分布式数据库TiDB在携程的实践
Posted 过往记忆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式数据库TiDB在携程的实践相关的知识,希望对你有一定的参考价值。
作者简介
Army,携程数据库专家,主要负责分布式数据库运维及研究。
Keira,资深数据库工程师,主要负责mysql和TiDB运维。
Rongjun,携程大数据架构开发,专注离线和实时大数据产品和技术。
前言
携程自2014年左右开始全面使用MySQL数据库,随着业务增长、数据量激增,单机实例逐渐出现瓶颈,如单表行数过大导致历史数据查询耗时升高,单库容量过大导致磁盘空间不足等。为应对这些问题,我们采取了诸多措施如分库分表的水平拆分、一主多从读写分离、硬件SSD升级、增加前端Redis缓存等,但同时也使得整个业务层架构更加复杂,且无法做到透明的弹性,因此开始将目光转移到分布式数据库以解决这些痛点。
近年来受到Spanner&F1的启发,基于CAP理论和Paxos、Raft协议作为工程实现的分布式数据库得到了蓬勃发展,从硅谷的CockroachDB到国产的TiDB都在社区产生了很强的影响力。携程也对这些产品从社区活跃度、用户规模、易用性等多个方面做了调研,最终选择了国产的TiDB。
TiDB是一个开源的NewSQL数据库,支持混合事务和分析处理(HTAP)工作负载,兼容大部分MySQL语法,并且提供水平可扩展性、强一致性和高可用性。主要由PingCAP公司开发和支持,并在Apache 2.0下授权。2018年11月我们开始TiDB的POC以及与携程现有运维平台的整合,2019年1月第一个线上应用正式接入,最初的目标只是保证数据库的可用性以及可以存储足够多的关系型数据。随着TiDB快速迭代,越来越多的功能进入社区,如HATP特性,让我们不局限于最初的目标,开始了新的探索。本文将介绍TiDB在携程业务场景中的运维实践,希望对读者有所帮助和参考。
一、架构
携程内部历时1年,代号为“流浪地球”的机房级故障演练,验证了IDC级别故障容灾能力。我们将TiDB的三个副本分布在三个数据中心,保证在单中心故障时不影响对外服务,同时数据一致性也不受影响,并在tidb-server层实现了自动探活以及自动故障切换,让RPO等于0,RTO小于30S。
我们先来了解一下TiDB的整体架构(如图1-1),再结合携程的场景来部署。

图1-1 TiDB的整体架构图
从TiDB的架构图我们可以看到,得益于组件 PD 和 TiKV 都通过 Raft 实现了数据的容灾,原生就提供了多IDC的部署能力,和 Google Spanner 采用原子钟方案不同的是,TiDB 采用了 PD 进行单点全局统一授时的 Timestamp方案。TiDB 中的每个事务都需要向 PD leader 获取 TSO,当 TiDB 与 PD leader 不在同一个数据中心时,它上面运行的事务也会因此受网络延迟影响。目前携程的跨 IDC 延迟在 0.5-2ms之间 ,属于可接受的延迟范围。配置三数据中心时,需要对相应的TiKV和PD的label配置规则,这样PD在调度region副本时会根据标签属性在每一个机房都拥有一份全量数据。具体的一个配置示例,如图1-2:
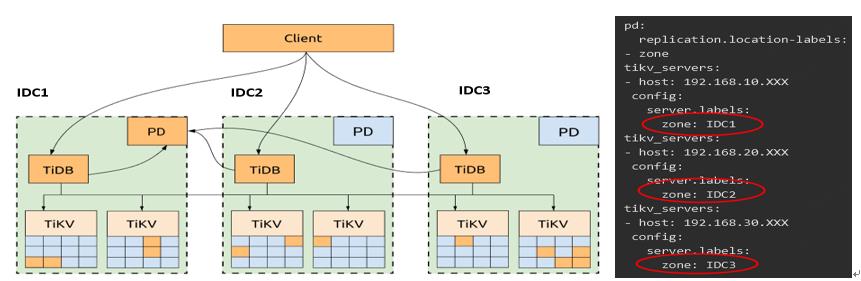
图1-2 TiDB在携程的部署架构和配置
这种部署架构的优点:
所有数据的副本分布在三个数据中心,具备IDC级别的高可用和容灾能力
任何一个数据中心失效后,不会产生任何数据丢失 (RPO = 0)
任何一个数据中心失效后,其他两个数据中心会自动发起 leader election,并在合理长的时间内(通常情况 20s 以内)自动恢复服务
二、应用场景
TiDB目前已经应用到携程的多个业务场景,包括风控、社区、营销、搜索、酒店等。这里选取两个比较典型的使用案例——国际业务CDP平台和酒店结算业务。
2.1 国际业务CDP平台
因为Trip数据来源比较广泛,既有自身数据也有外部数据;数据形式也非常多样化,既有结构化数据,也有半结构化和非结构化数据;数据加工形式既有离线数据处理,也有在线数据处理,因此国际业务构建了CDP平台以解决加工这些数据,形成业务系统、运营、市场需要并且可以理解的数据和标签,具体可以阅读往期文章:《携程国际业务动态实时标签处理平台实践》。
TiDB在其中主要承担存储业务持久化的标签以及内部SOA调用的查询服务。查询分为UID等维度的基础信息查询、订单订阅基础信息查询的OLTP,以及EDM\\Marketing等人群的OLAP查询。整个CDP平台的架构如图2-1:

图2-1 CDP平台架构图
具体的数据处理,历史全量数据通过数据批处理引擎(如Spark)转换完成以后批量写入到数据持久化存储引擎(TiDB),增量数据业务应用以消息的形式发送到Kafka或者QMQ消息队列,通过实时DAG处理完后持久化到存储引擎(TiDB)。
持久标签访问的主要场景有两个,一种是跟现有CRM系统对接,在线根据业务的特征圈选符合条件的业务数据,这种场景的查询条件不固定,返回结果集因筛选条件而定,对于数据存储引擎的数据计算和处理能力要求比较高,即我们在数据处理领域经常提到的OLAP的场景。另一种场景是线上业务根据前端传入的业务标签相关的唯一标识来查询是否满足特定业务要求,或者返回指定特征值,满足业务处理的需要,需要毫秒级响应,对应的是OLTP场景。
由于标签的多样性,有查询记录的字段多达60个,查询条件是60个字段的随机组合,无法通过传统数据库层的Index来提高查询效率,经典的方案是OLTP和OLAP分离,但数据会存储多份,多数据源的数据一致性是一个很大的挑战。
对于这种场景,我们开启了TiDB的TiFlash,TiFlash 是 TiDB HTAP 形态的关键组件,它是 TiKV 的列存扩展,在提供了良好的隔离性的同时,也兼顾了强一致性。列存副本通过 Raft Learner 协议异步复制,但是在读取的时候通过 Raft 校对索引配合 MVCC 的方式获得 Snapshot Isolation 的一致性隔离级别。TiFlash MPP模式如图2-2。

图2-2 TiDB MPP模式
这种架构很好地解决了 HTAP 场景的隔离性以及列存同步的问题,开启之后几个典型查询性能提升:
TiFlash MPP提升,20s -> 1s
Set @@session.tidb_allow_mpp=1;
Set @@session.tidb_enforce_mpp=0;

TiFlash 列裁剪,16.9s -> 2.8s
Set @@session.tidb_allow_mpp=1;
Set @@session.tidb_enforce_mpp=0;
Set session tidb_isolation_read_engines =’tidb,tiFlash’;

2.2 酒店结算业务
携程酒店结算业务全库6T,单服务器存储6T全量数据有很大挑战。常规的方法是用分库分表的方式来减少实例数据量及压力,但分库分表的维度很难确定,无论从酒店维度还是供应商维度都无法避免跨片的查询,给程序的开发带来了很大的困难,并且大部分查询都是聚合运算,因此我们尝试迁移到TiDB。
目前最大的表存储了28亿条数据,读写已完全切换到TiDB。具体所使用的部署模式和上节提到的国际业务CDP平台类似,同样是开启了TiDB的TiFlash来加速查询的性能,具体的性能如图2-3:

图2-3 酒店结算性能监控
三、一些问题的实践
3.1 参数不合理导致的性能问题
分布式数据库有别于传统单机,通常MySQL遇到性能问题时可以快速定位是由于网络抖动、SQL缺失索引还是请求次数激增等原因导致的,但分布式的TiDB组件众多,各个组件之间的网络通信、某个组件资源不足、SQL复杂等都可能是导致出现性能问题的原因。目前官方提供了问题导图,方便根据不同的场景尽快定位原因。这里给出一个具体的案例,总结了一个典型问题的排查思路。
国际业务集群使用官方默认配置的集群上线测试时,发现写入耗时高达秒级,且耗时波动较大。来自应用端的监控(纵坐标单位为毫秒),如图3-1:

图3-1 IBA写入响应监控
根据Pingcap的导图发现scheduler command duration的时间约等于事务的prewrite时间(纵坐标单位为秒),可以看出scheduler-worker不足。如图3-2:
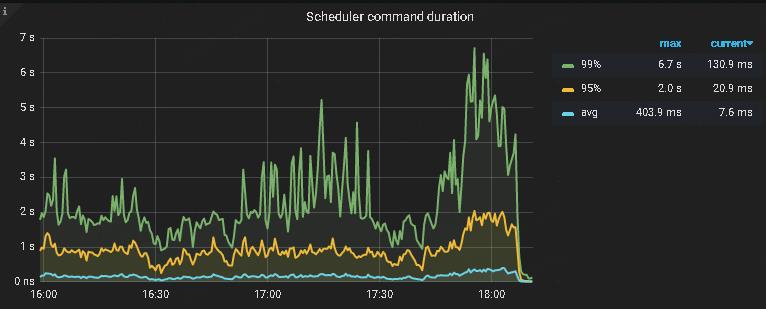
图3-2 scheduler command duration的时间
所以我们做了如下的调整:
scheduler-worker-pool-size:16 --> 40 (默认值为4,最小值为1,最大不能超过TiKV节点的CPU核数)
scheduler-pending-write-threshold: "100MB" --> 1024MB (写入数据队列的最大值,超过该值之后对于新的写入 TiKV 会返回 Server Is Busy 错误)
调整完成后来自应用端的监控(纵坐标单位为毫秒),如图3-3,红色箭头处是参数调整的时间点:

图3-3 IBA写入响应监控
总结:默认配置并非最佳配置,需要根据服务器硬件、使用场景不断调试并最终固化为每个集群甚至所有集群的最佳实践配置;根据PingCAP提供的问题导图,逐步定位具体哪个组件哪个方面存在瓶颈,我们同时也在进一步开发一键定位工具,能更快速的定位性能瓶颈。
3.2 分布式带来的自增列问题
含自增列的表,在自增列不强制赋值的情况下,insert语句报主键冲突:
报错SQL:INSERT INTO `xxx_table ` (`id, `name`, `tag`, `comment`, `creator`) VALUES (?, ?, ?, ?, ?)
报错内容:com.mysql.jdbc.exceptions.jdbc4.MySQLIntegrityConstraintViolationException: Duplicate entry 175190 for key 'PRIMARY'.
在PingCAP官方文档上,有以下介绍:
TiDB 中,自增列只保证自增且唯一,并不保证连续分配。TiDB 目前采用批量分配 ID 的方式,所以如果在多台 TiDB 上同时插入数据,分配的自增 ID 会不连续。TiDB 实现自增 ID 的原理是每个 tidb-server 实例缓存一段 ID 值用于分配(目前会缓存 30000 个 ID),用完这段值再去取下一段。假设集群中有两个 tidb-server 实例 A 和 B(A 缓存 [1,30000] 的自增 ID,B 缓存 [30001,60000] 的自增 ID),依次执行如下操作:客户端向 B 插入一条将 id 设置为 1 的语句 insert into t values (1, 1),并执行成功。客户端向 A 发送 Insert 语句 insert into t (c) (1),这条语句中没有指定 id 的值,所以会由 A 分配,当前 A 缓存了 [1, 30000] 这段 ID,所以会分配 1 为自增 ID 的值,并把本地计数器加 1。而此时数据库中已经存在 id 为 1 的数据,最终返回 Duplicated Error 错误。
通过这段介绍,我们了解到造成自增主键冲突,是因为存在自增主键显式插入导致。
结论:分布式数据库对于表自增列是预分配的,自增主键显式插入会导致tidb-server上的计数器混乱,引起数据写入报错。在开发规范中,我们明确要求TiDB不允许自增主键显式插入。
3.3 修改字段是否为空导致默认值异常
如下的表,我们字段从int升级到bigint
CREATE TABLE `test` (`id` int);
alter table `test` add `col1` int(11) null default '0';
alter table `test` add `col2` int(11) null default '0';
alter table `test` change `col1` `col1` bigint(20) null default '0';
alter table `test` change `col2` `col2` bigint(20) null default '0';
我们发现默认值0不合适,因此,执行下面的语句,把默认值调整为null
alter table `test` change `col1` `col1` bigint(20) null ;
alter table `test` change `col2` `col2` bigint(20) null';
此时,我们插入一条数据:insert into test(id) values(1);
神奇的发现,col1和col2的值依旧是0. 这和我们的预期不符。经过一系列重现测试,以及社区论坛的查找,我们发现这个问题是一个已知问题。https://github.com/pingcap/tidb/pull/20491. 该Bug在TiDB 4.0.9及以后版本已修复。
结论:成熟的社区论坛是TiDB日常运维和快速排障的利器,借助社区论坛上各种技术探索和交流分享,可以汲取优质内容,收获前沿知识,快速定位和解决问题。
四、监控与告警
对于分布式数据库运维,监控和告警是非常核心的一环,冒烟现象或者不规范现象,需要及时发现,及时解决,避免问题恶化。监控准确、告警及时可以帮助运维人员准确定位问题,快速解决故障。TiDB 使用开源时序数据库 Prometheus 作为监控和性能指标信息存储方案,使用 Grafana 作为可视化组件进行展示,我们在此基础上进一步做了整合。
4.1 TiDB监控大盘
TiDB原生提供prometheus+Grafana的性能大盘,数据非常丰富,但数据分散在单独的集群,无法提供全局视角,我们通过prometheus源生remote write到9201端口,自研了一个adaptor监听9201端口,转发性能数据到携程统一监控平台,搭建了我们自己的监控大盘。如图4-1:

图4-1 整合后的TiDB监控大盘
4.2 三副本监控
TiDB使用三个以上的副本,通过raft协议来保证数据的一致性。当出现多数副本丢失或者宕机时,这部分数据处于不可用状态,是否存在副本缺失或者副本状态异常是需要特别注意的。因此我们会针对副本的数目及状态进行巡检,确保不会出现长时间内副本不足的情况,一旦发现有副本丢失,可以增加副本的调度线程,务必及时解决副本缺失问题。Region Peer的监控如图4-2:
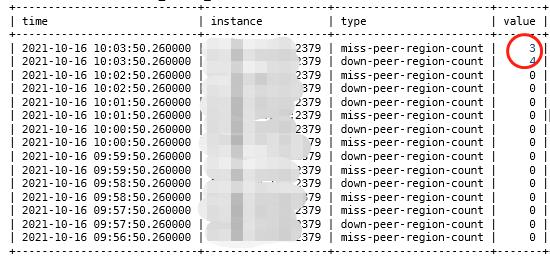
图4-2 三副本监控
4.3 磁盘容量监控
TiDB存储数据量庞大,需要特别关注机器磁盘剩余可使用空间的情况,以免写满磁盘造成不必要的故障。对于磁盘的监控,我们的阈值是物理磁盘的80%,一旦磁盘使用容量超过阈值,我们需要安排加机器扩容。对比相同情况下MySQL复杂的拆分方法,TiDB的处理方法更简单高效。磁盘的监控告警如图4-3:

图4-3 TiDB磁盘监控
4.4 配置标准化检查
TiDB集群的配置文件参数、系统参数众多,不同实例的配置项各不相同,且经常会对集群扩容缩容,因此我们要求变更前后集群的配置必须严格按照标准配置进行调整。只要做到配置标准,很大程度上就会保证集群标准化运行。配置标准化的监控告警如图4-4:

图4-4 配置标准化的监控告警
4.5 性能告警
有时候会存在突发的流量上升,或者瞬间的性能尖峰的情况,这时候就需要关注性能告警。METRICS_SCHEMA 是基于 Prometheus 中 TiDB 监控指标的一组视图,有了基础的性能数据,我们只需要根据性能阈值,及时告警,及时分析处理。
五、周边工具
除了监控与告警,我们也开发了一系列周边工具,对于TiDB的运维,带来了更大的便利。这些周边工具主要包括:
5.1 和现有的数据周边工具打通
现有的数据周边工具主要包括:数据库的发布(DDL),数据在线查询,数据在线修改,以及和现有的大数据流程打通等,这些支持MySQL的工具也一样可以支持TiDB,为MySQL迁移TiDB打解决了后顾之忧,让之前使用MySQL的开发测试人员可以方便流畅地切换到TiDB。
5.2 TiDB部署工具
TiDB集群实例角色较多,集群部署有别于传统单机,需要单独开发一套部署工具,包括集群上线流程、集群下线流程、扩容缩容实例、集群版本升级等。
5.3 TiDB闪回工具
有时候会遇到开发测试人员误操作数据的情况,可以使用数据闪回工具进行回退,我们借助TiDB binlog开发了闪回工具,对binlog的内容做反转,生成数据恢复SQL,供 TiDB数据恢复使用。
六、未来规划
6.1 故障的一键分析
分布式数据库与单机不同, TiDB组件比较多,可供调整的参数有数百个,各个组件之间的网络通信、某个组件资源不足、SQL复杂等都可能导致出现性能问题,后续计划将TiDB诊断做成自动化和智能化,目前已经通过改造TiDB server源码,完成了TiDB的全链路SQL收集和分析,这将作为未来故障一键分析的基础。
6.2 基于HDD硬盘测试
TiDB 所有的优化都是基于SSD来做的,高性能意味着高成本。我们还是会面临数据量比较大,但写入和查询都比较少,响应要求不高的场景。我们目前已经完成基于HDD硬盘的测试,选择的机器配置为12块10T HDD硬盘,单机部署12个TiKV实例,这种架构已经在小范围应用。
6.3 同城双中心自适应同步方案DR Auto-Sync
DR Auto-Sync 正处在高速迭代的周期中,后续版本将会有一系列高可用和容灾能力的加强。从 5.3.0 开始将支持双中心对等部署,藉此获得快速恢复多副本的能力,我们也在保持关注中。

以上是关于分布式数据库TiDB在携程的实践的主要内容,如果未能解决你的问题,请参考以下文章