恒源云_LLD: 内部数据指导的标签去噪方法ACL 2022
Posted AI酱油君
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了恒源云_LLD: 内部数据指导的标签去噪方法ACL 2022相关的知识,希望对你有一定的参考价值。
文章来源 | 恒源云社区(恒源云,专注 AI 行业的共享算力平台)
原文地址 | LLD: 内部数据指导的标签去噪方法
原文作者 | Mathor
大佬发文太勤快,再不搬运,我自己都不好意思了,所以今天给大家带来新的内容啦~
正文开始:
很多数据集中的标签都存在错误,即便它们是由人来标注的,错误标签的存在会给模型训练带来某些负面影响。目前缓解这种影响有诸如删除错误标签、降低其权重等方法。ACL2022有一篇名为《A Light Label Denoising Method with the Internal Data Guidance》的投稿提出了一种基于样本内部指导的方法解决这个问题
先前有研究表明同一类别的样本在本质上是相似和相关的,不同类别的样本存在明显差异。在文本分类任务中,两个有着相似内容的句子应该被预测为同一个类别,但是实际情况并不总是这样。当训练数据面临一定程度的噪声时,这个问题可能会更加严重,因为模型只收到标签的指导/监督。这就自然而然提出了一个问题:除了标签之外,我们能否从训练样本之间的关系寻求指导?
以文本分类数据为例,有
n
n
n个样本的数据集可以被定义为
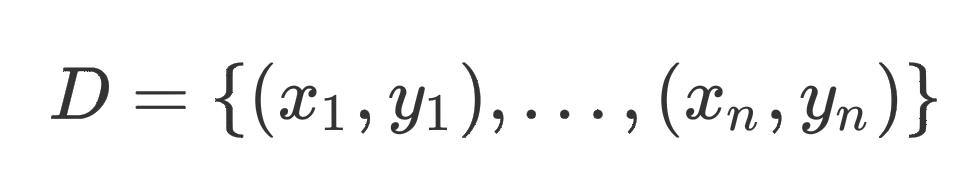
其中, y i ∈ c 1 , c 2 , … , c m y_i\\in c_1, c_2,…,c_m yi∈c1,c2,…,cm表示共有 m m m类
CONTEXTUAL REPRESENTATION
我们首先需要一个指标判断两个句子是否相似。目前有两大类文本相似度计算方法,第一种是基于传统的符号表征,例如编辑距离、Jaccard Similarity Coeffieient以及Earth Mover’s Distance;第二种是将文本映射为稠密的向量,然后计算它们的向量相似度。第一种方法过于依赖token的表面信息,第二种方法需要使用外部数据对模型进行预训练,而这个外部数据和我们的任务数据可能不是同一领域的。因此作者基于Postive Pointwise Mutual Information (PPMI)提出了一个新的上下文表征方法
首先,我们用一个长度为2的滑动窗口统计数据集中所有token的共现矩阵
C
C
C。
C
w
i
,
w
j
C_w_i, w_j
Cwi,wj表示前一个词是
w
i
w_i
wi ,后一个词是
w
j
w_j
wj出现的次数,然后我们计算
C
C
C的PPMI矩阵
E
E
E:
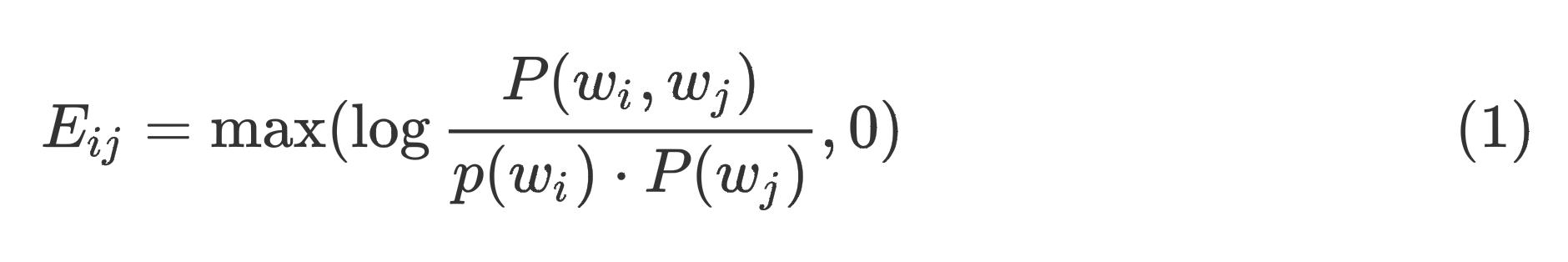
其中, P ( w i ) , P ( w j ) , P ( w i , w j ) P(w_i), P(w_j), P(w_i, w_j) P(wi),P(wj),P(wi,wj)分别是从共现矩阵 C C C中计算得到的。最终,向量 E w i E_w_i Ewi是词 w i w_i wi的表示
WORD WEIGHT
由于不同的词对于句子含义的贡献不同,我们更关注那些对分类更有帮助的词,而不是一些常见的词(例如a, the, of)。作者提出一个计算词
w
i
w_i
wi权重的算法:
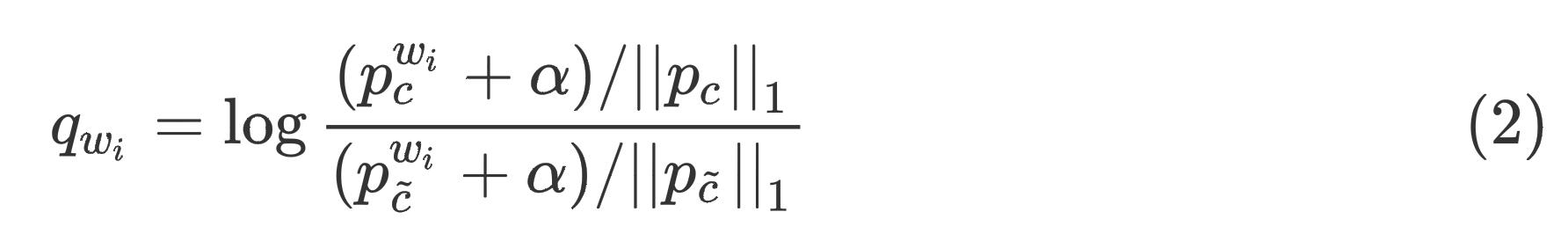
其中, c c c是词 w i w_i wi出现频率最高的类别, p c w i p_c^w_i pcwi是类别 c c c中单词 w i w_i wi的样本数, p c ~ w i p_\\tildec^w_i pc~wi是除了类别 c c c之外所有类别中单词 w i w_i wi的样本数, ∣ p c ∣ ∣ 1 |p_c||_1 ∣pc∣∣1是类别 c c c的样本数, α \\alpha α是一个小的平滑值(例如0.1)。
GUIDING THE TRAINING
给定包含
d
d
d个单词的句子
a
a
a,以及包含
e
e
e个单词的句子
b
b
b,它们的相似度为:
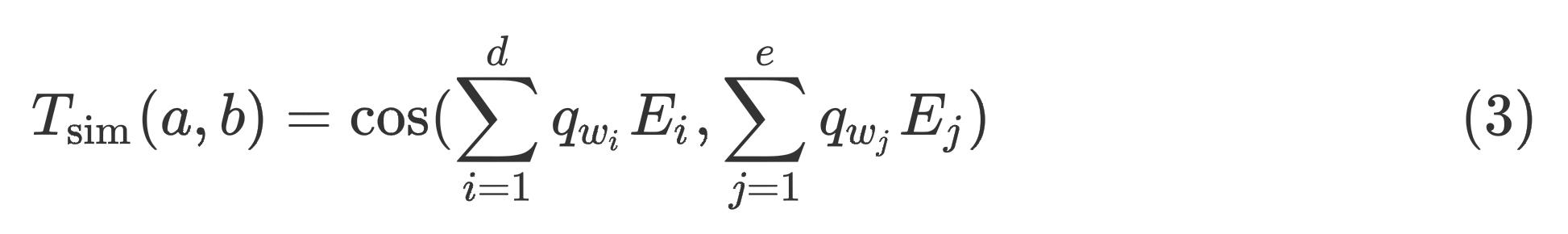
很明显,
T
sim
(
a
,
b
)
T_\\textsim(a,b)
Tsim(a,b)总是大于0的,因为
q
w
i
q_w_i
qwi一定大于等于0,向量
E
i
E_i
Ei中的元素根据计算公式也都是大于等于0的,
cos
(
A
,
B
)
\\cos(A,B)
cos(A,B)中,当向量
A
A
A和
B
B
B中的元素都大于等于0时,结果一定大于0
在含有
m
m
m个类别的文本分类任务中,模型对于第
i
i
i个样本的预测概率分布可以记为

其中,
l
i
k
l_ik
lik >
0
0
0并且
∑
k
=
1
m
l
i
k
=
1
\\sum_k=1^m l_ik=1
∑k=1mlik=1。因此模型对于样本
a
a
a和
b
b
b预测概率分布的相似度为

在训练过程中,损失函数定义为:

其中
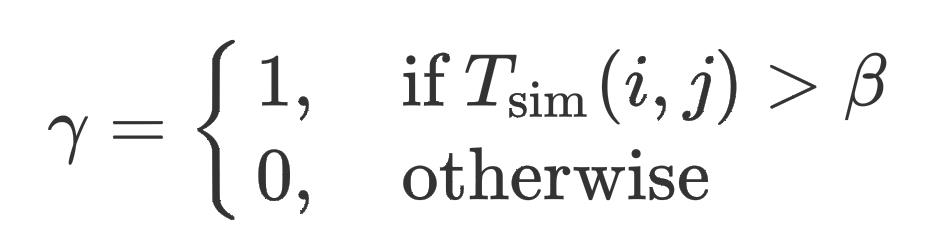
换言之,当两个句子的相似度大于阈值
β
\\beta
β时,我们就认为它们非常相似,那么它们的标签大概率应该是相同的,反映到预测概率分布上,它们预测概率分布向量的余弦相似度应该接近于1才对,如果单纯这么考虑的话,实际上我们有如下定义的损失函数
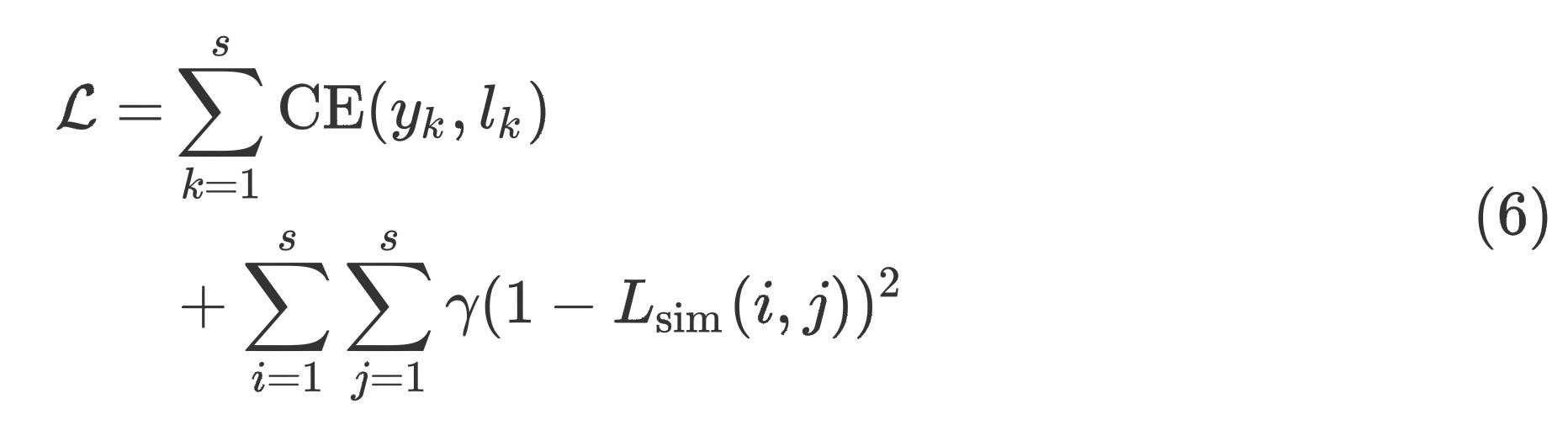
极端情况下,当 L sim ( i , j ) = 1 L_\\textsim(i,j)=1 Lsim(i,j)=1时,加法后面所带来的损失就为0了;当 L sim ( i , j ) = 0 L_\\textsim(i,j)=0 Lsim(i,j)=0时,后面是有损失的
RESULT
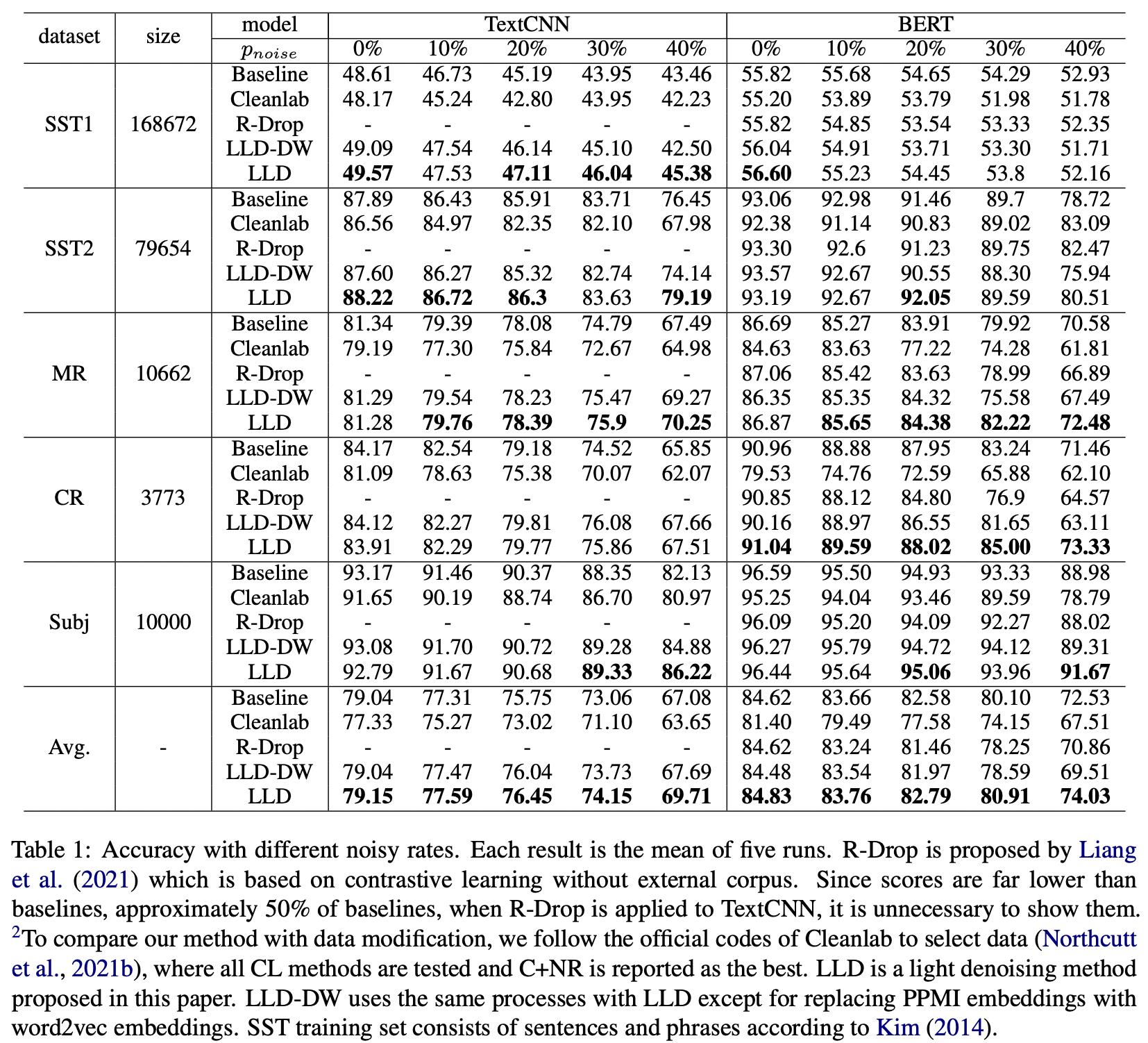
论文的实验阵容还算豪华,某种程度上来说让人比较意外的地方是这种简单修改损失函数的办法居然超过了R-Drop。其中LLD-DW将矩阵 E E E用Word2vec进行替换,其他步骤保持不变,结果发现用Word2vec反而没有作者提出的简单统计方法好
个人总结
这篇文章本质上来讲,可以看作是多目标联合训练,除了传统的分类任务,引入了一个新的任务,这个任务的目标是希望两个句子的相似度与它们预测概率分布的相似度比较接近。反映到损失函数中来看就是在传统损失的后面添加了一项。阅读完这篇论文之后,说实话我不太确定它能否被ACL录用
以上是关于恒源云_LLD: 内部数据指导的标签去噪方法ACL 2022的主要内容,如果未能解决你的问题,请参考以下文章
恒源云_Y-Tuning: 通过对标签表征进行微调的深度学习新范式ACL 2022
恒源云(Gpushare)_UNIRE:一种可以共享标签空间的方法