经典深度学习框架
Posted 三つ叶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了经典深度学习框架相关的知识,希望对你有一定的参考价值。
2.1 LeNet
数据集:MNIST
- 50,000 个训练数据
- 10,000 个测试数据
- 图像大小 28 × \\times × 28
- 10 类
LeNet架构
第一层
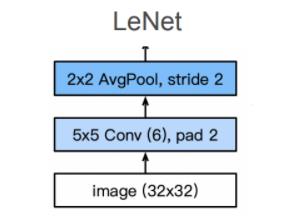
第二层
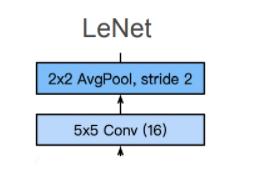
第三层
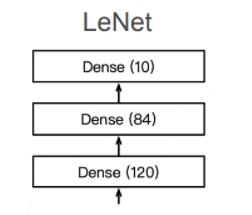
总结
- LeNet 是早期成功的神经网络
- 先使用卷积层来学习图片空间信息
- 然后使用全连接层来转换到类别空间
2.2 AlexNet
数据集:ImageNet(2010)
| 数据集 | ImageNet | MNIST |
|---|---|---|
| 图片 | 自然物体的彩色图片 | 手写数字的黑白图片 |
| 大小 | 469 × \\times × 387 | 28 × \\times × 28 |
| 样本数 | 1.2M | 60K |
| 类数 | 1000 | 10 |
AlexNet 架构
AlexNet 赢得了 2012 年 ImageNet 竞赛,重新让深度学习回到人们视野,从某种程度上来说是对 LeNet的拓展,相比于之前流行的 SVM 方法采用人工特征提取,AlexNet 通过 CNN 学习特征,然后进行 Softmax 回归进行分类。当然让深度学习重新回到视野,离不开数据量的提升以及计算机性能的提高。
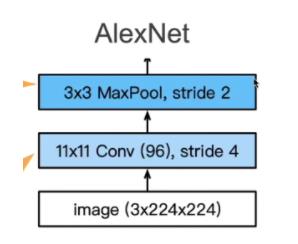
如图所示在第一层,AlexNet 采用了更大的核窗口和步长,因为图片更大了。同时使用了更大的池化窗口,并且采用最大池化。用了更大的输出通道(96),希望提取更多的特征信息。
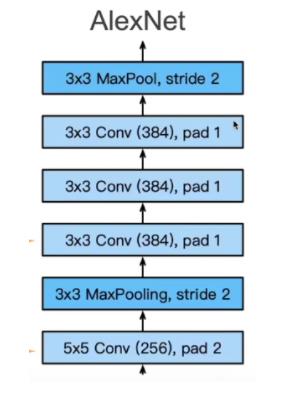

Dense 层,即稠密层也即全连接层。因为 ImageNet 最后要做 1000 分类,显然隐藏层要设的比 1000 大点,这里设置的是 4096.
更多细节
- 激活函数从 sigmoid 变到了 ReLu (减缓梯度消失)
- 隐藏全连接层后加入了丢弃层
- 数据增强
总结
- AlexNet 是更大更深的 LeNet,10 × \\times × 参数个数,260 × \\times × 计算复杂度
pytorch 的 torchvision中 的 Alexnet:https://github.com/pytorch/vision/blob/main/torchvision/models/alexnet.py (pytorch 中的代码参考的并非是 AlexNet 的原论文,而是这篇论文)
关于 pytorch 中的 AlexNet 的使用可以参考官方说明: https://pytorch.org/hub/pytorch_vision_alexnet/ 输入图像需要是 3 × \\times × 224 × \\times × 224 这样
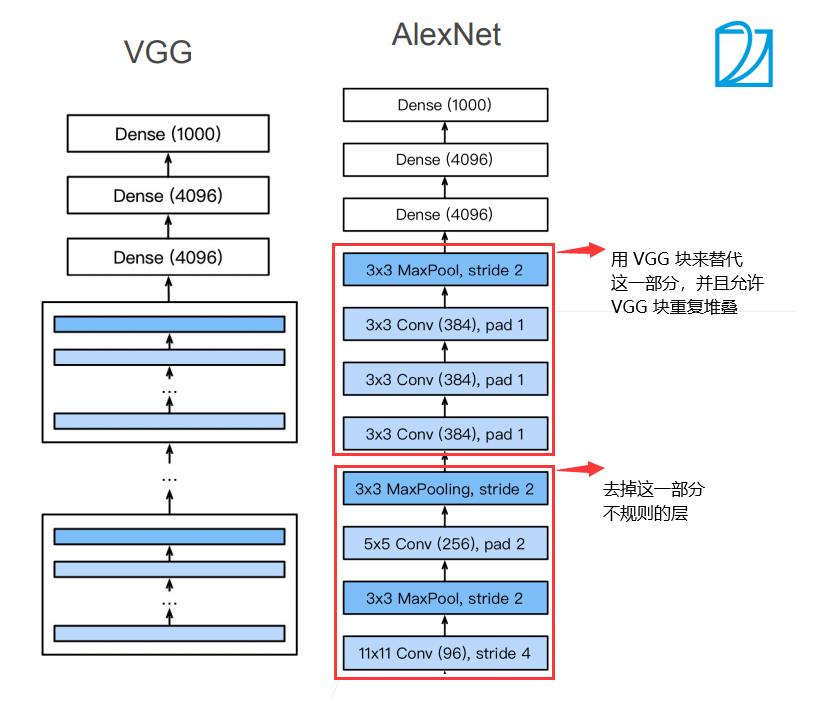
2.3 VGG —— 使用“块”的网络
VGG 块
- 3 × \\times × 3 卷积(填充1)若干
- 2 × \\times × 2 最大池化层(步幅2)

VGG 架构
- 多个 VGG 块后接全连接层
- 不同次数的重复块得到不同的架构 VGG-16,VGG-19,…
总结
- VGG 使用可重复使用的卷积块来构建深度卷积神经网络
- 不同的卷积块个数和超参数可以得到不同复杂度的变种
VGG pytorch官方说明:vgg-nets | PyTorch
VGG pytorch源码:https://github.com/pytorch/vision/blob/main/torchvision/models/vgg.py
读源码的过程中有个地方需要注意一下,即传参和返回参数规定类型(第一次看看晕了),具体可以参考一下python>=3.5之奇葩from typing import Union_浪ふ沏沙的博客-CSDN博客_typing.union
怎么判断 VGG 多少,比如为什么是 VGG16?
卷积层和全连接层具有权重系数,因此也被称为权重层,总数目为13+3=16(池化层不涉及权重,因此不属于权重层,不被计数)
2.4 NiN
全连接层的问题
- 参数过多,尤其是卷积层过后的第一个全连接层
- 容易过拟合
NiN 块
- 一个卷积层后跟两个全连接层(1 × \\times × 1 卷积,起到全连接的作用)

1 × \\times × 1 卷积
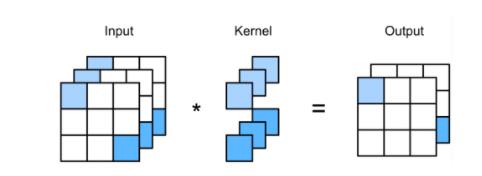
以上图为例,当 kernel_size 为 1 时,卷积已经不再具有空间性质,所以我们不妨将其拉直看,如若三个通道,则不妨令输入通道为
a
1
,
a
2
,
.
.
.
a
n
a_1, a_2, ... a_n
a1,a2,...an,
b
1
,
b
2
,
.
.
.
b
n
b_1, b_2, ... b_n
b1,b2,...bn,
c
1
,
c
2
,
.
.
.
c
n
c_1, c_2, ... c_n
c1,c2,...cn. 令对应的三个kernel值为
w
1
,
w
2
,
w
3
w_1, w_2, w_3
w1,w2,w3. 则假设经过卷积操作得到为
d
1
,
d
2
,
.
.
.
d
n
d_1, d_2, ... d_n
d1,d2,...dn, 则有
d
i
=
a
i
∗
w
1
+
b
i
∗
w
2
+
c
i
∗
w
3
d_i = a_i*w_1+b_i*w_2+c_i*w_3
di=ai∗w1+bi∗w2+ci∗w3
这其实就是全连接层的操作嘛,所以我们完全可以将
1
×
1
1 \\times 1
1×1 的卷积操作看作是参数共享的全连接层
NiN 架构
- 无全连接层
- 交替使用 NiN 块和步幅为 2 的最大池化层
- 逐步减小高宽和增大通道数
- 最后使用全局平均池化层得到输出
- 其输入通道数是类别数

相关代码部分可以参考:nin slides (d2l.ai)
2.5 GoogLeNet
Inception

Inception 不改变图片的大小
GoogLeNet 架构
Inception 有各种后续变种
- Inception-BN(v2) - 使用 batch normalization
- Inception-V3 - 修改了 Inception 块
- 替换 5 × 5 5 \\times 5 5×5 为多个 3 × 3 3 \\times 3 3×3 卷积层
- 替换 5 × 5 5 \\times 5 5×5 为 1 × 7 1 \\times 7 1×7 和 7 × 7 7 \\times 7 7×7 卷积层
- 替换 3 × 3 3 \\times 3 3×3 为 1 × 3 1 \\times 3 1×3 和 3 × 3 3 \\times 3 3×3 卷积层
- Inception-V4 - 使用残差连接
总结
- Inception 块用 4 条不同超参数的卷积层和池化层的路来抽取不同的信息
- 它的一个主要优点是模型参数小,计算复杂度低
- GoogLeNet 使用了 9 个 Inception 块,是第一个达到上白层的网络
- 后续有一系列改进
2.6 ResNet
残差块
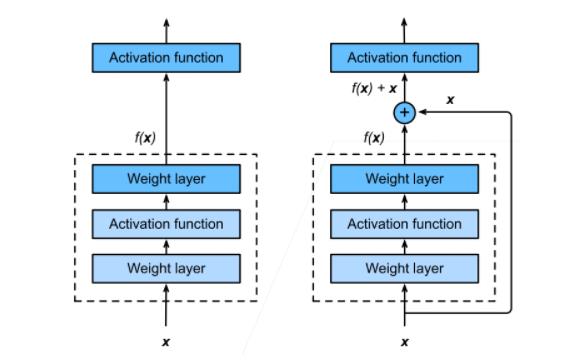

这里 1 × 1 1 \\times 1 1×1的卷积可以实现改变通道个数,从而可以实现相加操作

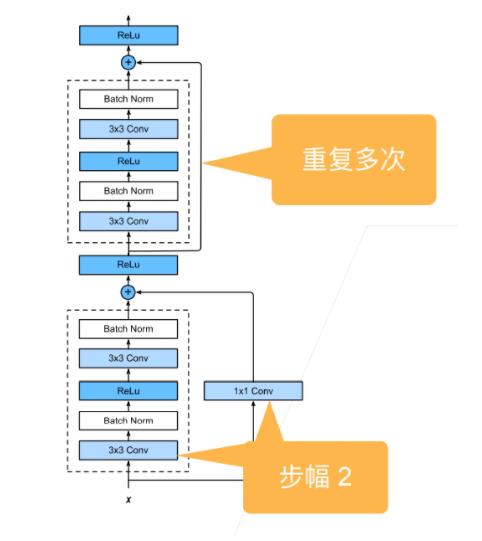
ResNet 块
- 高宽减半 ResNet 块(步幅2)
- 后接多个高宽不变的 ResNet 块
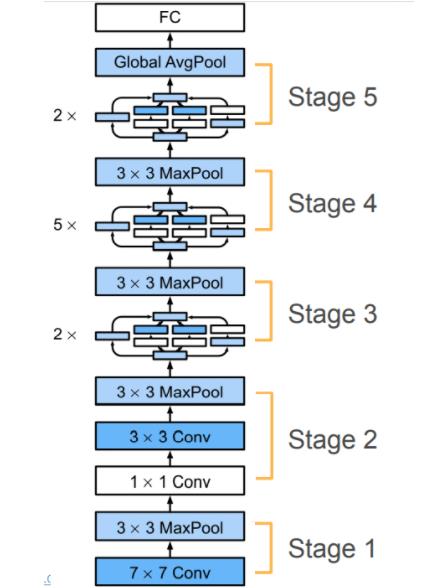
ResNet 架构
- 类似 VGG 和 GoogLeNet 的总体架构
- 但替换成了 ResNet 块

总结
- 残差块使得很深的网络更加容易训练,甚至可以训练一千层
- 残差网络对随后的深层神经网络设计产生了深远影响,无论是卷积类网络还是全连接类网络
pytorch 实现源码:https://github.com/pytorch/vision/blob/main/torchvision/models/resnet.py
以上是关于经典深度学习框架的主要内容,如果未能解决你的问题,请参考以下文章