Sqoop生产数据倾斜问题验证
Posted NC_NE
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Sqoop生产数据倾斜问题验证相关的知识,希望对你有一定的参考价值。
一、创建一张外部表
建表如下
create external table default.oyltest_manyMap_Sqoop
(
draw_id string,
third_user_id string,
login_name string,
user_id string,
activity_id string,
participate_times int,
is_realized string,
prize_type_info string,
useing_detail_id string,
draw_time string,
remark string,
status string,
is_valid string,
pk_serial string,
created_user string,
created_date string,
updated_user string,
updated_date string,
task_id string,
prize_sources string,
prize_relation_id string,
share_string string,
biz_type string,
biz_key string
)
location '/ori_warehouse/oylsqooptest/manyMap';二、直接使用string类型的主键作为切分字段
2.1、数据量是17069846
2.2、使用32个Map来并行执行
2.3、编写执行sqoop的shell脚本
#!/bin/bash
sqoop import "-Dorg.apache.sqoop.splitter.allow_text_splitter=true" \\
--connect jdbc:oracle:thin:@192.168.119.227:1521:odsdb \\
--username 123123 \\
--password 123123\\
--query 'select * from i_efsdata.efs_activity_draw where $CONDITIONS ' \\
--fields-terminated-by '\\001' \\
--hive-drop-import-delims \\
--target-dir /ori_warehouse/oylsqooptest/manyMap/ \\
--delete-target-dir \\
--null-string '\\\\N' \\
--null-non-string '\\\\N' \\
--split-by draw_id \\
-m 32 &> /opt/sqoop_test/logs/oyltest_manyMap_Sqoop.log参数-Dorg.apache.sqoop.splitter.allow_text_splitter=true的含义是允许文本类型(相当任意类型)的字段作为--split-by的参数
2.4、出现数据倾斜现象
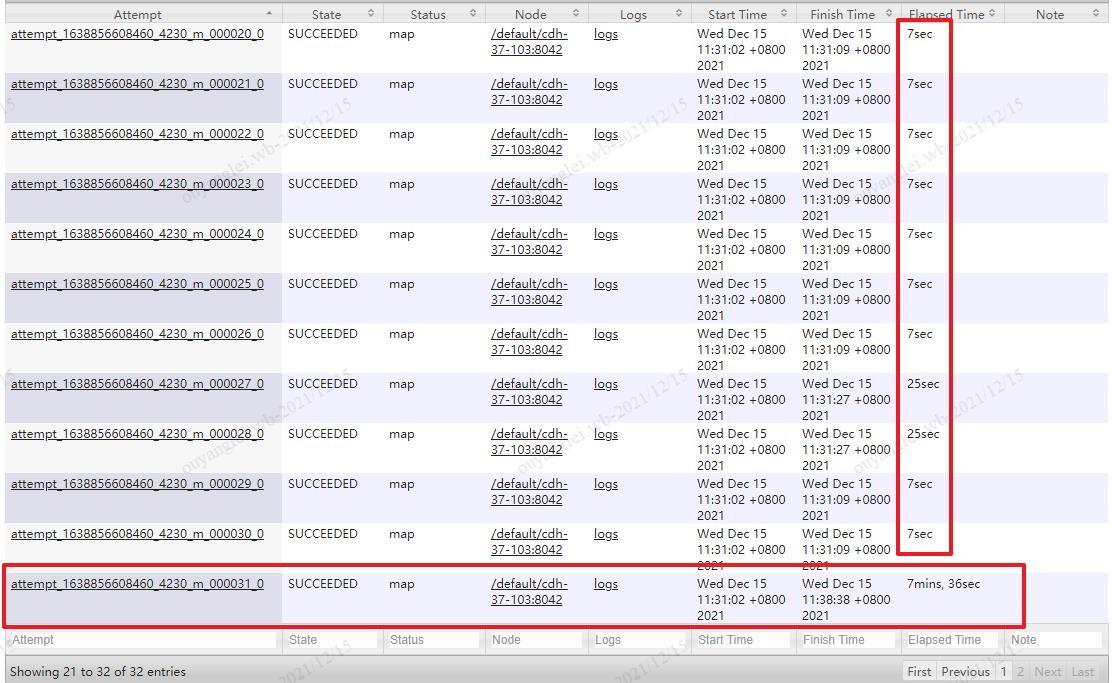
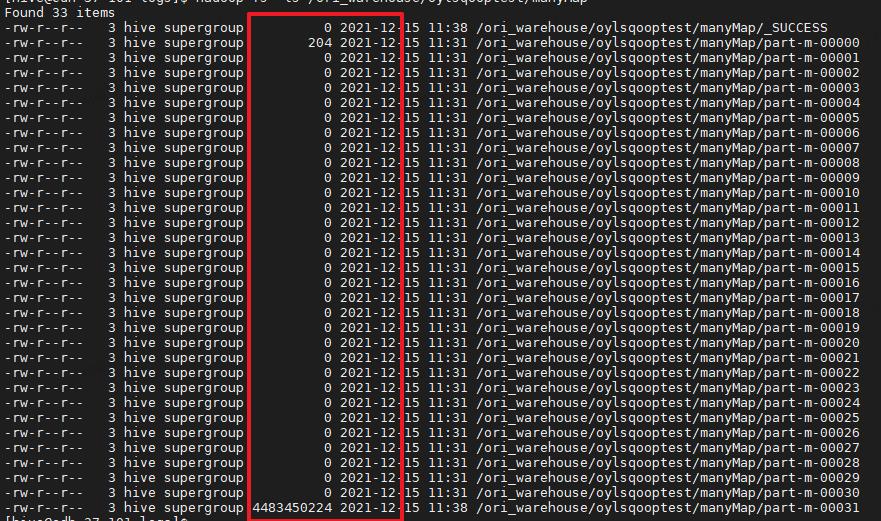
如图,32个Map中有31个Map是在30秒内执行完成的,只有一个map用过7分多钟,这就是数据倾斜
 2.5、我们使用了32个map为啥还都是在一个map上执行的呢?
2.5、我们使用了32个map为啥还都是在一个map上执行的呢?
首先我们要弄清楚sqoop是如何切割成32个map执行的
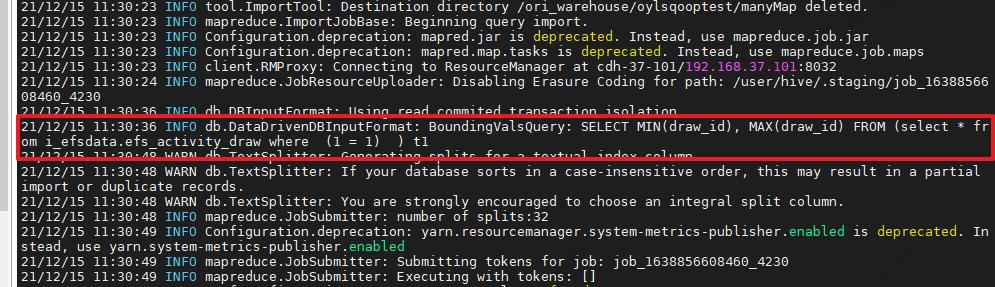
我们通过日志文件可以看到sqoop是对切分字段做了一个取最大最小值的操作,如下
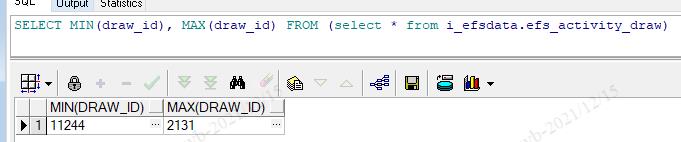
但是这是一个string类型的字段,我在oracle上执行了一下,我去吓到了,这个最大值和最小值也是无语了,完全不能使用的
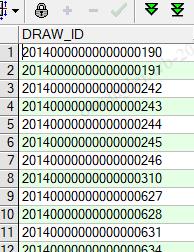
实际的数据是这样的字符串
所以通过对比发现你使用string类型来作为切割的字段根本没有起到多map的效果
通过最后hdfs的文件也可以发现数据都是一个map导过来的
三、将主键 string类型强转成bigint类型作为切分字段
3.1、数据量是17069846
3.2、使用32个Map来并行执行
3.3、编写执行sqoop的shell脚本
#!/bin/bash
sqoop import "-Dorg.apache.sqoop.splitter.allow_text_splitter=true" \\
--connect jdbc:oracle:thin:@192.168.119.227:1521:odsdb \\
--username 123123 \\
--password 123123 \\
--query 'select * from i_efsdata.efs_activity_draw where $CONDITIONS ' \\
--fields-terminated-by '\\001' \\
--hive-drop-import-delims \\
--target-dir /ori_warehouse/oylsqooptest/manyMap/ \\
--delete-target-dir \\
--null-string '\\\\N' \\
--null-non-string '\\\\N' \\
--split-by "cast(draw_id as int)" \\ ##强转int
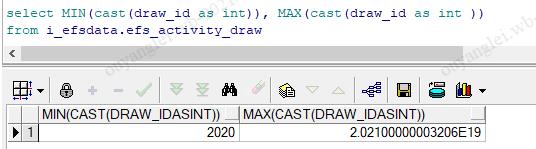
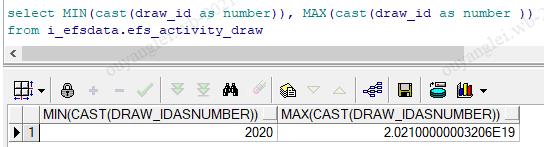
-m 32 &> /opt/sqoop_test/logs/oyltest_manyMap_Sqoop.log3.4、强转bigint报错(因为你的强转语句是在oracle上执行的,oracle没有bigint类型,所以报错),换成int,担心太大会不会不够,然后转成oracle的number,结果和int一致图如下
转int:
转number:
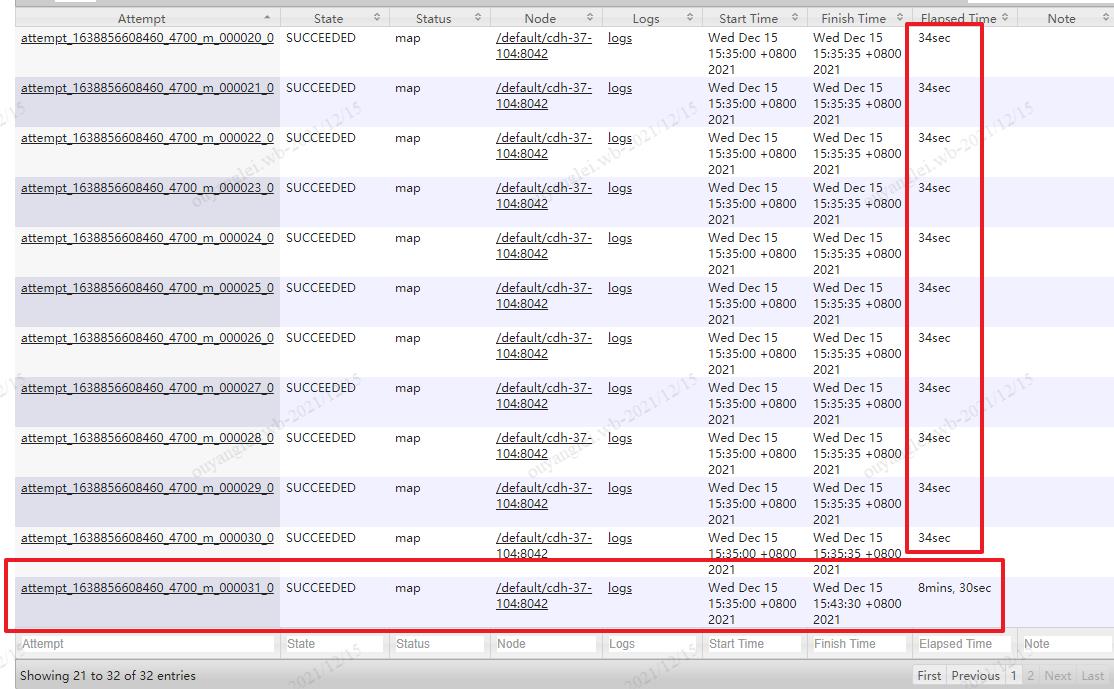
3.5、虽然我们强转成了int,但是还是出现了数据倾斜
1、数据倾斜
2、查看日志sqoop也确实按照强转后的类型进行取Max,Min

3、查看最后一个map里面的日志,找到他的sqoop参数sql如图

我在oracle上查了一下,这就是根本没有分均匀啊,这是啥情况,
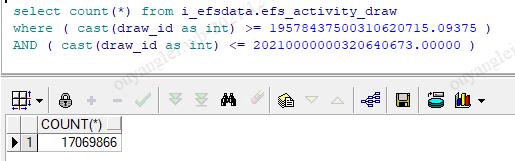
我认真比对了每一个Map的where ( cast(draw_id as int) >= 18946875000300600757.18750 ) AND ( cast(draw_id as int) < 19578437500310620715.09375 ) 发现sqoop是按照(max-min)/32来计算区间范围的,而我们的数据都是如下图所示字符串类型,虽然强转了,但是作为切割的key还是不均匀,所以全部数据还是到最后那个Map的区间里面去了。因此要想多个并行的map能够均匀的分配到数据,那必须要有一个均匀的--split-by参数
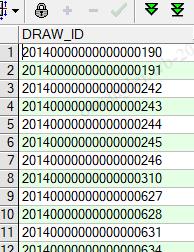
四、对主键字段进行row_number排序,达到均匀效果
4.1、数据量是17069846
4.2、使用32个Map来并行执行
4.3、编写执行sqoop的shell脚本
#!/bin/bash
##对主键字段进行row_number排序,使用排序字段来切分
sqoop import \\
--connect jdbc:oracle:thin:@192.168.119.227:1521:odsdb \\
--username 123123 \\
--password 123123 \\
--query 'select draw_id,third_user_id,login_name,user_id,activity_id,participate_times,
is_realized,prize_type_info,useing_detail_id,draw_time,remark,status,is_valid,pk_serial,
created_user,created_date,updated_user,updated_date,task_id,prize_sources,
prize_relation_id,share_string,biz_type,biz_key from
(select ROWNUM AS ETL_ID,ead.* from i_efsdata.efs_activity_draw ead) t1 where $CONDITIONS'\\
--fields-terminated-by '\\001' \\
--hive-drop-import-delims \\
--target-dir /ori_warehouse/oylsqooptest/manyMap/ \\
--delete-target-dir \\
--null-string '\\\\N' \\
--null-non-string '\\\\N' \\
--split-by ETL_ID \\
--boundary-query "select 1 as MIN,sum(1) as MAX from i_efsdata.efs_activity_draw" \\
-m 32 &> /opt/sqoop_test/logs/oyltest_manyMap_Sqoop.log4.4、参数说明
参数一:
--query 'select draw_id,third_user_id,login_name,user_id,activity_id,participate_times,
is_realized,prize_type_info,useing_detail_id,draw_time,remark,status,is_valid,pk_serial,
created_user,created_date,updated_user,updated_date,task_id,prize_sources,
prize_relation_id,share_string,biz_type,biz_key from
(select ROWNUM AS ETL_ID,ead.* from i_efsdata.efs_activity_draw ead) t1 where $CONDITIONS'\\我们看这个查询的sql,是两个SQL拼接上去的,
第一个SQL:select ROWNUM AS ETL_ID,ead.* from i_efsdata.efs_activity_draw ead 是为了做一个排序获得绝对的均匀数据 因为这是oracle所以排序写法有些不同
第二个SQL:就是不想将排序字段也导过来所以将字段都写出来了
参数二:
--boundary-query "select 1 as MIN,sum(1) as MAX from i_efsdata.efs_activity_draw" \\不加参数二报错

此参数是自己指定怎么来获当前表的max,min,为什么还需要自己指定呢?我们在shell脚本里面的--split-by参数是不是换成了我们临时制造出来的一个字段 ETL_ID,但是这个字段在表里面是不存在的,所以如果不指定自定义获取max,min那sqoop在去获取max,min的时候就会使用ETL_ID字段,那就报错了

4.5、最终执行结果
随便打开一个map里面的过滤条件都是很均匀的

最终每个map的执行时间基本一致(数据量17069978同步完成耗时90秒)
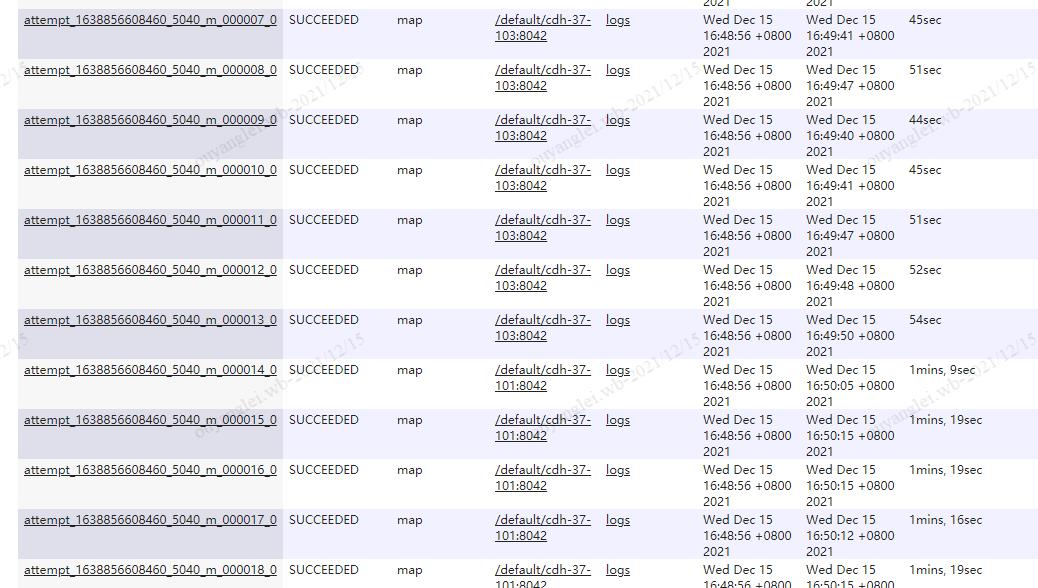
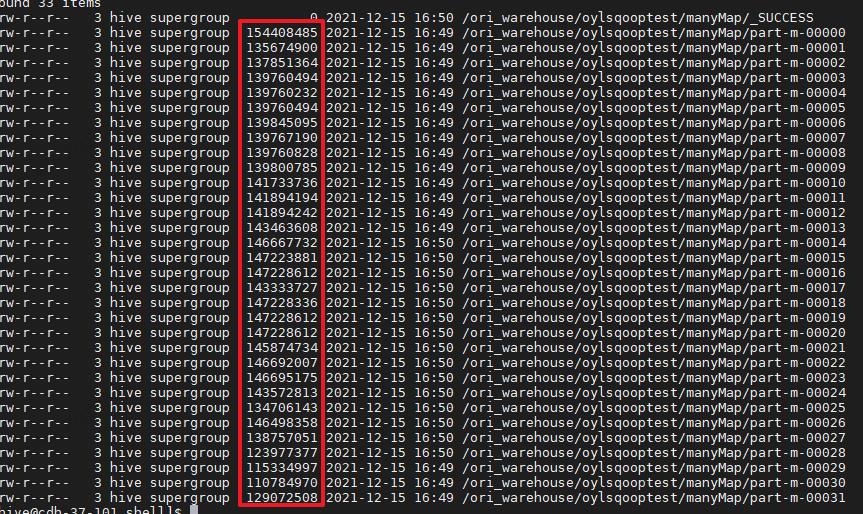
所以综上所述,不是使用主键作为切分字段就可以加快导数的时间,我们一定要明白sqoop的分割原理。
以上是关于Sqoop生产数据倾斜问题验证的主要内容,如果未能解决你的问题,请参考以下文章