在PaddlePaddle中的Notebook代码片段
Posted 卓晴
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了在PaddlePaddle中的Notebook代码片段相关的知识,希望对你有一定的参考价值。

简 介: ※利用Python编写的aisi辅助程序,可以在一定程度上缓解简单性与灵活性之间的矛盾。这以个人搭建网络的习惯进行固定,在平时以更小的代码量,更灵活的方式构建深度学习程序。提高程序开发效率。
关键词: AI studio,PaddlePaddle,asis
§01 代码片段
1.1 背景介绍
借助于Python语言的精简特性,很多 深度学习平台 在构建深度神经网络方面都进行了高度的封装。很多情况下,一些介绍性的文章都在强调仅需10句话就可以构成深度学习网络,云云。
尽管如此,精简性与灵活性之间的矛盾一直是横亘在网络编程之间障碍。为此,在paddlepaddle的AI Studio环境中(BML CodeLab)下,集成了一些代码片段库,在一定程度上可以减少输入代码的繁琐性。
1.2 公共代码片段
在BML CodeLab环境下,在左面有公共代码片段工作页,其中包含了很多代码片段。
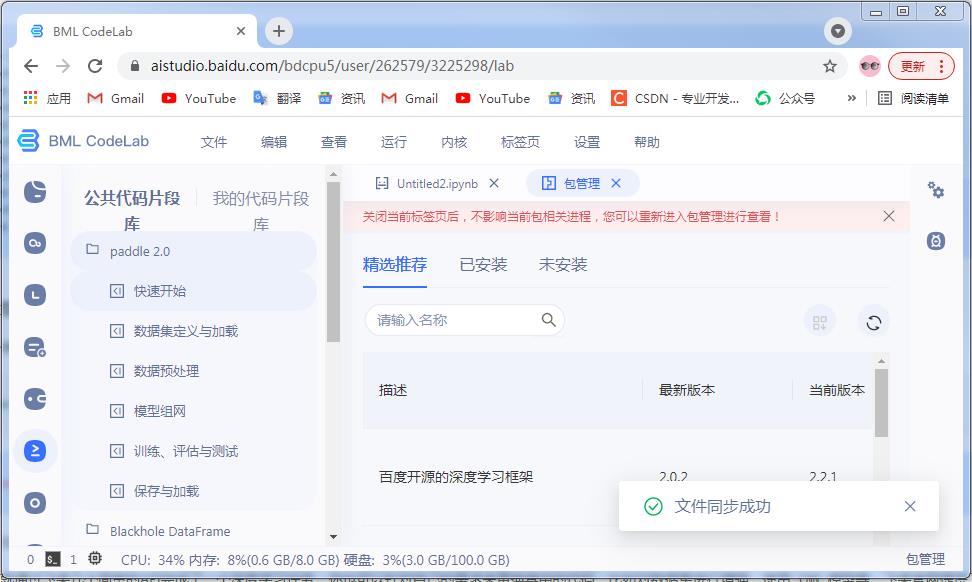
▲ 图1.2.1 BML CodeLab中的代码片段
1.2.1 代码片段种类
代码片段包含有一下代码片段种类:
- paddle 2.0
- Blackhole DataFrame
- Blackhole ML
- 描述性统计信息
- 新建列
- 缺失值处理
- Seaborn基本操作
- Bokeh基本操作
- Matplotlib基本操作
- Numpy基本操作
- seaborn可视化
- 线性回归
- DASK DATAFRAMES
在 paddle 2.0 种类中,包含有:
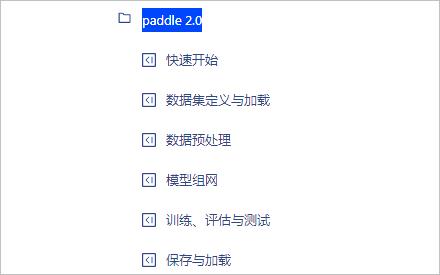
▲ 图1.2.2 paddle 2.0中的代码片段
点击其中一个代码片段,可以打开对应的编辑框:

▲ 图1.2.3 paddle 2.0 快速开始代码片段
将这些代码片段进行拷贝,编可以运行。因此可以实现 0 输入代码的编程。如果想进一步改进,可以在这些代码基础上进行修改编辑即可。
1.2.2 代码片段代码
下面对于Paddle 2.0 中的各个代码片段进行摘录:
(1)快速开始
import paddle
from paddle.vision.transforms import ToTensor
# 加载数据集
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=ToTensor())
val_dataset = paddle.vision.datasets.MNIST(mode='test', transform=ToTensor())
# 模型组网
mnist = paddle.nn.Sequential(
paddle.nn.Flatten(),
paddle.nn.Linear(784, 512),
paddle.nn.ReLU(),
paddle.nn.Dropout(0.2),
paddle.nn.Linear(512, 10)
)
# 封装模型
model = paddle.Model(mnist)
# 配置训练模型
model.prepare(paddle.optimizer.Adam(parameters=model.parameters()),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
# 模型训练
model.fit(train_dataset,
epochs=5,
batch_size=64,
verbose=1)
# 模型评估
model.evaluate(val_dataset, verbose=0)
# 模型测试
model.predict(val_dataset)
# 模型保存
model.save('./model')
(2)数据集定义与加载
import paddle
# 方法一:飞桨框架自带数据集
print('视觉相关数据集:', paddle.vision.datasets.__all__)
print('自然语言相关数据集:', paddle.text.__all__)
# 使用飞桨框架自带数据集
from paddle.vision.transforms import ToTensor
# 训练数据集 用ToTensor将数据格式转为Tensor
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=ToTensor())
# 验证数据集
val_dataset = paddle.vision.datasets.MNIST(mode='test', transform=ToTensor())
# 方法二:自定义数据集
from paddle.io import Dataset
BATCH_SIZE = 64
BATCH_NUM = 20
IMAGE_SIZE = (28, 28)
CLASS_NUM = 10
class MyDataset(Dataset):
"""
步骤一:继承paddle.io.Dataset类
"""
def __init__(self, num_samples):
"""
步骤二:实现构造函数,定义数据集大小
"""
super(MyDataset, self).__init__()
self.num_samples = num_samples
def __getitem__(self, index):
"""
步骤三:实现__getitem__方法,定义指定index时如何获取数据,并返回单条数据(训练数据,对应的标签)
"""
data = paddle.uniform(IMAGE_SIZE, dtype='float32')
label = paddle.randint(0, CLASS_NUM-1, dtype='int64')
return data, label
def __len__(self):
"""
步骤四:实现__len__方法,返回数据集总数目
"""
return self.num_samples
# 测试定义的数据集
custom_dataset = MyDataset(BATCH_SIZE * BATCH_NUM)
print('=============custom dataset=============')
for data, label in custom_dataset:
print(data.shape, label.shape)
break
# 数据加载
train_loader = paddle.io.DataLoader(custom_dataset, batch_size=BATCH_SIZE, shuffle=True)
# 如果要加载内置数据集,将 custom_dataset 换为 train_dataset 即可
for batch_id, data in enumerate(train_loader()):
x_data = data[0]
y_data = data[1]
print(x_data.shape)
print(y_data.shape)
break
(3)数据预处理
import paddle
print('数据处理方法:', paddle.vision.transforms.__all__)
# 场景一:飞桨框架内置数据集 + 数据预处理
from paddle.vision.transforms import Compose, Resize, ColorJitter
# 定义想要使用的数据增强方式,这里包括随机调整亮度、对比度和饱和度,改变图片大小
transform = Compose([ColorJitter(), Resize(size=32)])
# 通过transform参数传递定义好的数据增强方法即可完成对自带数据集的增强
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=transform)
# 场景二:自定义数据集 + 数据预处理
from paddle.io import Dataset
BATCH_SIZE = 64
BATCH_NUM = 20
IMAGE_SIZE = (28, 28)
CLASS_NUM = 10
class MyDataset(Dataset):
def __init__(self, num_samples):
super(MyDataset, self).__init__()
self.num_samples = num_samples
# 在 `__init__` 中定义数据增强方法,此处为调整图像大小
self.transform = Compose([Resize(size=32)])
def __getitem__(self, index):
data = paddle.uniform(IMAGE_SIZE, dtype='float32')
# 在 `__getitem__` 中对数据集使用数据增强方法
data = self.transform(data.numpy())
label = paddle.randint(0, CLASS_NUM-1, dtype='int64')
return data, label
def __len__(self):
return self.num_samples
# 测试定义的数据集
custom_dataset = MyDataset(BATCH_SIZE * BATCH_NUM)
print('=============custom dataset=============')
for data, label in custom_dataset:
print(data.shape, label.shape)
break
(4)模型组网
import paddle
# 方法一:使用飞桨框架内置模型
print('飞桨框架内置模型:', paddle.vision.models.__all__)
lenet = paddle.vision.models.LeNet()
paddle.summary(lenet, (64, 1, 28, 28))
# 方法二:Sequential 组网
mnist = paddle.nn.Sequential(
paddle.nn.Flatten(),
paddle.nn.Linear(784, 512),
paddle.nn.ReLU(),
paddle.nn.Dropout(0.2),
paddle.nn.Linear(512, 10)
)
# 方法三:SubClass 组网
class Mnist(paddle.nn.Layer):
def __init__(self):
super(Mnist, self).__init__()
self.flatten = paddle.nn.Flatten()
self.linear_1 = paddle.nn.Linear(784, 512)
self.linear_2 = paddle.nn.Linear(512, 10)
self.relu = paddle.nn.ReLU()
self.dropout = paddle.nn.Dropout(0.2)
def forward(self, inputs):
y = self.flatten(inputs)
y = self.linear_1(y)
y = self.relu(y)
y = self.dropout(y)
y = self.linear_2(y)
return y
(5)与测试
import paddle
from paddle.vision.transforms import ToTensor
# 加载数据集
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=ToTensor())
val_dataset = paddle.vision.datasets.MNIST(mode='test', transform=ToTensor())
# 模型组网
mnist = paddle.nn.Sequential(
paddle.nn.Flatten(),
paddle.nn.Linear(784, 512),
paddle.nn.ReLU(),
paddle.nn.Dropout(0.2),
paddle.nn.Linear(512, 10)
)
# 封装模型
model = paddle.Model(mnist)
# 配置训练模型
model.prepare(paddle.optimizer.Adam(parameters=model.parameters()),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
# 模型训练
model.fit(train_dataset,
epochs=5,
batch_size=64,
verbose=1)
# 模型评估
model.evaluate(val_dataset, verbose=0)
# 模型测试
model.predict(val_dataset)
(6)保存预加载
import paddle
from paddle.vision.transforms import ToTensor
# 加载数据集
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=ToTensor())
val_dataset = paddle.vision.datasets.MNIST(mode='test', transform=ToTensor())
# 模型组网
mnist = paddle.nn.Sequential(
paddle.nn.Flatten(),
paddle.nn.Linear(784, 512),
paddle.nn.ReLU()