出RejectedExecutionException异常。 -
DiscardPolicy
丢弃任务,但是不抛出异常。 -
DiscardOldestPolicy
丢弃队列中最前面的任务,然后重新尝试执行任务。 -
CallerRunsPolicy
由调用线程处理该任务。
2.4、任务队列BlockingQueue的实现
-
线程池中提供了如下任务队列:

-
【上图解释如下】
-
ArrayBlockingQueue
它是一个有界的阻塞队列,其内部实现是将对象放到一个数组里。一但初始化,大小就无法修改 -
LinkedBlockingQueue
它内部以一个链式结构(链接节点)对其元素进行存储。可以指定元素上限,否则,上限则为Integer.MAX_VALUE。 -
DelayQueue
它对元素进行持有直到一个特定的延迟到期。注意:进入其中的元素必须实现Delayed接口。 -
PriorityBlockingQueue
它是一个无界的并发队列。无法向这个队列中插入null值。所有插入到这个队列中的元素必须实现Comparable接口。因此该队列中元素的排序就取决于你自己的Comparable实现。 -
SynchronousQueue
它是一个特殊的队列,它的内部同时只能够容纳单个元素。如果该队列已有一个元素的话,那么试图向队列中插入一个新元素的线程将会阻塞,直到另一个新线程将该元素从队列中抽走。同样的,如果队列为空,试图向队列中抽取一个元素的线程将会被阻塞,直到另一个线程向队列中插入了一条新的元素。因此,它其实不太像是一个队列,而更像是一个汇合点。
三、 源码解析——execute(Runnable command)
- 针对execute方法可以分为四部分来分析,下面就针对这四部分深入解析
- 第一部分:什么是ctl
- 第二部分:线程池中的线程数量小于核心线程数的代码逻辑
- 第三部分:不满足【第二部分条件】时,任务添加到队列的代码逻辑
- 第四部分:不满足【第三部分条件】时,线程池中的线程数量小于最大线程数代码逻辑以及拒绝策略的代码逻辑
3.1、流程概述
-
execute的整体流程如下所示:
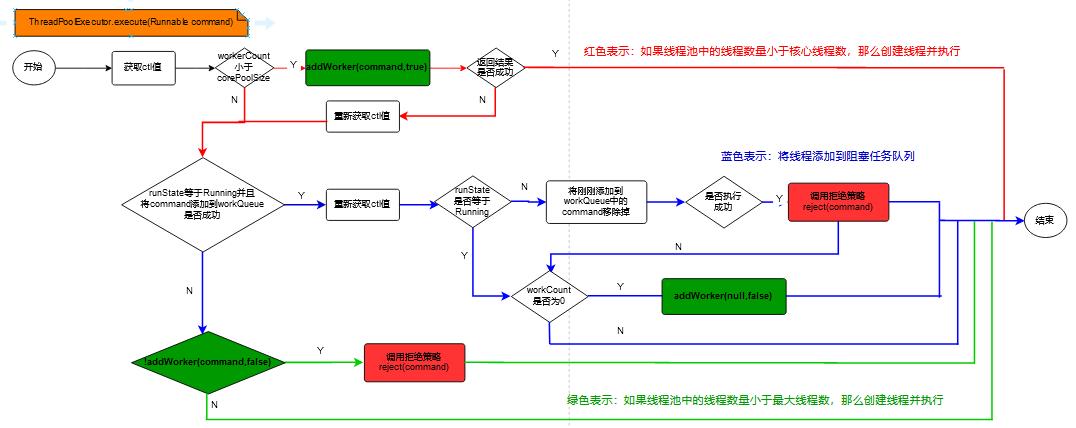
-
【上图解释如下】
-
在上面的流程图中,我们看到三块绿色的addWorker方法,和两块红色的reject方法,这两个方法是我们解析的重点。
3.2、什么是ctl
-
当我们看execute方法的时候,首先看到的就是ctl。

-
那么ctl到底是什么东西呢?下面截图源码和注释就是ctl所包含的方法
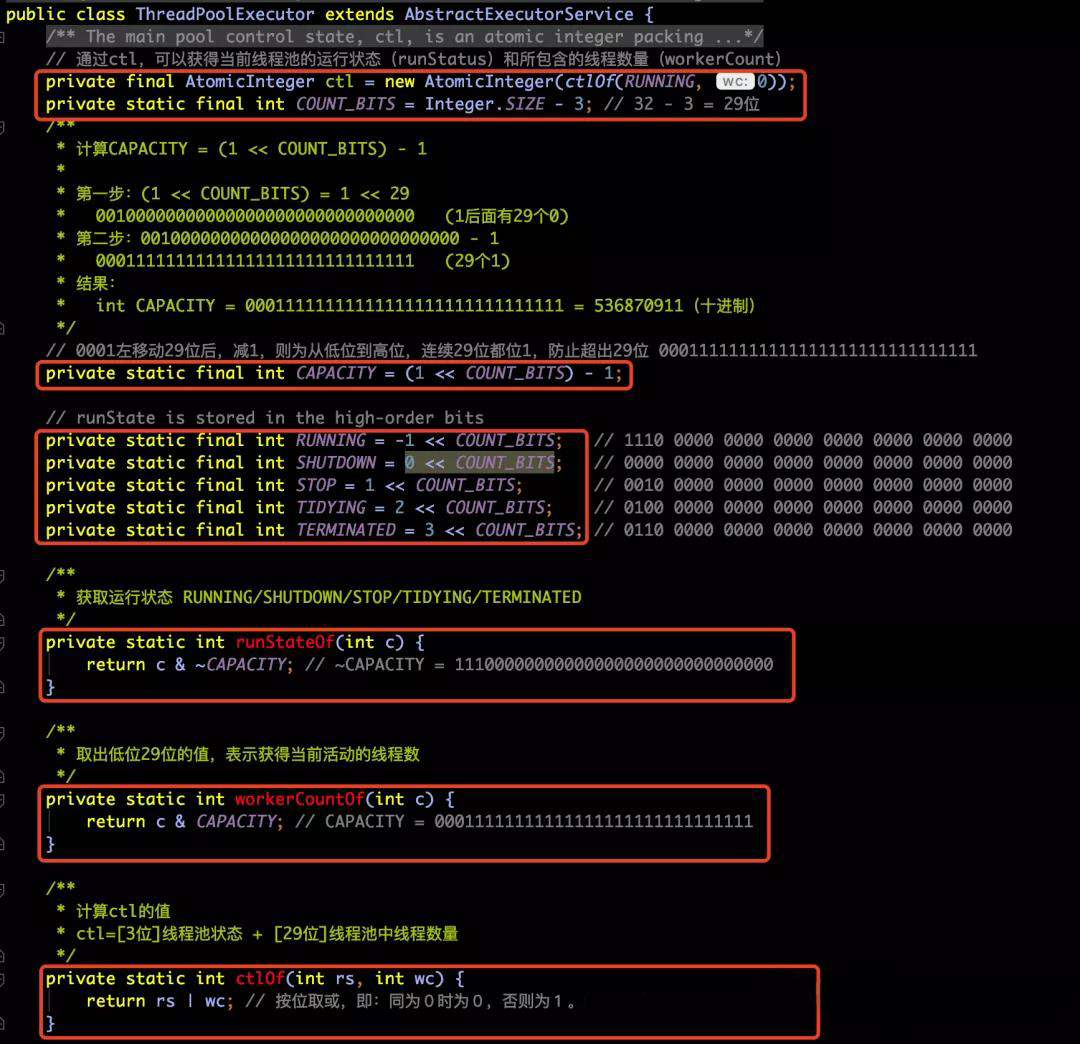
-
针对ctl的值,其实是两部分组成的:【高3位】表示:线程池状态 + 【低29位】表示:线程池中线程数量,如下图所示:

-
【上图解释如下】
-
上图中的runState:-1、0、1、2、3,其实是针对于红色3位来计算的,其实应该是32位来计算,这么写是为了方便大家直观感受到这5种状态值的大小。
其实如果按照32位来计算的哈,从小到大状态的排序依然是:RUNNING<SHUTDOWN<STOP<TIDYING<TERMINATED,后面对于多种状态的判断也是通过大小来判断的。 -
CAPACITY=(1<<COUNT_BITS)-1的计算方式如下所示:

-
针对ctl.get()获得的int值,其中有3个重要方法,如下所示:
-
int runStateOf(int c)
获取运行状态
RUNNING/SHUTDOWN/STOP/TIDYING/TERMINATED。

-
int workerCountOf(int c)
取出低位29位的值,表示获得当前活动的线程数。

-
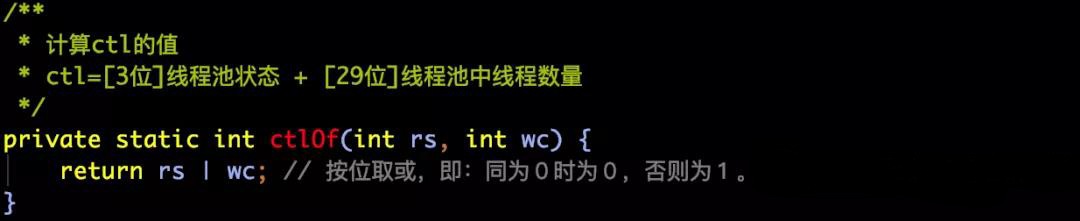
int ctlOf(int rs, int wc)
计算ctl的值,ctl=[3位]线程池状态 + [29位]线程池中线程数量。
3.3、线程池中的线程数量小于核心线程数代码逻辑
-
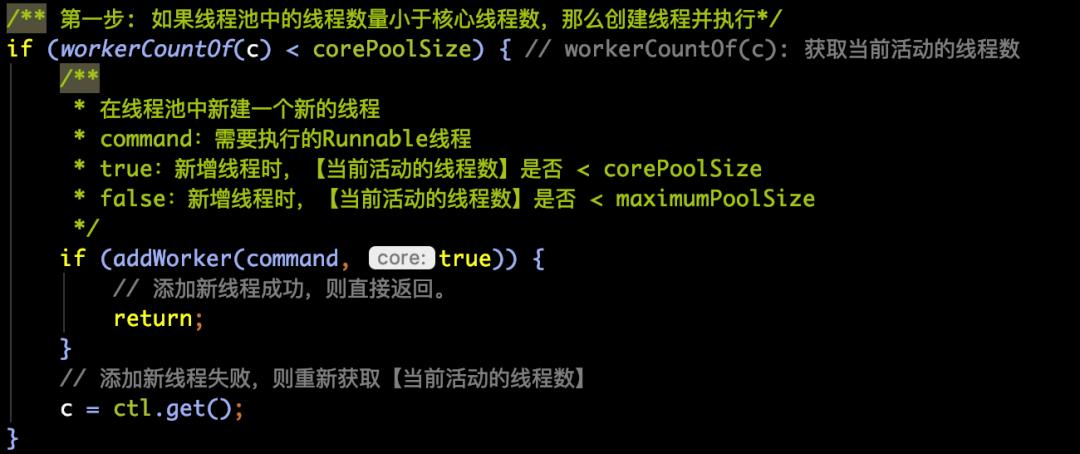
源码部分如下所示:
-
【上图解释如下】
-
其中的workerCountOf©用来获得当前线程池中的线程数,
-
如果小于核心线程数,则直接调用addWorker方法来向线程池中创建线程。
-
如果添加成功,则直接return返回。
-
如果添加失败了,则重新通过ctl.get()获取最新的ctl值。用于下面逻辑的判断。
3.4、任务添加到队列的代码逻辑
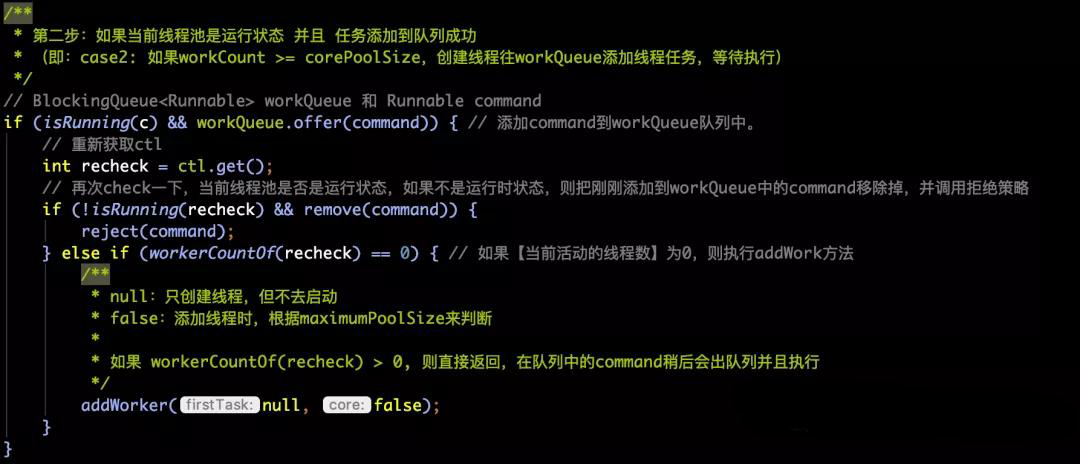
- 源码部分如下所示:
- 【上图解释如下】
- 通过isRunning方法来判断线程池状态是不是运行中状态,如果是,则将command任务放到阻塞队列workQueue中。
- 添加到阻塞队列成功后,还有一些后续操作。
比如:再次check一下,当前线程池是否是运行状态,如果不是运行时状态,则把刚刚添加到workQueue中的command移除掉,并调用拒绝策略。否则,判断如果当前活动的线程数如果为0,则表明只去创建线程,而此处,并不执行任务(因为,任务已经在上面的offer方法中被添加到了workQueue中了,等待线程池中的线程去消费队列中的任务)
3.5、 线程池中的线程数量小于最大线程数代码逻辑以及拒绝策略的代码逻辑
- 源码部分如下所示:

- 【上图解释如下】
- 由于调用addWorker的第二个参数是false,则表示对比的是最大线程数,那么如果往线程池中创建线程依然失败,即addWorker返回false,那么则进入if语句中,直接调用reject方法调用拒绝策略了。
四、 源码解析——addWorker(Runnable firstTask, boolean core)
- 看完execute方法的源码解析,我们发现,代码里的逻辑判断就是我们在【1.2、线程池工作流程】中讲解的那样。但是,这只是第一层代码的解析,关键的逻辑,其实都在第二层addWork代码中。下面我们就来解开addWorker的真面目。
4.1、 流程概述
-
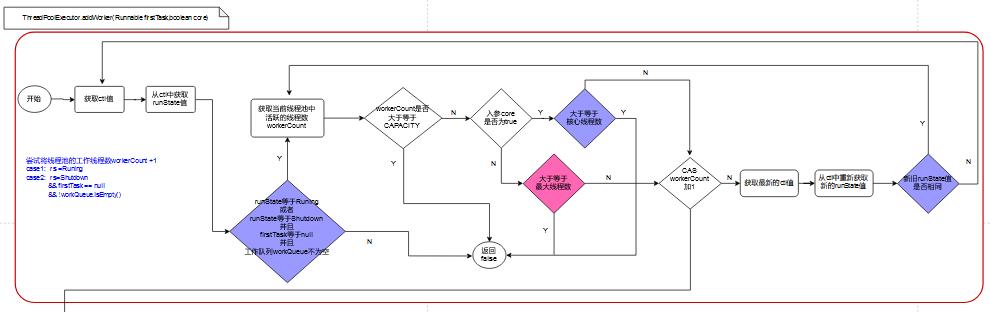
addWorkder的流程图如下所示:

-
【上图解释如下】
-
关于流程图中的绿色方块,我们会在后面的章节中展开介绍。
-
addWorkder的整个流程,其实可以分为两部分:
(第一部分:上图中红色框部分):试图将workerCount+1。
(第二部分:上图中蓝色框部分):workerCount成功+1后,创建Worker(也是一个Runnable),加入集合workers中,并启动Worker线程。
4.2、 retry
- 当我们打开addWorker方法的代码是,首先看到的就是retry:

- 其中,retry: 的用法 如下所示:

4.3、 addWorkder的第一部分解析
-
我们先看一下第一部分的源码和注释:
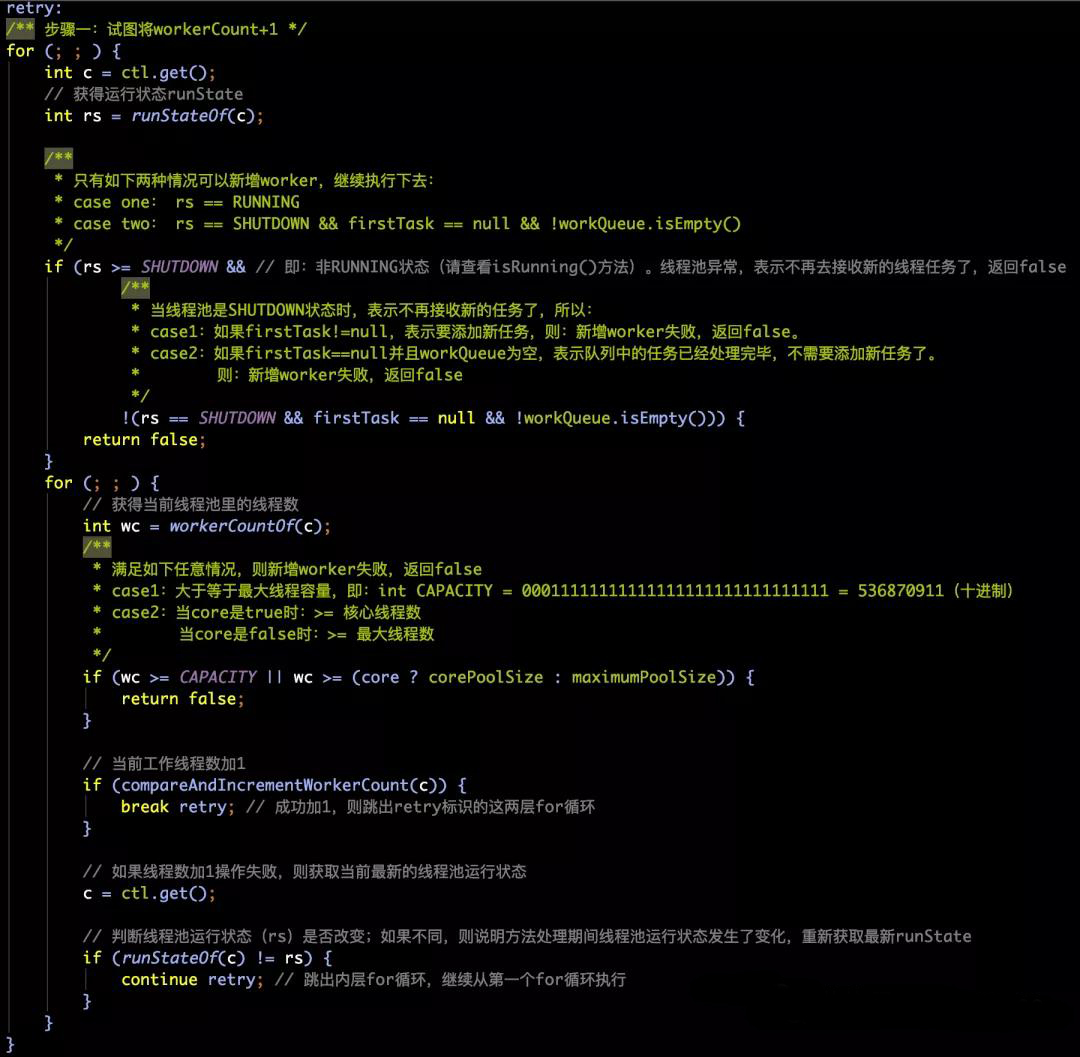
-
在第一部分中,首先还是从类型为AtomicInteger的ctl中获得最新值,然后调用runStateOf来获得当前线程池的运行状态。
-
下面的if判断,这块我们其实需要以相反的判断去思考——也就是,如果if中的判断是false,那么就不用return false而可以继续往下执行了。那么,什么情况下,程序可以继续往下执行呢?
if (rs >= SHUTDOWN && !(rs == SHUTDOWN && firstTask == null && !workQueue.isEmpty()))(1)、case1:如果线程池的状态时运行中(RUNNING),就可以继续往下执行了。
(2)、case2:如果线程池的状态时关闭(SHUTDOWN)并且firstTask=null并且阻塞队列workQueue中存在没有执行完毕的任务,那么就可以继续往下执行了。
(3)、也就是说,只有这两个情况,才不会直接返回false。还有继续往下执行的“机会”。 -
代码在往下,就是一个无限的循环了,在循环里我们发现,如果线程池中的线程数等于或者超过了最大线程数量(CAPACITY),或者已经等于或者超越了核心线程数(corePoolSize)/最大线程数(maximumPoolSize),那么就会直接返回false,没有“机会”继续下去了。而具体是对比corePoolSize还是maximumPoolSize,是根据我们addWorker方法第二个入参boolean core来决定的。
-
跳过这层阻碍,我们就要真正的去给当前的工作线程数加1了。这次依然采用的是CAS的方式去加1。如果加一成功,则Part1执行完毕,跳出循环,开始Part2的旅程。如果加一不成功,说明与其他线程操作冲突了,那么会重新获取最新的ctl值,再次循环执行上面的步骤。
4.4、 addWorkder的第二部分解析
-
我们先看一下第二部分的源码和注释:

-
在第二部分的逻辑中,我们就真正的开始了线程池的操作了。这部分才是主要部分。我们来往下看。
-
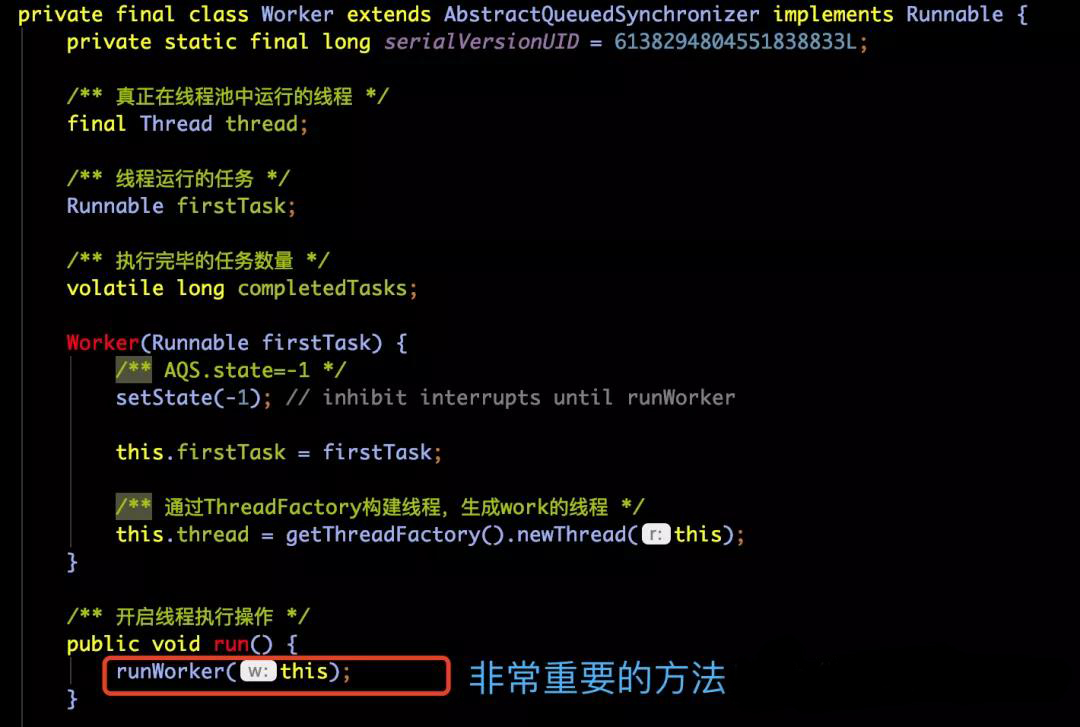
首先,我们new了一个Worker。Worker是什么东西呢?顾名思义,它是一个工人,一个线程池中负责给我们工作的工人,我们来看一下它的具体实现把:

-
【上图解释如下】
-
Worker是ThreadPoolExecutor的一个内部类,它虽然看着小,但是“五脏俱全”。
-
首先:变量thread,它就是我们线程池中运行的那个线程。它被包含在了Worker中。
-
其次:getThreadFactory()方法,其实就是我们线程池构造方法中的那个入参ThreadFactory,它就是用来创建线程用的。
-
之后:非常关键的一个方法,runWorker,线程池中关于线程复用的精华都在这个方法里了。
-
其中,runWorker方法我们暂时先不深入进去,后面会介绍,我们还是回到第二部分,先一层一层的了解代码的实现逻辑,以免调用代码调用的“深渊”中。
-
我们继续第二部分,创建了Worker后,从Worker中获取线程t,如果线程t不为空的话,我们就去尝试加锁了,如果可以成功的获得锁,就可以向线程池(其实就是HashSet workers)中添加线程了,不过在这之前,还需要任意的满足以下两个条件:
(1)、case1:线程池状态为RUNNING。
(2)、case2:线程池状态为SHUTDOWN并且firstTask为null。(什么是firstTask为null?其实就是单纯的创建线程,而不用附带执行firstTask的任务) -
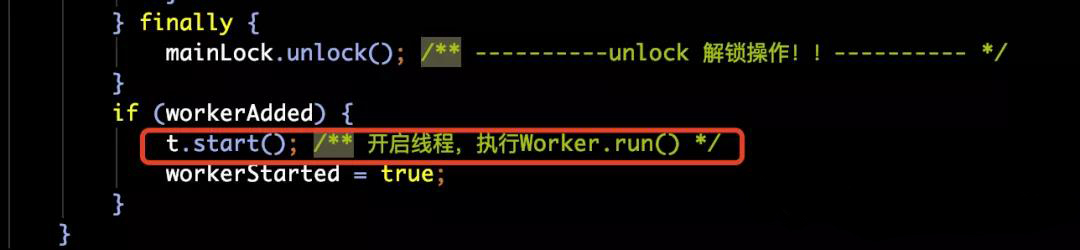
这一切执行完毕之后,在finally中调用了mainLock.unlock(),解开了锁。并且执行了t.start(),由于Worker是Runnable,所以,调用的其实就是Worker的run方法,而Worker的run方法里,调用了非常重要的那个方法——runWorker(this);
五、源码解析—— runWorker(Worker w)
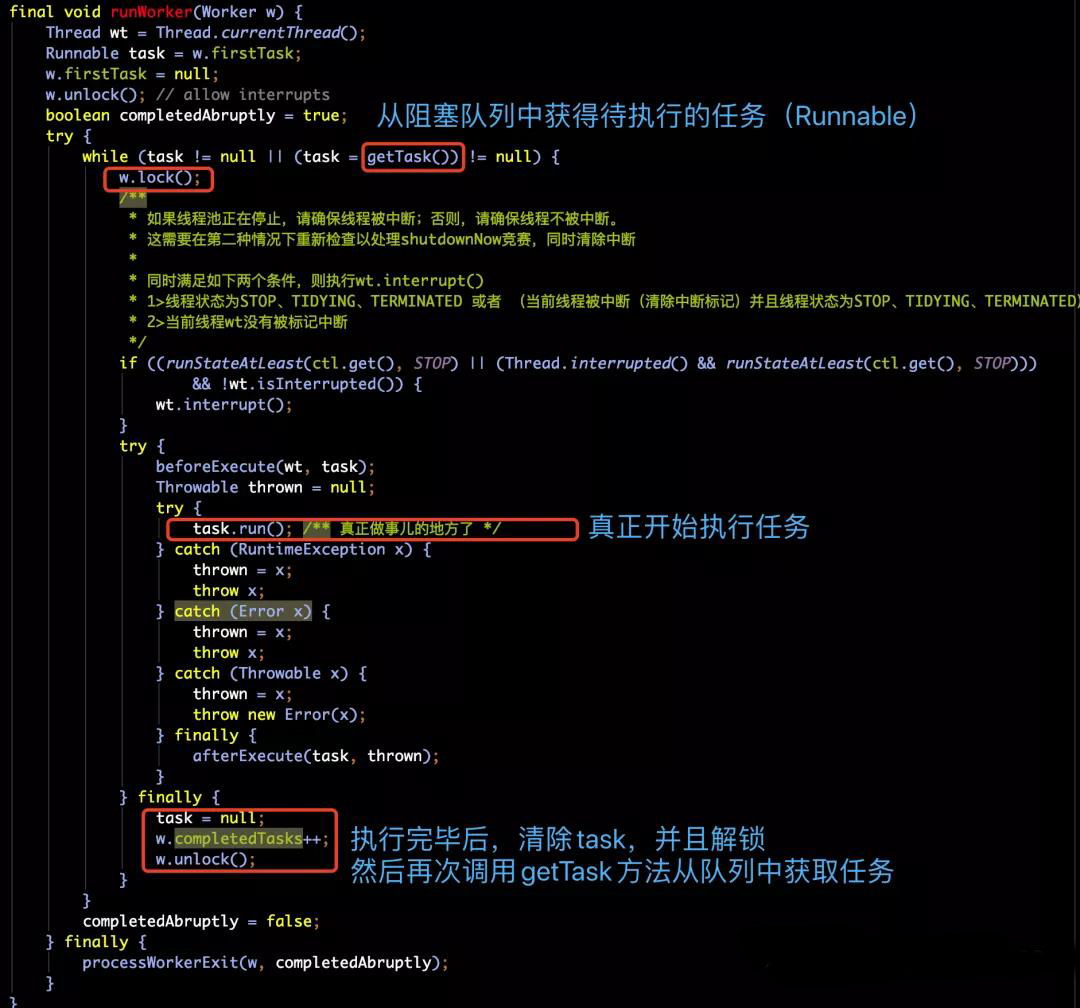
- 上面的逻辑中,我们的流程走到了runWorker方法中,那么现在,我们就来解开它的面纱。下面为方法的源码和注释:
- 【上图解释如下】
- 从runWorker的代码逻辑中,我们能够看出来,它的主要处理逻辑就是执行外部指定的firstTask或者从阻塞队列中获得待执行的任务,然后调用run方法进行执行。
- 同时也与Spring类似,提供了beforeExecute和afterExecute的前置和后置的处理。默认都是空的方法,如果我们需要,可以对其进行继承实现。
- 那这个时候,就会有同学有疑问了,在介绍线程池构造方法入参的时候,不是有两个参数,是用来控制线程最大空闲时间的吗(keepAliveTime和unit),也就是说,超过这个时间,线程就消亡了。那么,怎么在源码中没有发现在哪呢?其实,他们都在获取队列中的任务getTask()方法中呢。我们下面将会对这个方法进行解析。
六、源码解析—— getTask()
- getTask的方法的源码和注释:
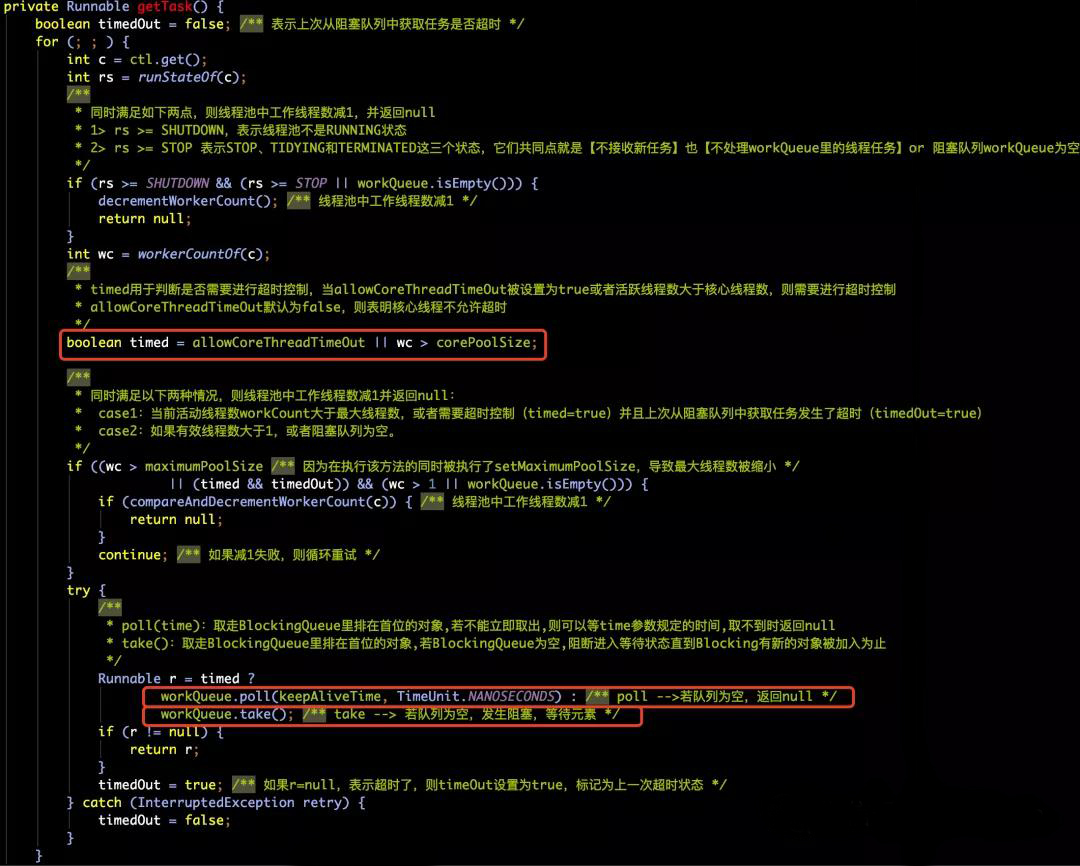
- 【上图解释如下】
- 在第二个红框处,我们就找到了keepAliveTime的身影,那这是会有同学问,为什么用的是TimeUnit.NANOSECONDS啊?构造函数的入参里不是有unit可以指定吗?难道没有生效吗?其实不是这样的。而是在构造函数中,已经提前把keepAliveTime统一转换为纳秒为单位了。如下所示:

七、源码解析—— reject(Runnable command)
- 最后关于拒绝策略这块,其实没什么好说了,最终调用的就是handler的rejectedExecution方法。
- 而RejectedExecutionHandler handler的四个实现类,就如截图所示:

- 到此,线程池的源码解析也就告一段落了。
以上是关于线程池(ThreadPoolExecutor)源码解析的主要内容,如果未能解决你的问题,请参考以下文章