MIT哈佛新研究:借助光场实现3D场景超高速渲染
Posted 人工智能博士
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MIT哈佛新研究:借助光场实现3D场景超高速渲染相关的知识,希望对你有一定的参考价值。
点上方人工智能算法与Python大数据获取更多干货
在右上方 ··· 设为星标 ★,第一时间获取资源
仅做学术分享,如有侵权,联系删除
转载于 :机器之心
光场不是第一次被提出,但这是第一次充分利用其优势。
对人类来说,观看单个二维图像并理解它捕获的完整三维场景是一件容易的事,但对于 AI 智能体来说则不然。现实生活中,一台需要与物体进行交互的机器(比如一个收割庄稼或协助手术的机器人)必须能够从的 2D 图像的观察中推断出 3D 场景的属性。
虽然科学家们已经成功地使用神经网络从图像中推断出 3D 场景的表征,但这些机器学习方法的速度还不够快,无法适用于许多现实世界的应用。
在一篇 NeurIPS 2021 论文中,来自哈佛大学、麻省理工学院的研究人员提出了一种新方法,使从图像中表征 3D 场景比已有模型约快 15000 倍。

论文地址:https://arxiv.org/abs/2106.02634
该研究提出的光场网络 (LFN) 可以在仅对图像进行一次观看后重建光场,并且能够以实时帧率渲染 3D 场景。
「这些神经场景表征的巨大前景是用于视觉任务。给你一张图像,然后从该图像中创建场景的表征,你想推理的一切都可以在那个 3D 场景的空间中进行,」MIT CSAIL 博士后、论文的共同主要作者 Vincent Sitzmann 说道。
方法概览
在计算机视觉和计算机图形学中,从图像中渲染 3D 场景涉及到映射数千或数百万的相机光线。其中,将相机光线想象为从相机镜头射出并照射图像中每个像素的激光束,每个像素一束光线。而计算机模型必须确定每条相机光线照射出的像素的颜色。
此前的方法是在每条相机光线于空间中移动时,沿每条相机光线的长度采集数百个样本来实现这一点,这是一个计算成本很高的过程,可能会导致渲染缓慢。
而该研究提出的 LFN 方法能够学习表征 3D 场景的光场,然后将光场中的每条相机光线直接映射到该光线观察到的颜色。LFN 利用光场的独特属性,只需一次评估即可渲染光线,因此 LFN 无需沿着光线的长度来运行计算。
Sitzmann 说:「使用其他方法进行渲染时,你必须一直跟随光线直到找到表面。你必须做数千个样本,因为这就是寻找表面的过程,甚至可能完不成,因为可能有复杂的东西,比如透明度或反射。而对于光场而言,一旦重建了光场,渲染单条光线就只需要表征的单个样本,因为表征会直接将光线映射成它的颜色。」
LFN 使用其「Plücker 坐标」对每条相机光线进行分类,该坐标能够基于方向和距离原点的距离表征 3D 空间中的一条线。系统会在光线照射像素的点处,计算每条相机光线的 Plücker 坐标。
通过使用 Plücker 坐标映射每条光线,LFN 还能够计算由于视差效应而产生的场景几何形状。视差是指从两条不同的视线观看时物体的表观位置差异。例如,如果您移动头部,距离较远的物体似乎比较近的物体移动得少。基于视差,LFN 可以判断场景中物体的深度,并使用此信息对场景的几何形状及其外观进行编码。
但是要重建光场,神经网络必须首先了解光场的结构,因此研究人员用许多简单的汽车和椅子场景图像训练模型。
光场有一个内在的几何形状,这正是该模型试图学习的。尽管汽车和椅子的光场似乎是不同的,以至于模型无法了解它们之间的某些共性。但事实证明,如果添加更多种类的物体,只要有一些同质性,模型就会越来越了解一般物体的光场的外观,因此你可以对更多类进行泛化。
一旦模型学习了光场的结构,它就可以仅将一张图像作为输入来渲染 3D 场景。
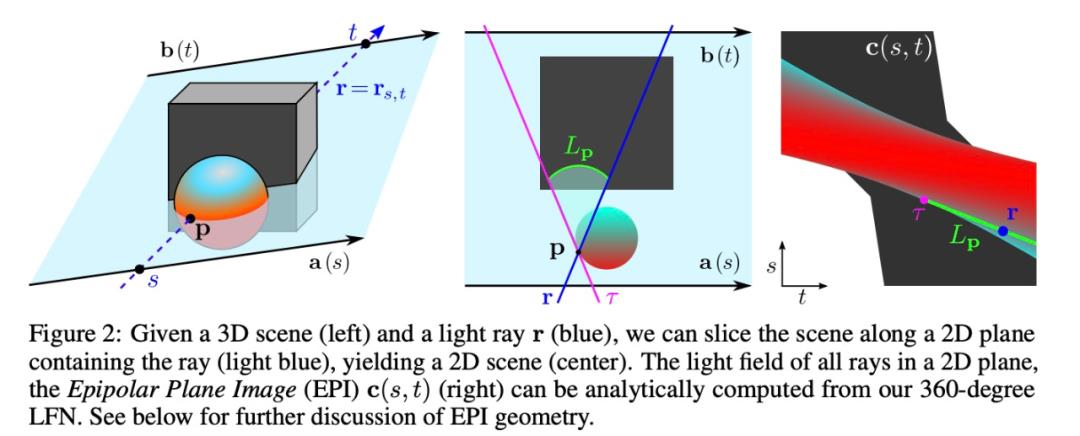
快速渲染
研究人员通过重建几个简单场景的 360 度光场来测试他们的模型。他们发现 LFN 能够以每秒 500 多帧的速度渲染场景,比其他方法快了大约 3 个数量级。此外,LFN 渲染的 3D 对象通常比其他模型生成的对象更清晰。
LFN 的内存密集程度也较低,仅需要大约 1.6 兆字节的存储空间,而基线方法则需要 146 兆字节的存储空间。
Sitzmann 说:「以前有人提出过光场,但却没有很好地利用。现在,我们提出的新方法首次表征了并使用了光场。这是数学模型和神经网络模型的有趣融合。」
实验结果
重建单个物体和房间规模的光场的外观和几何形状。该研究证明了 LFN 可以参数化单目标 ShapeNet [54] 和简单的 room-scale 环境 360 度光场。研究者在 ShapeNet「汽车」数据集上训练了 LFN,每个目标有 50 个观察值来自 [3],以及在 [13] 中的简单 room-scale 的环境。随后,研究中评估了 LFN 生成底层 3D 场景新视图的能力。结果见图 3:

多类别单视图重建
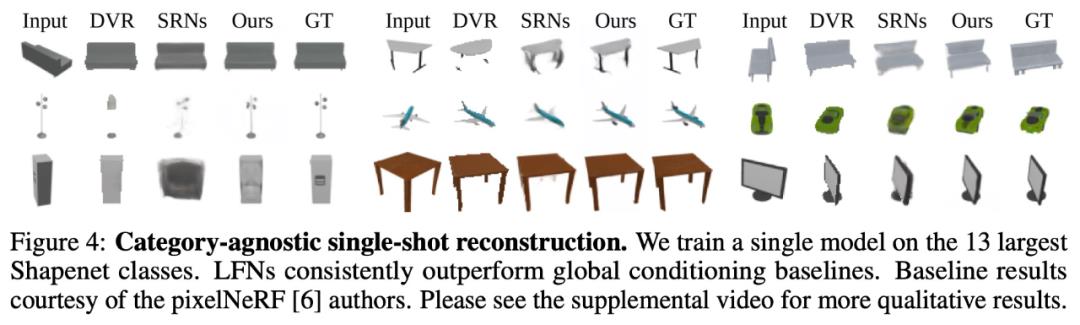
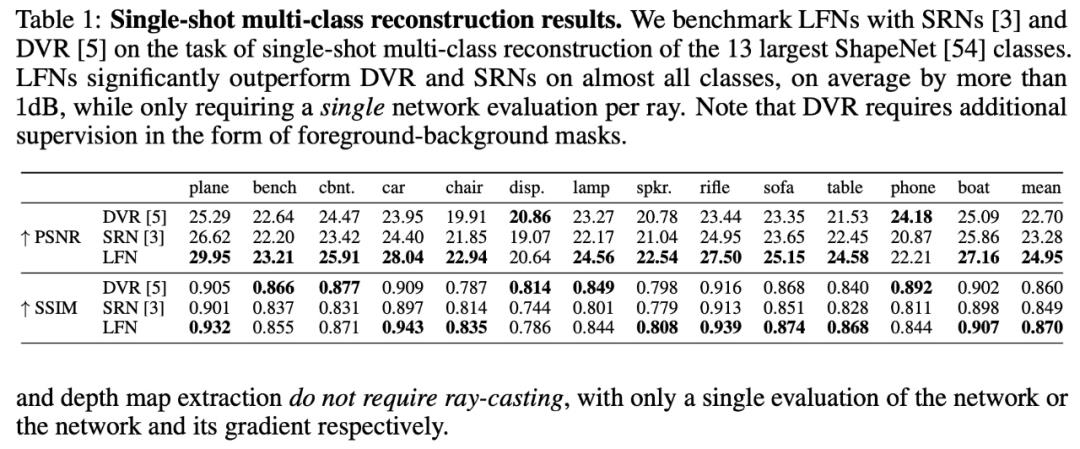
在 [5, 6] 之后,研究使用近期的全局调节方法对 LFN 进行基准测试,以完成 13 个最大 ShapeNet 类别的单视图重建和新视图合成任务。实验遵循与 [55] 相同的评估协议,并在所有类别中训练单个模型(参见图 4 和表 1)。
特定于类的单视图重建
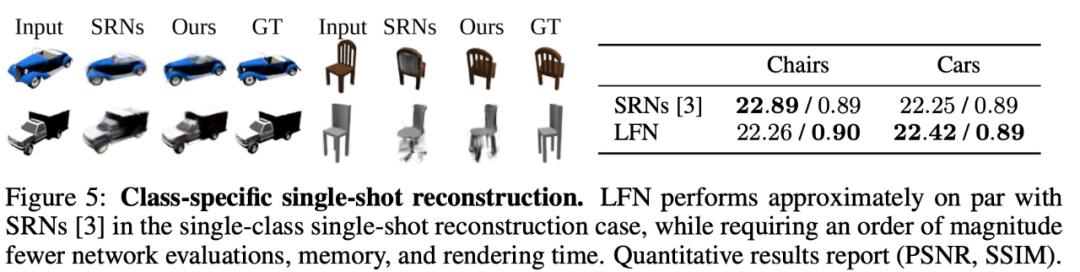
随后,研究者在 SRN [3] 中提出的 Shapenet「汽车」和「椅子」类的单次重建上对 LFN 进行基准测试,结果如下图 5 所示。
与 pixelNeRF 进行全局与局部条件对比
研究者观察了全局条件的作用,即用单个 latent 描述整个场景 [3],以及局部条件的作用,即用 latents 在 2D 图像中根据像素推断并利用局部调节神经隐式表征 [24,25,6]。总体而言,LFN 在单类情况下的性能比 pixelNeRF 相差 1dB,在多类设置中比 pixelNeRF 相差 2dB。

实时渲染和存储成本
LFN 与基于体积和光线行进的神经渲染器 [3, 42, 19, 4, 6] 在渲染复杂度上的定量比较结果如下表 2 所示。

研究者表示,未来该模型将更加稳健,以便可以有效地用于复杂的现实世界场景。Sitzmann 表示:「推动 LFN 向前发展的一种方法是只专注于重建光场的某些补丁,这可以使模型在现实环境中运行得更快并表现得更好。」
参考链接:
https://news.mit.edu/2021/3-d-image-rendering-1207
---------♥---------
声明:本内容来源网络,版权属于原作者
图片来源网络,不代表本公众号立场。如有侵权,联系删除
AI博士私人微信,还有少量空位


点个在看支持一下吧

以上是关于MIT哈佛新研究:借助光场实现3D场景超高速渲染的主要内容,如果未能解决你的问题,请参考以下文章