ZooKeeper中Master选举实现方式
Posted 泡^泡
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ZooKeeper中Master选举实现方式相关的知识,希望对你有一定的参考价值。
介绍
Master 选举在分布式系统中是比较常见的场景,在分布式架构下,为了实现服务的可用性,一般都会采用集群模式,就是当一个机器宕机以后,集群里的其他节点可以代替故障节点继续工作。像这种情况,就需要从集群中选举一个节点成为Master节点,剩余的节点作为备份节点待命。当原有的 Master 节点出现故障之后,还需要从集群中其他备份节点中选举一个节点作为 Master 节点继续提供服务。
Master选举方式
ZooKeeper 其实就可以帮助集群中节点实现 Master 选举。主要利用 ZooKeeper 的两大特性:
- 同一级节点不能重复创建一个已经存在的节点(同一目录下面,磁盘创建文件也不能重名),这个有点类似于分布式锁的实现场景,其实Master选举的场景也是如此。假设集群中有3个节点,需要选举出Master,那么这三个节点同时去 ZooKeeper 服务器上创建一个临时节点/master-election,由于节点的特性,只会有一个客户端创建成功,创建成功的客户端所在的机器就成了Master。同时,其他没有创建成功的客户端,针对该节点注册Watcher事件,用于监控当前的Master机器是否存活,一旦发现Master挂了,也就是/master-election节点被删除了,那么其他的客户端将会重新发起Master选举操作。
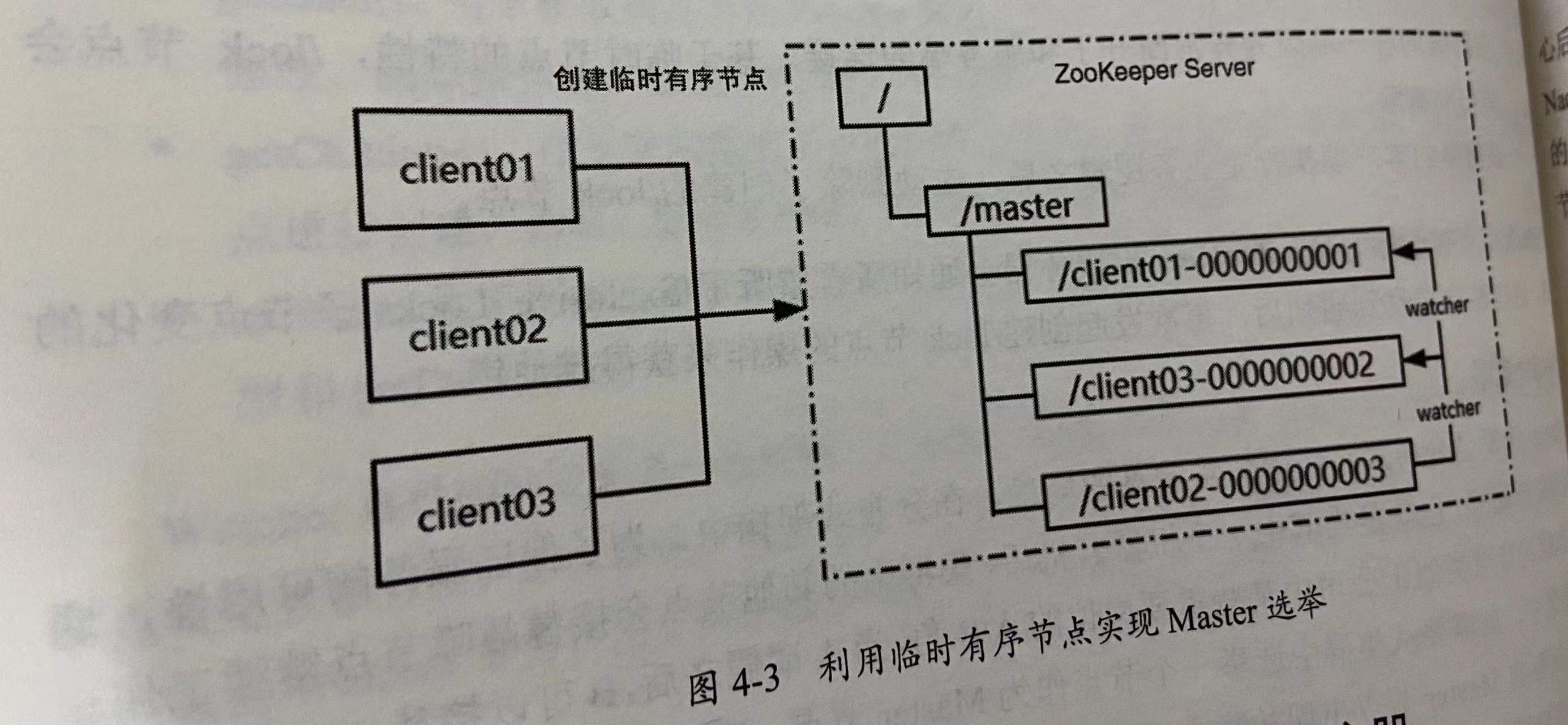
- 利用临时有序节点的特性来实现。所有参与选举的客户端在 ZooKeeper 服务器的/master节点下创建一个临时有序节点,编号最小的节点表示Master,后续的节点可以监听前一个节点的删除事件,用于触发重新选举,如图4-3所示,client01、client02、client03 三个节点去 ZooKeeper Server 的/master节点下创建临时有序节点,编号最小的节点 client01 表示Master节点,client02 和 client03 会分别通过 Watcher 机制监听比自己编号小的一个节点,比如 client03 会监听 client01-0000000001 节点的删除事件、client02 会监听 client03-0000000002 节点的删除事件,一旦最小的节点被删除,那么在图4-3这个场景中,client03就会被选举为Master。
以上是关于ZooKeeper中Master选举实现方式的主要内容,如果未能解决你的问题,请参考以下文章