Flink状态管理与Checkpoint实战——模拟电商订单计算过程中宕机的场景,探索宕机恢复时如何精准继续计算订单
Posted 大数据小禅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink状态管理与Checkpoint实战——模拟电商订单计算过程中宕机的场景,探索宕机恢复时如何精准继续计算订单相关的知识,希望对你有一定的参考价值。
Flink的状态与容错是这个框架很核心的知识点。其中一致检查点也就是Checkpoints也是Flink故障恢复机制的核心,这篇文章将详细介绍Flink的状态管理和Checkpoints的概念以及在生产环境中的参数设置。
什么是State状态?
- 在使用Flink进行窗口聚合统计,排序等操作的时候,数据流的处理离不开状态管理
- 是一个Operator的运行的状态/历史值,在内存中进行维护
- 流程:一个算子的子任务接收输入流,获取对应的状态,计算新的结果,然后把结果更新到状态里面
有状态和无状态介绍
-
无状态计算: 同个数据进到算子里面多少次,都是一样的输出,比如 filter
-
有状态计算:需要考虑历史状态,同个输入会有不同的输出,比如sum、reduce聚合操作
-
状态管理分类
- ManagedState(用的多)
- Flink管理,自动存储恢复
- 细分两类
- Keyed State 键控状态(用的多)
- 有KeyBy才用这个,仅限用在KeyStream中,每个key都有state ,是基于KeyedStream上的状态
- 一般是用richFlatFunction,或者其他richfunction里面,在open()声明周期里面进行初始化
- ValueState、ListState、MapState等数据结构
- Operator State 算子状态(用的少,部分source会用)
- ListState、UnionListState、BroadcastState等数据结构
- Keyed State 键控状态(用的多)
- RawState(用的少)
- 用户自己管理和维护
- 存储结构:二进制数组
- ManagedState(用的多)
-
State数据结构(状态值可能存在内存、磁盘、DB或者其他分布式存储中)
- ValueState 简单的存储一个值(ThreadLocal / String)
- ValueState.value()
- ValueState.update(T value)
- ListState 列表
- ListState.add(T value)
- ListState.get() //得到一个Iterator
- MapState 映射类型
- MapState.get(key)
- MapState.put(key, value)
- ValueState 简单的存储一个值(ThreadLocal / String)
State状态后端:存储在哪里
-
Flink 内置了以下这些开箱即用的 state backends :
-
(新版)HashMapStateBackend、EmbeddedRocksDBStateBackend
- 如果没有其他配置,系统将使用 HashMapStateBackend。
-
(旧版)MemoryStateBackend、FsStateBackend、RocksDBStateBackend
- 如果不设置,默认使用 MemoryStateBackend。
-
-
状态详解
-
HashMapStateBackend 保存数据在内部作为Java堆的对象。
- 键/值状态和窗口操作符持有哈希表,用于存储值、触发器等
- 非常快,因为每个状态访问和更新都对 Java 堆上的对象进行操作
- 但是状态大小受集群内可用内存的限制
- 场景:
- 具有大状态、长窗口、大键/值状态的作业。
- 所有高可用性设置。
-
EmbeddedRocksDBStateBackend 在RocksDB数据库中保存状态数据
- 该数据库(默认)存储在 TaskManager 本地数据目录中
- 与HashMapStateBackend在java存储 对象不同,数据存储为序列化的字节数组
- RocksDB可以根据可用磁盘空间进行扩展,并且是唯一支持增量快照的状态后端。
- 但是每个状态访问和更新都需要(反)序列化并可能从磁盘读取,这导致平均性能比内存状态后端慢一个数量级
- 场景
- 具有非常大状态、长窗口、大键/值状态的作业。
- 所有高可用性设置
-
旧版
MemoryStateBackend(内存,不推荐在生产场景使用) FsStateBackend(文件系统上,本地文件系统、HDFS, 性能更好,常用) RocksDBStateBackend (无需担心 OOM 风险,是大部分时候的选择) 代码配置: StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setStateBackend(new EmbeddedRocksDBStateBackend()); env.getCheckpointConfig().setCheckpointStorage("file:///checkpoint-dir"); //或者 env.getCheckpointConfig().setCheckpointStorage(new FileSystemCheckpointStorage("file:///checkpoint-dir")); -
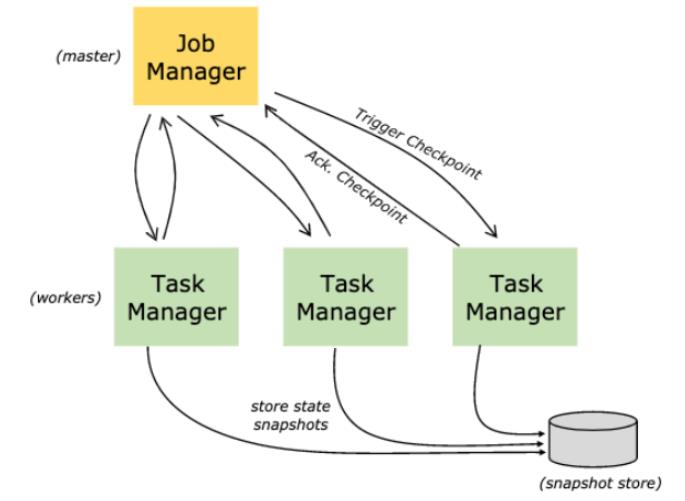
什么是Checkpoint检查点
-
Flink中所有的Operator的当前State的全局快照
-
默认情况下 checkpoint 是禁用的
-
Checkpoint是把State数据定时持久化存储,防止丢失
-
手工调用checkpoint,叫 savepoint,主要是用于flink集群维护升级等
-
底层使用了Chandy-Lamport 分布式快照算法,保证数据在分布式环境下的一致性
-
有状态流应用的一致检查点,其实就是所有任务的状态,在某个时间点的一份 拷贝(一份快照);这个时间点,应该是所有任务都恰好处理完一个相同的输入数据的时候
Flink 捆绑的些检查点存储类型:
- 作业管理器检查点存储 JobManagerCheckpointStorage
- 文件系统检查点存储 FileSystemCheckpointStorage
端到端(end-to-end)状态一致性
数据一致性保证都是由流处理器实现的,也就是说都是在Flink流处理器内部保证的
在真实应用中,了流处理器以外还包含了数据源(例如Kafka、mysql)和输出到持久化系统(Kafka、Mysql、Hbase、CK)
端到端的一致性保证,是意味着结果的正确性贯穿了整个流处理应用的各个环节,每一个组件都要保证自己的一致性。
- Source
- 需要外部数据源可以重置读取位置,当发生故障的时候重置偏移量到故障之前的位置
- 内部
- 依赖Checkpoints机制,在发生故障的时可以恢复各个环节的数据
- Sink:
- 当故障恢复时,数据不会重复写入外部系统,常见的就是 幂等和事务写入(和checkpoint配合)
有关检查点配置的常用参数配置介绍
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置checkpoint的周期, 每隔1000 ms进行启动一个检查点
env.getCheckpointConfig().setCheckpointInterval(1000);
// 设置状态级别模式为exactly-once
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//超时时间,可能是保存太耗费时间或者是状态后端的问题,任务同步执行不能一直阻塞
env.getCheckpointConfig().setCheckpointTimeout(60000L);
// 设置取消和故障时是否保留Checkpoint数据,这个设置较为重要,没有正确的选择好可能会导致检查点数据失效
//有两个参数可以设置
//ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION: 取消作业时保留检查点。必须在取消后手动清理检查点状态。
//ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION: 取消作业时删除检查点。只有在作业失败时,检查点状态才可用。
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
实战部分:
为了模拟生产环境中实时产生的订单数据,这里我们自己定义一个数据源来源源不断的产生模拟订单数据
订单类:
@Data
@AllArgsConstructor
@NoArgsConstructor
public class VideoOrder
private String tradeNo;
private String title;
private int money;
private int userId;
private Date createTime;
@Override
public String toString()
return "VideoOrder" +
"tradeNo='" + tradeNo + '\\'' +
", title='" + title + '\\'' +
", money=" + money +
", userId=" + userId +
", createTime=" + createTime +
'';
public class VideoOrderSourceV2 extends RichParallelSourceFunction<VideoOrder>
private volatile Boolean flag = true;
private Random random = new Random();
private static List<VideoOrder> list = new ArrayList<>();
static
list.add(new VideoOrder("","java",10,0,null));
list.add(new VideoOrder("","spring boot",15,0,null));
/**
* run 方法调用前 用于初始化连接
* @param parameters
* @throws Exception
*/
@Override
public void open(Configuration parameters) throws Exception
System.out.println("-----open-----");
/**
* 用于清理之前
* @throws Exception
*/
@Override
public void close() throws Exception
System.out.println("-----close-----");
/**
* 产生数据的逻辑
* @param ctx
* @throws Exception
*/
@Override
public void run(SourceContext<VideoOrder> ctx) throws Exception
while (flag)
Thread.sleep(1000);
String id = UUID.randomUUID().toString().substring(30);
int userId = random.nextInt(10);
int videoNum = random.nextInt(list.size());
VideoOrder videoOrder = list.get(videoNum);
videoOrder.setUserId(userId);
videoOrder.setCreateTime(new Date());
videoOrder.setTradeNo(id);
System.out.println("产生:"+videoOrder.getTitle()+",价格:"+videoOrder.getMoney()+", 时间:"+ TimeUtil.format(videoOrder.getCreateTime()));
ctx.collect(videoOrder);
/**
* 控制任务取消
*/
@Override
public void cancel()
flag = false;
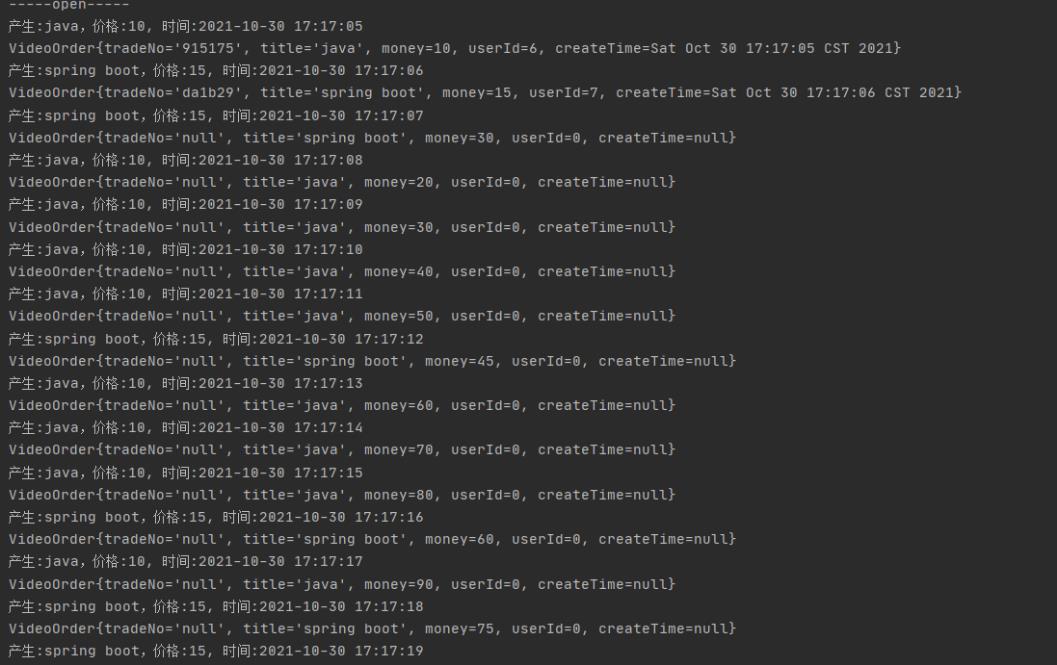
产生数据的格式如下:

主程序:使用reduce算子对数据进订单价格进行滚动计算,并设置Checkpoint保证数据状态可以存取
public class FlinkKeyByReduceApp
/**
* source
* transformation
* sink
*
* @param args
*/
public static void main(String[] args) throws Exception
//构建执行任务环境以及任务的启动的入口, 存储全局相关的参数
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
env.enableCheckpointing(5000);
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//这是我本机的ip地址
env.getCheckpointConfig().setCheckpointStorage(new FileSystemCheckpointStorage("hdfs://192.168.192.100:8020/checkpoint"));
DataStreamSource<VideoOrder> ds = env.addSource(new VideoOrderSourceV2());
KeyedStream<VideoOrder, String> videoOrderStringKeyedStream = ds.keyBy(new KeySelector<VideoOrder, String>()
@Override
public String getKey(VideoOrder value) throws Exception
return value.getTitle();
);
SingleOutputStreamOperator<VideoOrder> reduce = videoOrderStringKeyedStream.reduce(new ReduceFunction<VideoOrder>()
@Override
public VideoOrder reduce(VideoOrder value1, VideoOrder value2) throws Exception
VideoOrder videoOrder = new VideoOrder();
videoOrder.setTitle(value1.getTitle());
videoOrder.setMoney(value1.getMoney() + value2.getMoney());
return videoOrder;
);
reduce.print();
env.execute("job");
在本地测试运行结果,可以看到数据根据订单分组不断的进行滚动计算
进入服务器的HDFS查看检查点数据是否存在

之后将应用进行打包,上传到服务器进行测试,可以使用Flink的Web页面进行手动提交jar包运行,也可以使用命令进行提交,之后可以看到程序运行过程中的相关日志输出
./bin/flink run -c net.xxx.xxx.FlinkKeyByReduceApp -p 3 /xiaochan-flink.jar

模拟宕机
运行程序的时候我们可以在Flink看到任务进行的id号,这个时候我们手动的cancel掉或者是直接把服务kill掉,这个时候任务被强制暂停。
进入到HDFS可以看到我们设置的检查点的数据依旧存在,我们使用如下命令,让程序从上次宕机前的订单计算状态继续往下计算。
-s : 指定检查点的元数据的位置,这个位置记录着宕机前程序的计算状态
./bin/flink run -s /checkpoint/id号/chk-23/_metadata -c net.xxx.xxx.FlinkKeyByReduceApp -p 3 /root/xdclass-flink.jar

运行命令,进入WEB页面进行查看,是否成功。

可以看到出现一次close的时候,代表我们的程序以及停止,服务器已经宕机,这个时候订单的计算结果如上图的红色方框。在我们运行了上面那条命令后再次查看日志的数据,从open开始可以看到这次就不是从订单最初的状态开始进行的了,而是从上一次宕机前计算的结果,继续往下计算,到这里Checkponit的实战应用测试就完成了。
以上是关于Flink状态管理与Checkpoint实战——模拟电商订单计算过程中宕机的场景,探索宕机恢复时如何精准继续计算订单的主要内容,如果未能解决你的问题,请参考以下文章