多核心Linux内核路径优化的不二法门之-多核心平台TCP优化
Posted 宋宝华
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多核心Linux内核路径优化的不二法门之-多核心平台TCP优化相关的知识,希望对你有一定的参考价值。

原文作者:dog250
原文链接:https://blog.csdn.net/dog250/article/details/48690407
本文可以作为《 Linux转发性能评估与优化(转发瓶颈分析与解决方案)》的姊妹篇,这两篇文章结合在一起,恰好就是整个Linux内核协议栈的一个优化方案。事实上Linux协议栈本来就是面向两个方向的,一个是转发,更多的是本地接收。目前大量的服务器采用Linux作为其载体,更加体现了协议栈本地处理相对于转发的重要性,因此本文就这个问题扯两句,欢迎拍砖!
0.声明:
0).关于来源
昨天就答应皮鞋厂老板了,只是昨晚心情太复杂,本文没有赶出来,今天在飞机上写下了剩余的...
1).关于Linux原生代码
本文假设读者已经对Linux的TCP实现源码有了足够清晰的理解,因此不会大量篇幅分析Linux内核关于TCP的源代码,比如tcp_v4_rcv的流程之类的。
2).关于我的优化代码
由于涉及到很多复杂的因素,本文不提供完整的可编译的优化源码(整个源码并非我一人完成,在未经同伙同意之前,我不敢擅作主张,但是想法是我的,所以我能展示的只是原理以及我负责的那部分代码)。
3).关于TCP协议
本文不谈TCP协议本身以及其细节(细节请参考RFC以及各类论文,比如各种流控,拥控算法之类的),仅包含的内容是TCP协议之外的框架实现的优化。
1.Linux的TCP实现
1.1.Linux的TCP实现在协议层面分为两个部分
1).连接握手处理
TCP首先会通过三次握手建立一个连接,然后就可以传输数据了。TCP规范并没有指定任何的实现方式,当前的socket规范只是其中一种而已。Linux实现了BSD socket规范。
在Linux中,TCP的连接处理和数据传输处理在代码层面是合并在一起的。
2).数据传输处理
这个比较简单,略。
1.2.Linux的TCP在系统架构方面分为两个部分
1).软中断协议栈处理
Linux内核在软中断环境中进行协议栈的处理,在这个处理流程的最上方,会有3个分支:直接将skb复制到用户缓冲区,简单将skb排入到prequeue队列,简单将skb排入backlog队列。
2).用户进程处理
Linux的socket API的处理是在用户进程上下文中进行的。通过1.1节,我们知道由于代码层面上这些都是合并在一起的,因此一个socket会被各种执行流操作,直观的考虑,这需要大量锁的开销。
1.3.连接处理的总体框图
我给出一个连接处理总体框图,其中红线表示发生竞争的地方,而正是这些地方阻止了TCP连接的并行处理,图示如下:

我来一一解释这些红线的意义:
1号红线:
由于用户进程和协议栈操作的是同一个socket,如果用户进程正在copy数据包数据,那么协议栈就要停止同样的操作,反过来也一样,因此需要暂时锁定该socket,然而这种大锁的开销过于大,因此Linux内核协议栈的实现采用了一个更加优雅的方式。
协议栈锁定socket:由于软中断处理协议栈,它可能运行在硬中断之后的任意上下文,因此不能睡眠,故而必须是一把自旋锁slock,由socket本身保有,该锁不仅仅保护和用户进程之间的竞态,也保护不同CPU上对同一个socket协议栈操作之间的竞态(很常见,一个侦听socket上可以同时到达很多连接请求[可悲的是,这些请求不能同时被处理!!])。
用户进程锁定socket:用户进程是可以随时睡眠的,因此可以采用非自旋锁xlock来保护多个进程之间的竞态,然而同时又为了和内核协议栈操作同一个socket的软中断互斥,因此在获取xlock之前,首先要获取该socket的slock,当获取xlock之后或者暂时没有获得xlock要睡眠的时候,将slock释放掉。相关的逻辑如下:
stack_process
...
spin_lock(socket->slock); //1
process(skb);
spin_unlock(socket->slock);
...
user_process
...
spin_lock(socket->slock); //2
while(true)
...
spin_unlock(socket->slock);
睡眠;
spin_lock(socket->slock); //2
if (占据xlock成功)
break;
spin_unlock(socket->slock);
...
可见,Linux采用了以上的方式很完美的解决了两类问题,第一类问题是操作socket的执行流之间的同步与互斥,第二类问题时软中断上下文和进程上下文之间的锁的不同。
在理解了socket锁定之后,我们来看下backlog这个队列是干什么的。其实很简单,就是将skb推到当前正占据socket的那个进程的一个队列里面,等到进程完成任务,准备释放socket占有权的时候,如果发现该队列里面有skb,那么在其上下文中处理它们。这实际上是一种职责转移,这个转移也可以带来一些优化效果,那就是直接在socket所属的用户进程上下文处理skb,这样就避免了一部分cache刷新。
2号红线:
这条线在1号红线的解释中已经涉及了,主要就是上述代码逻辑中的1和2之间的竞争。这个竞争不是最激烈的,本质上它们属于纵向的竞争,一个内核态软中断和一个进程上下文之间的竞争,在同一个CPU上,一般而言,这类竞争的概率很低,因为同一个CPU同时只能执行一个执行流,假设此时它在内核态执行软中断,那么用户态的进程,它一定在睡眠或者被抢占,比如在accept中睡眠。
用户态处理和内核态处理,这种纵向的竞争在单CPU上几乎不会发生,而用户态的xlock根本就是为了解决用户进程之间的竞争,内核通过一个backlog在面对这种竞争时转移了数据包处理职责,事实上在xlock上并不存在竞争,backlog的存在反而带来了一点优化效果。
3号红线(结合3'号红线):
该红线为了解决多个用户进程之间的竞争。之所以画出的是TCP连接处理图而不是数据传输处理图,是因为连接图更能体现问题,在服务器端,一个主进程fork出来N多的子进程或者创建多个线程同时在一个继承下来的socket上accept,这几乎成了服务器设计的准则,那么这多个进程/线程同时到达这个slock的时候,争抢就会很激烈。再看3'号红线,我们发现针对同一个socket的accept必须排队进行。
如果你看Linux TCP的实现,你会发现大量的数据结构操作都没有用锁,事实上,进入到那里的,只有你一人,早在入口就排队了。
在单CPU上,这不会产生什么后果,因为单CPU即便在最先进的分时抢占调度器的协调下,本质上也是一个排队模型,充其量可以插队罢了,TCP实现的slock和xlock只是规范了这个排队规则而已。然而在多CPU上,仔细想想这有必要吗?
4号红线:
说完了用户态多个进程/线程同时在同一个socket上accept时的排队,现在看看内核协议栈的处理,也好不到哪里去。如果多个CPU同时被连接请求中断,大量的请求针对同一个侦听socket,那么大家就要在4号红线处排队!而这个情况在单CPU时几乎并不存在,根本不可能同时有多个CPU执行到同一个地点...
2.多核CPU架构下Linux TCP连接处理性能瓶颈
通过以上针对几条红线的描述,到此为止,我已经展示了几个瓶颈,这些点都是要排队的点。以上的那个框图事实上非常好,这些排队点也无可厚非,因为设计一个系统,就是要自包容解决所有问题,竞争只要存在,就一定要通过排队来解决它,因此上述的框架根本不用更改,锁还是留在原处。问题的根本不是锁的存在,问题的根本在于锁的不易获取!
TCP的处理运行在各个CPU上,CPU被当作了一种资源,这是操作系统的核心概念,但是反过来呢?如果把CPU当成服务者本身,而socket当成资源,问题就迎刃而解了。这个思路很重要,我在nf-HiPAC中第一次接触到了它,原来可以把match和rule颠倒过来玩,然后以这个思想做指导我设计了DxR Pro++,现在还是这个思想,TCP的优化依然可以这么做。
3.Linux TCP连接处理优化
整体考虑一种连接处理被优化后的TCP实现,我只关心从accept API中会返回什么。只要我能快速获取一个客户socket,并且不破坏listen,bind这些API本身,修改其实现是必须的。
3.1.纵向拆分socket
我将一个listen socket拆分成了两个部分,上半部和下半部,上半部对应用户进程,下半部对应内核协议栈。原始的socket是下图的样子:
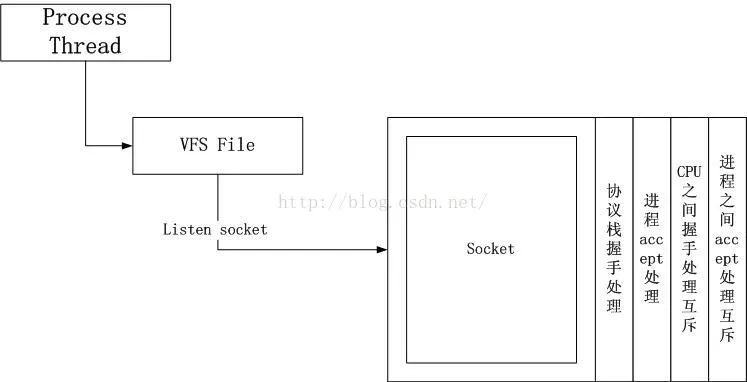
我的socket被改成了下面的样子:
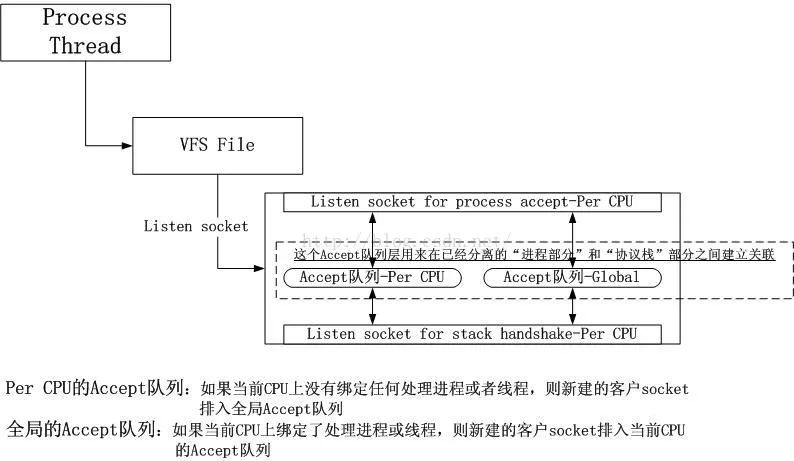
消解1号红线和2号红线
一个socket的上半部和下半部只通过一个accept队列关联,事实上即使在上半部正在占有socket的时候,下半部依然可以继续处理。
然而,事实证明,在执行accept的进程绑定CPU的情况下,1号红线的消解并没有预期的性能提升,而2号红线的消解带来的性能提升影响也不大。如果是不绑定CPU,性能提升反而比绑定更好,看来横向和纵向并不是独立的两块,它们会相互影响。
3.2.横向拆分socket
横向拆分的思路就是将一个socket下半部拆成多个,每一个CPU上强制绑定一个,类似softirqd每一个CPU上一个一样,这样可以消解4号红线。但是为何不拆解socket的上半部呢?我一开始的想法是让进程自行决定,后来觉得同样也要强行绑定一个,至于说什么用户进程可以自行解除绑定之类的,加一个层次隐藏掉Per CPU socket即可。此时的用户进程中的文件描述符只是指示一个socket描述符,而该描述符真正指向的是nr_cpus个Per CPU socket,如下图所示:
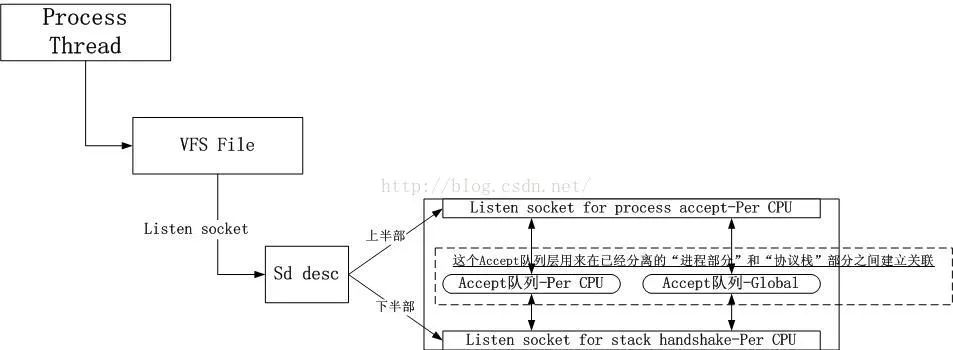
这样3号红线,3'号红线,4号红线全部消解。事实上,看到这里好像一切都大功告成了,但是测试的时候,发现还有两个问题,接下来我会在描述数据结构的拆解中描述这两个问题。
3.3.全局Listeners哈希表
由于Listener会复制nr_cpus份到每一个CPU上,故而所有的Listeners会被加入到每一个CPU的本地哈希表中,这种以空间换无锁并行是值得的,因为服务器上并不会出现海量的侦听服务。
3.4.本地Accept队列和全局Accept队列
如果系统中每一个CPU上都绑定有accept进程,那么可以保证所有的连接请求都会被特定的进程处理,然而如果有一个CPU上没有绑定任何accept进程,那么被排队到该CPU的Accept队列的客户socket将不会返回给任何进程,从而造成客户socket饿死。
因此引入一个全局Accept队列。相关的代码逻辑如下:
stack_enqueue_socket
if (本CPU上没有绑定任何与该Listener相关的用户进程)
spin_lock(g_table->slock);
enqueue_global(g_table, cli_socket);
spin_unlock(g_table->slock);
else
local_irq_save
enqueue_local(per_cpu(table), cli_socket);
local_irq_restore
user_dequeue_socket_for_accept
if (当前进程没有绑定到当前CPU)
spin_lock(g_table->slock);
cli_socket = dequeue_global(g_table);
spin_unlock(g_table->slock);
else
local_irq_save
cli_socket = dequeue_local(per_cpu(table));
local_irq_restore
return cli_socket;
事实上,可以看到,全局的Accept队列是专门为那些顽固不化的进程设置的,但是还是可以以一把小锁的代价换来性能提升,因为锁的粒度小多了。
3.5.软中断CPU分发问题
由于每一个CPU上绑定了一个Listener socket的下半部,并且几乎所有的数据结构都是本地维护的,CPU正式成了TCP的一部分。因此必须保证一件事,那就是3次握手必须由一个CPU处理,否则就会出错。而由于如今很多启动了irqbalance的系统,中断可能会分发到不同的CPU,比如来自特定客户端的SYN被CPU0处理,而3次握手中的ACK则被CPU1处理,这就造成了错误。为了避免这个局面,底层必须维护数据流和CPU之间的映射。这个可以通过RFS的技术来解决。
当第一个SYN包到达之时,处理这个连接握手过程的CPU就确定了,就是当前的CPU,这个和用户态的进程“跳”到哪个CPU上没有任何关系。因此实现比RFS要简单得多。代码逻辑如下:
netif_receive_skb
...
hash = myhash(skb)
cpu = get_hash_cpu(hash);
if (cpu == -1)
record_cpu_hash(hash, cpu);
else if (current_cpu != cpu)
enqueue_to_backlog(skb, cpu);
此后由IPI触发中断,被别的CPU处理
else
正常的接收逻辑
...
示意图如下:

3.6.与REUSEPORT以及fastsocket的关系
我的这个优化版本和REUSEPORT没有任何关系,REUSEPORT是google的一个patch,非常好用,在我们的一个产品中就用到了这个技术,它可以做到在多个侦听相同IP地址和端口的不同socket之间做到负载均衡,然而这个负载均衡的效果则完全取决于hash算法。事实上Sina的fastsocket就是在REUSEPORT之上做的优化,其主要做了CPU Affinity方面的优化,效果很不错。相似的优化还有RPS/RFS patch,然而fastsocket更进一步,它不光延续了RPS/RFS的成果,而且把连接性能瓶颈也解决了,其主要的做法就是采用CPU绑定技术对一个Listen socket在REUSEPORT的基础上做了横向拆分,复制了多个Listen socket来reuseport。
fastsocket的做法是用户进程自己决定是否要绑定CPU,因此哪个CPU处理哪些数据包是通过用户进程设置的,而我的做法则正好相反,我的优化从下到上,我是由第一个SYN包恰好中断的那个CPU作为其握手过程后续被处理的CPU,和用户进程的设置无关,即便用户进程没有绑定CPU,它也充其量只是从全局Accept队列小代价取客户socket而已,而如果绑定了CPU,那几乎是全线无锁操作。结合3.5小节,我们看下fastsocket是怎么获得对应处理该数据包的CPU的:
netif_receive_skb
...
socket = inet_lookup(skb);
cpu = socket->sk_affinity;
if (current_cpu != cpu)
enqueue_to_backlog(skb, cpu);
此后由IPI触发中断,被别的CPU处理
else
正常的接收逻辑
...
fastsocket有一个查socket表的操作,如果是连接处理,对于绑定CPU的socket,可以在本地表中获取到。如果你觉得fastsocket在这里平添了一次查找,那你就错了,事实上这是fastsocket的另一个优化点,即Direct TCP,也就是说在这个位置就查找具体的socket,连路由之类的都放进去,后续的所有查找结果都可以放入,也就可以实现一次查找,多次使用了。
Direct TCP的处理看似不符合协议栈分层处理的规则,在如此的底层处理四层协议,事实上在某些情况也会因此而付出性能代价:
1).如果有大量的包是转发的呢?
2).如果有大量的包是UDP的呢?
3).如果是攻击包呢?
4).如果这些包是接下来要被Netfilter刷掉的呢?
...
这有点像另一个类似的Direct技术,即socket的busy poll。想获得甚高的性能,你必须对你的系统的行为足够理解,比如你知道这台服务器就是专门处理TCP代理请求的,那么开启Direct TCP或者busy poll就是有好处的。
而我认为我的这个优化方案是一个更加通用的方案,实际上只有单点微调,且不会涉及别的情况,只要你能保证数据包到达的中断行为是优雅的,后面的处理都是水到渠成的,完全自动化。就算是面对了上述4种非正常数据包,一个hash计算的代价也很小,且不需要面临RCU锁的内存屏障导致的刷流水问题。现如今,随着多队列网卡以及PCI-E MSI的出现和流行,有很多技术可以保证:
1).同一个元组标识的流的数据包到达后总是中断同一个CPU;
2).处理不同的流的CPU上的负载非常均衡。
只要做到以上2点,其它的事情就不用管了,对于TCP的连接包,数据包会在同一个CPU一路向上一路无锁到达本地Accept队列或者全局Accept队列,接下来会转向另外一条同样宽拥有同样多车道的高速公路,这条新的公路由进程操纵。
最终,优化过的TCP连接处理框图如下:

PS:我的这个方案不需要修改应用程序,也无须链接任何库,完全替换内核即可。目前对fastopen并不支持。
对于TCP的非握手包的处理,应该怎么优化呢?
4.Linux TCP数据处理优化
以前,我们以为TCP典型的C/S处理的服务端是一个一对多的模型,因此listen+accept+fork这种流行的socket编程模型几乎一致持续到现在。期间衍生出各种MPM技术。这种模型本身就让人觉得TCP的连接处理就是那个样子,本身就有一个瓶颈在那里!事实上,不管是fastsocket,还是我的这个方案,都解决了一对多问题,模型成了多对多的。
那么对于TCP的数据传输处理,它该怎么优化呢?要知道,它可不是一对多的模型,它是一个天然的一对一的模型,而TCP又是一个严格按序的协议,为了保序,采用并行化处理是一个愚蠢的想法。为了优化它,我们先给出可能的瓶颈在哪里。
4.1.一对一TCP连接的瓶颈分析
由于TCP连接中会有大量的数据传输,因此内存拷贝是一个瓶颈,然而本文不关注这个,这个可以通过各种技术解决,比如DMA,零拷贝,分散/聚集IO等,本文关注的是CPU亲和力的优化。另外,考虑到这种ESTABLISHED状态的一对一连接的数量还有对其的操作。
考虑持续到来的短连接,大量的并发,我们来看下内核中ESTABLISHED哈希表的压力
1).持续的新建连接(握手完成,客户socket会插入表中),锁表,排队;
2).持续的连接释放,锁表,排队;
3).大量的连接同时存在,大量的TIME_WAIT,查询延迟且连累正常连接;
4).TIME_WAIT socket也面临持续新建,释放的问题。
...
如果是长连接,可能会缓解,但病根不除,不绝后患。
由于这个是一对一的对称模型,TCP的按序性不好做并行化本地操作,因此我也就没有对其进行横向拆分,没了横向拆分,对于纵向拆分也就没有了意义,因为势必会出现多个CPU对队列的争抢问题。因此与连接处理的优化原则完全不同。
4.2.优化一对一TCP连接数据传输处理部分
如何优化?目标已经很明确,那就是本地化查询,本地化插入/删除,尽量减少RCU的内存屏障的影响。
和连接处理不同,我们没法把CPU当成主角,因为一条连接的处理同一个时刻只能在一个CPU上。因此为了加速处理并且维护cache,建立两条原则:
1).增加一个ESTABLISHED表的本地cache,该cache可以无锁操作;
2).在用户进程等待数据期间,禁止进程迁移。
我的逻辑如下,事实证明真的不错:
tcp_user_receive/poll
0.例行RPS操作
1.设置进程为不可迁移
disable中断
2.将socket加入当前CPU的本地ESTABLISHED表 (优化点1:如果本地表没有才加入)
enable中断
3.sleep_wait_for_data_or_event
4.读取数据
disable中断
5.将socket从本地ESTABLISHED表中摘除 (优化点1:不需要摘除)
enable中断
6.清除不可迁移位
tcp_stack_receive
1.例行tcp_v4_rcv的操作
2.查找当前CPU的本地ESTABLISHED表
没有找到的情况下,查找系统全局的ESTABLISHED表
3.例行tcp_v4_rcv的操作
很显然,上述的逻辑基于以下的判断:既然进程已经在一个CPU上等待数据了,最好的方式就是将这个进程暂时钉死在这个CPU上,并且告知内核协议栈,将软中断上来的数据包交给这个CPU。钉死这个进程是暂时的,只为接收一轮数据,这个显然要在task_struct中增加一个flag或者借一个bit,而通知内核协议栈的软中断例程则是通过将该socket加入到本地的ESTABLISHED缓存哈希表中实现的。
在进程获得了一轮数据之后,为了不影响Linux系统全局的域调度行为(Linux的域调度可以很好的做到进程的负载均衡同时又不破坏cache的热度),需要将钉死的进程释放,同时注意优化点1,到底需不需要将socket从本地表摘除呢?鉴于进程迁移一般都是小概率事件,所以进程在相当大的概率下是不会迁移的,因此不摘除socket可以省下一些mips。
4.3.客户socket与连接处理完全分开处理
一对一的TCP socket数据传输处理和本文第一部分描述的连接处理是没有关系的,accept返回之后,由哪个进程/线程处理这个客户socket,是否绑定它到特定的CPU,这些都不会影响连接处理的过程。
4.4.Linux原生协议栈的例行优化-prequeue与backlog
事实上,由于涉及到数据拷贝,内核协议栈一直都是倾向于让用户进程自己来解析,处理一个skb,而内核要做的只是将skb挂在某个队列中,这是一个非常常规的优化。Linux协议栈中存在两个队列,prequeue和backlog,前者是当协议栈发现没有任何一个用户进程占据某个socket的时候,其尝试将skb挂入一个用户prequeue队列,当用户进程调用recv的时候,自行dequeue并处理之,后者则是当协议栈发现当前socket被某个用户进程占据的时候,将skb挂入backlog队列,待用户进程释放该socket的时候,自行dequeue并处理之。
4.5.Linux原生协议栈的例行优化-RPS/RFS优化
这实际上是软件模拟的RSS类似的东西,资料已经不少,其宗旨就是尽量让协议栈处理的CPU和用户进程处理的CPU是同一个CPU,我们知道,对于连接处理,由于是一对多的关系,这样并不可行,然而对于一对一的客户socket,这样的效果非常好。
4.6.Linux原生协议栈的例行优化-early demux
Linux协议栈期望如果在确认一个数据流的第一个数据包是本地接收的前提下,免除后续路由查找,只实现socket查找即可。这是一种典型的一次查找,短路使用的优化方案,类似的还有一次查找,多方多次使用,类似于我对nf_conntrack所做的那样。
4.7.Linux原生协议栈的例行优化-busy poll
顾名思义,就是不等协议栈往上送skb,而是自己直接去底层拿,有点像快递自提那种。然而由于在底层没有经过协议栈处理,根本就不确定这个数据包是不是发给自己的,因此这会有一定的风险,但是如果在统计意义上你能确定自己系统的行为,那么也是可以起到优化效果的。
5.总结
5.1.关于TCP连接处理的优化
如果你把一个Listener仅仅看作是一个被内核协议栈处理的socket,那么你很容易找到很多值得优化的点,比如这里把锁拆分成粒度更细的,那里判断一下抢占什么的,然后代码就会越来越复杂和庞大。但是反过来,如果你把一个Listener看作是一个基础设施,那事情就简单多了。基础设施是服务于客户的,它有两个基本的性质:
1).它永远在那里
2).它不受客户的控制
对于一个TCP Listener,难道它不该是一个基础设施吗?它应该和CPU是一伙的,作为资源然后为连接请求服务,它本不应该是抢CPU的家伙,不应该抱有“它如何才能抢到更多的CPU时间,如何才能拽取其它Listener的资源....”这样的想法去优化它。
Linux内核中有很多这样的例子,比如ksoftirqd/0,ksoftirqd/0/1,像这种kxxxx/n这类内核线程都可以看作是基础设施,在每一个CPU上提供相同的服务,不干涉别的CPU,永远都是取Per CPU的管理数据。按照这样的想法,当需要提供一个TCP服务的时候,很容易想法建立一个类似的基础设施,它将永远在那里,每一个CPU上一个,为新到来的连接提供连接服务,它服务的产品就是一个客户socket,至于说怎么交给进程,通过两类Accept队列提供一个服务窗口!我们假设一个侦听进程或者线程挂掉了,这丝毫不会影响TCP Listener基础设施,它的进程无关性继续为其它的进程提供客户socket,直到所有的侦听进程全部挂掉或者主动退出,而这很容易用引用计数来跟踪。
在这个优化版本中,你可以这样想,从两类Accept队列往下,TCP Listener基础设施与用户的侦听进程无关了,不会受到其影响,即便用户侦听进程不断在CPU间跳跃,绑定,解除绑定,它们影响不到Accept队列下面的TCP Listener基础设施,受影响的也只是它们自己从哪个Accept队列里获取客户socket的问题。下面是一个简图:
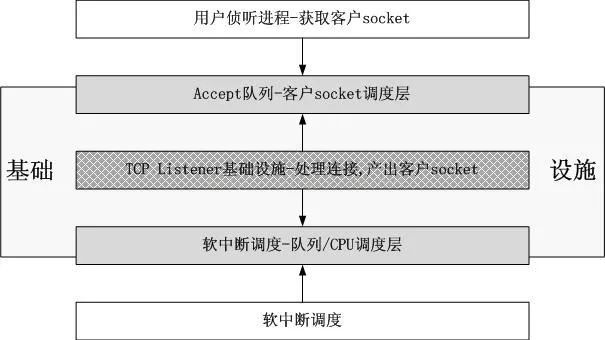
同样,由于TCP Listener已经基础设施化了,向上用Accept队列隔离了用户进程socket,向下用中断调度系统隔离了网卡或者网卡队列,因此也就没有了很多优化版本中面临的四种情况:队列比CPU多,队列与CPU相等,队列比CPU少,根本就没有队列。
5.2.关于TCP传输处理的优化
本文针对这个方面说的不是很多,很大一部分原因在于这部分并不是核心瓶颈,Linux本身的调度系统已经可以很好的应对进程切换,迁移对cache的影响,因此,你会发现,我做的仅有的优化也是针对这两方面的,同时,增加一个本地ESTABLISHED哈希缓存会带来小量的性能提升,这个想法来自于我增加的nf_conntrack的cache以及slab分级cache。
5.3.与数据包转发的统一
前段时间搞过一个Linux转发性能优化,当时引入了一个虚拟输出队列(VOQ),解决加速比的问题,为了实现线速pps,转发的情况存在网卡带宽的N加速比问题,因此当时创建转发基础设施的时候是把网卡拉过来搭伙合作,而不是CPU,事实上,如果在多队列网卡上,这二者是完全一致的,网卡队列可以绑定到CPU,并且还可以一个CPU专门处理输入,一个专门处理输出。
配合Per CPU的skb pool(我举的是卡车运货的例子),每一个Listener在每一个CPU上都有一个skb pool,这样对于本地出发的数据包,可以做到无锁化的分配skb。
现在针对TCP的情况我们可以把转发和本地接收统一在一起了,对于转发而言,出口是另一块网卡,对于本地接收而言,出口是Accept队列(握手包)或者用户缓冲区(传输包)。如果出口处没有用户进程,假设不是放入队列,而是直接丢弃,那么Per CPU的Accept队列真的就是一块网卡了。
以上是关于多核心Linux内核路径优化的不二法门之-多核心平台TCP优化的主要内容,如果未能解决你的问题,请参考以下文章