HBase ImportTSV工具使用
Posted 赵广陆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase ImportTSV工具使用相关的知识,希望对你有一定的参考价值。
1 ImportTSV功能描述
将tsv(也可以是csv,每行数据中各个字段使用分隔符分割)格式文本数据,加载到HBase表中。
1)、采用Put方式加载导入
2)、采用BulkLoad方式批量加载导入
使用如下命令,查看HBase官方自带工具类使用说明:
HADOOP_HOME=/export/servers/hadoop
HBASE_HOME=/export/servers/hbase
HADOOP_CLASSPATH=`$HBASE_HOME/bin/hbase mapredcp`:$HBASE_HOME/conf
$HADOOP_HOME/bin/yarn jar $HBASE_HOME/lib/hbase-server-1.2.0-
cdh5.14.0.jar
执行上述命令提示如下信息:
An example program must be given as the first argument.
Valid program names are:
CellCounter: Count cells in HBase table.
WALPlayer: Replay WAL files.
completebulkload: Complete a bulk data load.
copytable: Export a table from local cluster to peer cluster.
export: Write table data to HDFS.
exportsnapshot: Export the specific snapshot to a given FileSystem.
import: Import data written by Export.
importtsv: Import data in TSV format.
rowcounter: Count rows in HBase table.
verifyrep: Compare the data from tables in two different clusters.
翻译:
一个示例程序必须作为第一个参数给出。
有效的程序名是:
CellCounter: HBase表的cell数。
WALPlayer:重放WAL文件。
completebulkload:完成批量数据加载。
copytable:从本地集群导出表到对端集群。
export:将表数据写入HDFS。
exportsnapshot:将特定的快照导出到给定的文件系统。
import:导入Export写入的数据。
importtsv:导入TSV格式的数据。
rowcounter: HBase表的行数。
verifyrep:比较来自两个不同集群中的表的数据。
其中 importtsv 就是将文本文件(比如CSV、TSV等格式)数据导入HBase表工具类,使用
说明如下:
Usage: importtsv -Dimporttsv.columns=a,b,c <tablename> <inputdir>
The column names of the TSV data must be specified using the -
Dimporttsv.columns
option. This option takes the form of comma-separated column names, where
each
column name is either a simple column family, or a columnfamily:qualifier.
The special column name HBASE_ROW_KEY is used to designate that this column
should be used as the row key for each imported record.
To instead generate HFiles of data to prepare for a bulk data load, pass
the option:
-Dimporttsv.bulk.output=/path/for/output
'-Dimporttsv.separator=|' - eg separate on pipes instead of tabs
For performance consider the following options:
-Dmapreduce.map.speculative=false
-Dmapreduce.reduce.speculative=false
翻译:
用法:importtsv -Dimporttsv。 列= a, b, c <表> < inputdir >之类 TSV数据的列名必须使用-指定 Dimporttsv.columns 选择。 该选项采用逗号分隔的列名形式,其中 每一个 列名可以是一个简单的列族,也可以是一个列族:限定符。 特殊的列名HBASE_ROW_KEY用于指定该列 应该用作每个导入记录的行键。 要代替生成数据的HFiles来准备批量数据加载,请通过选择:
-Dimporttsv.bulk.output=/path/for/output
'-Dimporttsv.separator=|' - eg separate on pipes instead of tabs
For performance consider the following options:
-Dmapreduce.map.speculative=false
-Dmapreduce.reduce.speculative=false
2 直接导入Put方式
HADOOP_HOME=/export/servers/hadoop
HBASE_HOME=/export/servers/hbase
HADOOP_CLASSPATH=`$HBASE_HOME/bin/hbase mapredcp`:$HBASE_HOME/conf
$HADOOP_HOME/bin/yarn jar $HBASE_HOME/lib/hbase-server-1.2.0-
cdh5.14.0.jar \\
importtsv \\
-
Dimporttsv.columns=HBASE_ROW_KEY,detail:log_id,detail:remote_ip,detail:s
ite_global_ticket,detail:site_global_session,detail:global_user_id,detai
l:cookie_text,detail:user_agent,detail:ref_url,detail:loc_url,detail:log
_time \\
tbl_logs \\
/user/hive/warehouse/tags_dat.db/tbl_logs
上述命令本质上运行一个MapReduce应用程序,将文本文件中每行数据转换封装到Put
对象,然后插入到HBase表中。
回顾一下:
大数据Sqoop借助Hive将Mysql数据导入至Hbase
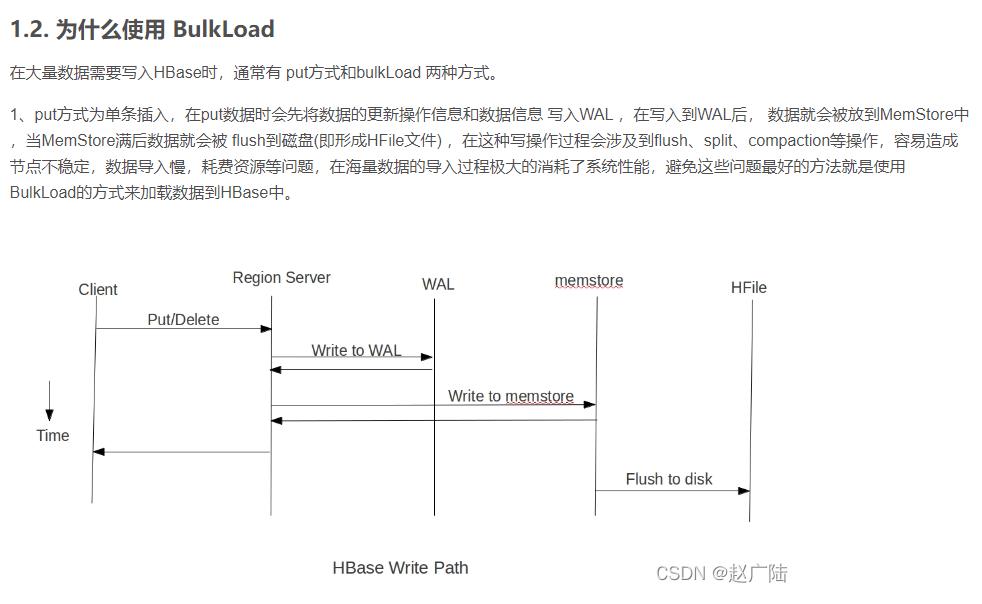
3 转换为HFile文件,再加载至表
# 1. 生成HFILES文件
HADOOP_HOME=/export/servers/hadoop
HBASE_HOME=/export/servers/hbase
HADOOP_CLASSPATH=`$HBASE_HOME/bin/hbase mapredcp`:$HBASE_HOME/conf
$HADOOP_HOME/bin/yarn jar $HBASE_HOME/lib/hbase-server-1.2.0-
cdh5.14.0.jar \\
importtsv \\
-Dimporttsv.bulk.output=hdfs://bigdata-
cdh01.itcast.cn:8020/datas/output_hfile/tbl_logs \\
-
Dimporttsv.columns=HBASE_ROW_KEY,detail:log_id,detail:remote_ip,detail:
site_global_ticket,detail:site_global_session,detail:global_user_id,det
ail:cookie_text,detail:user_agent,detail:ref_url,detail:loc_url,detail:
log_time \\
tbl_logs \\
/user/hive/warehouse/tags_dat.db/tbl_logs
# 2. 将HFILE文件加载到表中
HADOOP_CLASSPATH=`$HBASE_HOME/bin/hbase mapredcp`:$HBASE_HOME/conf
$HADOOP_HOME/bin/yarn jar $HBASE_HOME/lib/hbase-server-1.2.0-
cdh5.14.0.jar \\
completebulkload \\
hdfs://bigdata-cdh01.itcast.cn:8020/datas/output_hfile/tbl_logs \\
tbl_logs
缺点:
1)、ROWKEY不能是组合主键
只能是某一个字段
2)、当表中列很多时,书写-Dimporttsv.columns值时很麻烦,容易出错
总结:这个工具导入一些小批量数据还是很不错的,但是不常用.
以上是关于HBase ImportTSV工具使用的主要内容,如果未能解决你的问题,请参考以下文章