卷积自编码去噪(基于pytorch)
Posted 挂科难
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了卷积自编码去噪(基于pytorch)相关的知识,希望对你有一定的参考价值。
数据集
链接:https://pan.baidu.com/s/10hZI4a-8I9cNJWw_baCD1Q
提取码:yker
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from skimage.util import random_noise
from skimage.metrics import peak_signal_noise_ratio
import scipy.io as scio
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.data as Data
import torch.optim as optim
from torchvision import transforms
from torchvision.datasets import STL10
def read_image(data_path):
with open(data_path, 'rb') as f:
data1 = np.fromfile(f,dtype=np.uint8)
image = np.reshape(data1, (-1,3,96,96))
images = np.transpose(image,(0,3,2,1))
return images/255.0
def gaussian_noise(images, sigma):
sigma2 = sigma**2 / (255**2) #噪声方差
images_noisy = np.zeros_like(images)
for ii in range(images.shape[0]):
image = images[ii]
noise_im = random_noise(image,mode='gaussian',var=sigma2,clip=True)
images_noisy[ii] = noise_im
return images_noisy
data_path = r'G:\\data\\STL10\\stl10_binary\\train_X.bin'
images = read_image(data_path)
#print('image.shape', images.shape) #(5000,96,96,3)
images_noise = gaussian_noise(images, 30)
#显示原图
plt.figure(figsize=(6,6))
for ii in np.arange(36):
plt.subplot(6,6,ii+1)
plt.imshow(images[ii,...])
plt.axis('off')
plt.show()
#显示带噪声的
plt.figure(figsize=(6,6))
for ii in np.arange(36):
plt.subplot(6,6,ii+1)
plt.imshow(images_noise[ii,...])
plt.axis('off')
plt.show()
原图:

添加噪声:

训练保存模型
data_Y = np.transpose(images, (0, 3, 2, 1)) # 输出不带噪声
data_X = np.transpose(images_noise, (0, 3, 2, 1)) # 输入带噪声
X_train, X_val, y_train, y_val = train_test_split(data_X, data_Y,test_size=0.2,random_state=123)
#图像转为tensor
X_train = torch.tensor(X_train, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.float32)
X_val = torch.tensor(X_val, dtype=torch.float32)
y_val = torch.tensor(y_val, dtype=torch.float32)
train_data = Data.TensorDataset(X_train, y_train)
val_data = Data.TensorDataset(X_val, y_val)
print('X_train.shape:', X_train.shape)
print('y_train.shape:', y_train.shape)
print('X_val.shape:', X_val.shape)
print('y_val.shape:', y_val.shape)
train_loader = Data.DataLoader(
dataset=train_data,
batch_size=32,
shuffle=True,
num_workers=4
)
val_loader = Data.DataLoader(
dataset=val_data,
batch_size=32,
shuffle=True,
num_workers=4
)
class DenoiseAutoEncoder(nn.Module):
def __init__(self):
super(DenoiseAutoEncoder, self).__init__()
#Encoder
self.Encoder = nn.Sequential(
nn.Conv2d(3, 64, 3, 1, 1),
nn.ReLU(),
nn.BatchNorm2d(64),
nn.Conv2d(64, 64, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.BatchNorm2d(64),
nn.Conv2d(64, 128, 3, 1, 1),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.Conv2d(128, 128, 3, 1, 1),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.Conv2d(128, 256, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.BatchNorm2d(256),
)
#Decoder
self.Decoder = nn.Sequential(
nn.ConvTranspose2d(256, 128,3, 1, 1),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.ConvTranspose2d(128, 128, 3, 2, 1, 1),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.ConvTranspose2d(128, 64, 3, 1, 1),
nn.ReLU(),
nn.BatchNorm2d(64),
nn.ConvTranspose2d(64, 32, 3, 1, 1),
nn.ReLU(),
nn.BatchNorm2d(32),
nn.ConvTranspose2d(32, 32, 3, 1, 1),
nn.ConvTranspose2d(32, 16, 3,2, 1, 1),
nn.ReLU(),
nn.BatchNorm2d(16),
nn.ConvTranspose2d(16, 3, 3, 1, 1),
nn.Sigmoid(),
)
def forward(self, x):
encoder = self.Encoder(x)
decoder = self.Decoder(encoder)
return encoder,decoder
# train and save
DAEmodel = DenoiseAutoEncoder()
print(DAEmodel)
optimizer = optim.Adam(DAEmodel.parameters(),lr=0.0003)
loss_func = nn.MSELoss()
train_loss = []
val_loss = []
for epoch in range(10):
train_loss_epoch = 0
val_loss_epoch = 0
for step,(b_x,b_y) in enumerate(train_loader):
DAEmodel.train()
_, output = DAEmodel(b_x) # 加密,解密
loss = loss_func(output, b_y) # b_y 为不加噪声原图像
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss_epoch +=loss.item() * b_x.size(0)
train_loss.append(train_loss_epoch / len(train_data))
for step, (b_x,b_y) in enumerate(val_loader):
DAEmodel.eval()
_, output = DAEmodel(b_x) # 加密,解密
loss = loss_func(output, b_y)
val_loss_epoch += loss.item() * b_x.size(0)
val_loss.append(val_loss_epoch / len(val_data))
print('*************************************************','finished:',epoch+1)
print('train_loss:',train_loss)
print('val_loss:',val_loss)
torch.save(DAEmodel, 'DAEmodel.pth',_use_new_zipfile_serialization=False)
scio.savemat('train_loss.mat','train_loss': train_loss)
scio.savemat('val_loss.mat','val_loss': val_loss)
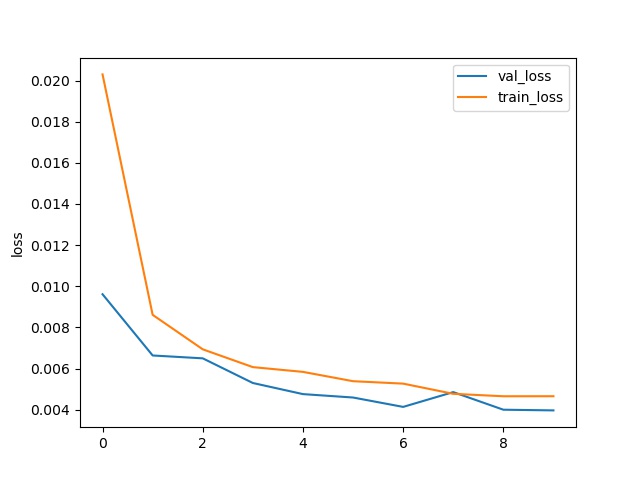
在该模型中,我们依然对比了Adam和SDG算法:
Adam:
SGD:
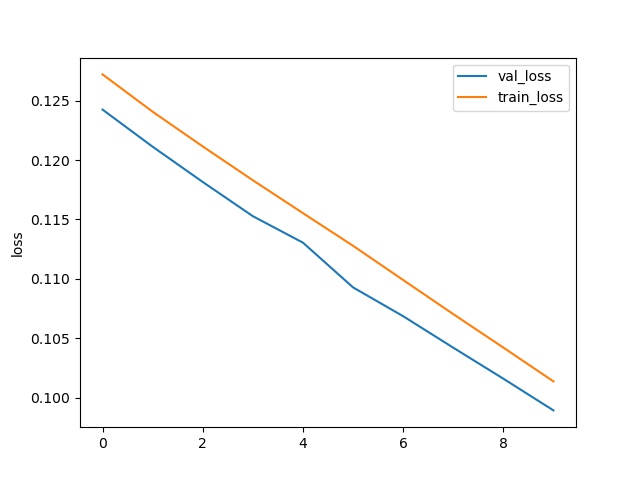
笔者认为在该模型中Adam优于SDG算法。因此选用了Adam算法的模型。
加载模型
DAEmodel = torch.load('DAEmodel.pth')
#带噪图
im = X_val[1, ...].unsqueeze(0)
imnose = np.transpose(im.data.numpy(), (0,3,2,1))[0,...]
#去噪
DAEmodel.eval()
_, output = DAEmodel(im)
imde = np.transpose(output.data.numpy(), (0,3,2,1))[0,...]
#原图
im = y_val[1, ...].unsqueeze(0)
imor = np.transpose(im.data.numpy(), (0,3,2,1))[0,...]
#计算PNSR
print('加噪后的PNSR:', peak_signal_noise_ratio(imor, imnose), 'dB')
print('去噪后的:', peak_signal_noise_ratio(imor, imde), 'dB')
plt.figure(figsize=(12, 4))
plt.subplot(1,3,1)
plt.imshow(imor)
plt.axis('off')
plt.title('Origin image')
plt.subplot(1,3,2)
plt.imshow(imnose)
plt.axis('off')
plt.title('noise image sigma=30')
plt.subplot(1,3,3)
plt.imshow(imde)
plt.axis('off')
plt.title('Denoise image')
plt.show()
图像如下:

在评价图像去噪效果时,我们使用PSNR(peak signal noise ration)峰值信噪比来评价,该值越大说明两个图像之间越相似。
峰值信噪比的计算
python中有自带库来计算两个图像的峰值信噪比。
from skimage.metrics import peak_signal_noise_ratio
假设两个图像(图像I与图像K)的长,宽均为 m, n,K(i,j)表示K图第i行第j列个像素,可算得其均方误差为:
均方误差(MSE)

求得均方误差后,其峰值信噪比为:
MAXI是表示图像点颜色的最大数值

计算PSNR提升量的均值
# 计算平均PNSR的提升
psnr_val = []
DAEmodel.eval()
for ii in range(X_val.shape[0]):
im = X_val[ii,...].unsqueeze(0) #X_val 带噪
imnose = np.transpose(im.data.numpy(), (0, 3, 2, 1))[0, ...]
#去噪
_, output = DAEmodel(im)
imde = np.transpose(output.data.numpy(), (0, 3, 2, 1))[0,...]
#输出
im = y_val[ii, ...]
imor = im.unsqueeze(0)
imor = np.transpose(imor.data.numpy(), (0, 3, 2, 1))
imor = imor[0,...]
psnr_val.append(peak_signal_noise_ratio(imor,imde) - peak_signal_noise_ratio(imor, imnose))
print('PSNR提升:',np.mean(psnr_val))

经过我们的卷积自编码去噪,平均每张图片的峰值信噪比提升了5.32dB
以上是关于卷积自编码去噪(基于pytorch)的主要内容,如果未能解决你的问题,请参考以下文章