不容错过!动画图文展示 MapReduce 核心思想 & Hadoop 实践
Posted 东海陈光剑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了不容错过!动画图文展示 MapReduce 核心思想 & Hadoop 实践相关的知识,希望对你有一定的参考价值。
MapReduce with Hadoop
Lets start by introducing a cluster with data distributed among them. We want
to process this data. Our objective may be here to figure how many objects there are per geometric shape
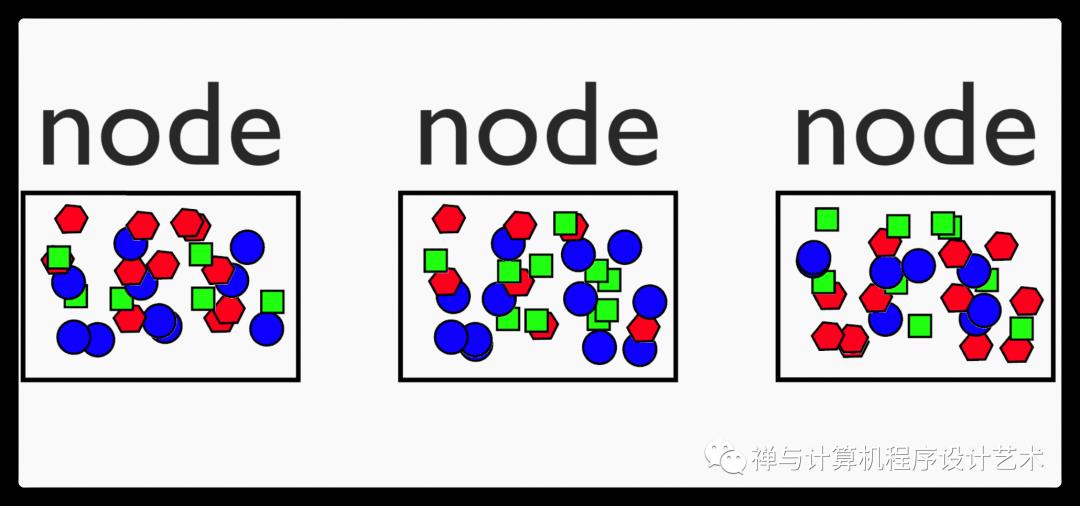
MapReduce is a cornerstone algorithm used to process big datasets. It is the grandfather of most of our big data technologies today, and sparked during the early 2000s the way to the data driven world we see today. The most popular MapReduce “engine” is Hadoop.
For this blogpost I will be taking a look at how MapReduce works, what Hadoop is, discuss it while we’re trying things out, and finally we’ll run a simple MapReduce in Hadoop on Google Cloud DataProc.
Concept
MapReduce is as the name suggest a method for distributed processing through a mapping and reduce phase. In addition to this, there is a shuffle phase which is most often hidden for the programmer.
1.Mapping phase
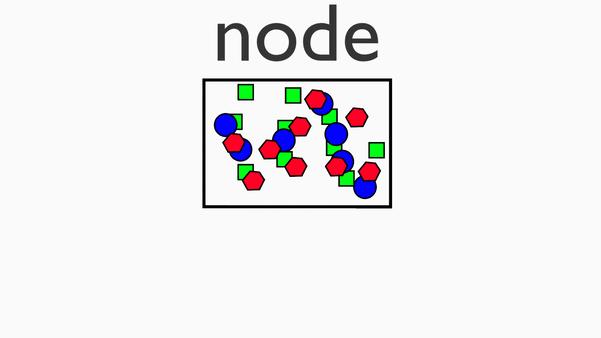
2.The Shuffle Stage
Once each node has mapped its data, there is a hidden shuffle stage - where the nodes share their mapped data to appropriate nodes in the cluster. The shuffle stage is hidden for us as programmers - we are tasked with providing the map and reduce functions.
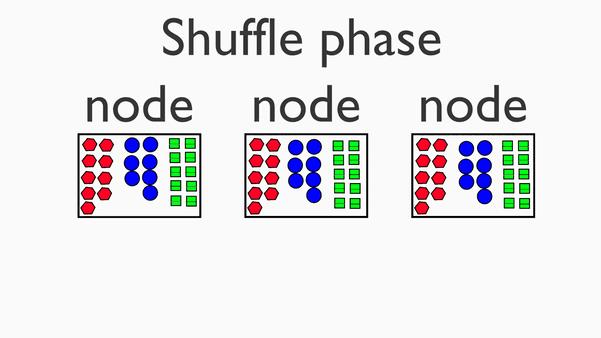
Finally once nodes have access to the appropriate data they are tasked with computing, the reduce phase can commence:
3.Reduce phase
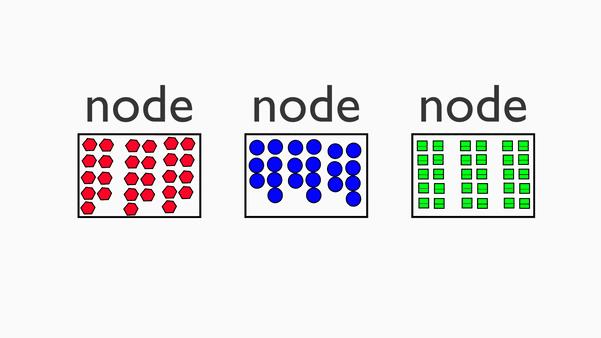
Cool! Note that we as programmers have access to the mapper and reduce phase and can program appropriate code here to answer the business inquiry in question.
Quick note on Distributed Filesystems
HDFS, or Hadoop Distributed FileSystem, is often first discussed before introducing MapReduce. But this is my blogpost, and Ill do whatever I want, and I want to make a post on unstructured data and distributed filesystems later. However as a quick primer, just think of HDFS as a distributed way to split files using master/slaves (or DataNodes and NameNodes) with redundancy etc.
Hadoop is the building block which provides implementations for HDFS and MapReduce, and a lot of other tech is built on top of Hadoop - which is kinda how it turned into this whole ecosystem of its own. Lets do a quick discussion on Hadoop (with myself) before we run a WordCount program on Hadoop locally and in the cloud using GCP DataProc.
Implementation using Hadoop
An introduction to Hadoop
Hadoop is one of the majorly adopted frameworks for big data processing, and the Hadoop ecosystem is a lot to get into. In its core, Hadoop provides us functionality for processing data with MapReduce - along with the Hadoop Distributed FileSystem aka. HDFS. Along with this, there are many technologies built on top of or along with Hadoop to extend it - such as YARN for resource management, HBase for distributed and scalable KV stores on HDFS, or Hive for SQL interface to Hadoop to name a few.
Running Hadoop WordCount
Lets run Wordcount with Hadoop mapreduce locally to get a feel for the technology, and how to implement this. NOTE: Seems most people are not doing good old MapReduce on Hadoop anymore, as more newer technologies have come to exist. I’m just curious for historic reasons. BTW, you should be running Linux for this (I have an arch setup)
Copy the command below to your terminal. Dont worry - there is no malware. I promise. Pinky swear. (if youre reading this youre already likely hooked on my google analytics. I’m watching you!)
cd $(mktemp -d) && git clone git@github.com:peakBreaker/HadoopBasics.git && cd HadoopBasics/mapreduce_wc/ && \\
mvn clean compile exec:java -D"exec.mainClass"="com.peakbreaker.WordCount" -D"exec.args"="$(pwd)/../sample_data/ $(pwd)/wordcount/" && \\
echo "WordCount successful! Inspect ouput folder and see job output below:" && \\
cat $(pwd)/wordcount/*Congrats on running MapReduce! Go ahead and reverse engineer the code, or read on to get a deeper insight into hadoop mapreduce.
The Full Walkthrough
Most software usually have their own “Hello, world!” version to get grips on the core concepts of the technology. In 3D it is the teapot, in programming it is printing out “Hello, World!”, in SQL it is “SELECT * FROM Users;” while in SQL Injection it is “Robert’); DROP TABLE Students;–”. Big data is no different, with WordCount being the de facto “Hello, World!”. Below we are going to run WordCount in Java with Maven using MapReduce in Hadoop on DataProc with data from GCS (in DataProc GCS can replace HDFS, which is very handy).
Notice above, dear business guy or whatever, that doing even the simplest things in Big Data requires at the minimum of 6 technologies compared to a web developers 1 or 2. The complexity of Big Data applications is not to underestimated, and if you expect the same cost/risk from big data applications as regular web apps, then you must know I have a very particular set of skills.

Okay, lets get started. For this you must have maven and java installed. I am using openjdk 11.0.6 2020-01-14 when running this. For Java I suggest getting an IDE such as Eclipse or IntelliJ. This is sad as I am a vim guy myself, but Java is just too verbose and too dependent on IDEs to be efficient in vim, so I just use an IDE for it. Dont worry, I use vim for pretty much everything else.
Start by setting up the Maven Project. I wont get into how Java and Maven and all of that stuff works, just follow my guide from scratch below. First begin by letting maven spew some stuff onto your disk:
$ mvn archetype:generate -DarchetypeGroupId=org.apache.maven.archetypes -DgroupId=com.test.wordcount -DartifactId=wordcount
Now we need to update the pom.xml maven config dependency file. Just
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.2.0</version>
</dependency>And plugins:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<configuration>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<mainClass>com.peakbreaker.WordCount</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>Aaaaaaand add the Java MapReduce program. This would be under ./src/java/com/peakbreaker-sample/WordCount.java (gotta love those long paths in Java, right?)
| |
Notice and study the mapper and reducer in the program - those handle the map and reduce phase. Now since we are trying to keep the complexity to a minimum here, the argparse isnt perfect, but the first arg of the program is the input file and the second one is the output file.
Lets try to run the program locally first - Create some test data for demonstration and run the wordcount on it.
Mockdata:$ mkdir -p $(pwd)/folder/with/textdata/ && echo -e “Hello, this is some text that is very awesome to count.\\n A quick fox jumped over a lazy lorem ipsum, right?” > $(pwd)/folder/with/textdata/sample.txt
Aaaaaaaaaaand lets run it!
$ mvn clean compile exec:java -D"exec.mainClass"="com.test.wordcount.WordCount" -D"exec.args"="$(pwd)/folder/with/textdata $(pwd)/wordcount/"
And there should be some output in the destination path:
$ cat wordcount/*
A 1
Hello, 1
a 1
awesome 1
count. 1
fox 1
ipsum, 1
is 2
jumped 1
lazy 1
lorem 1
over 1
quick 1
right? 1
some 1
text 1
that 1
this 1
to 1
very 1Cool! If youve gotten this far, then congrats and awesome! Youve run Mapreduce locally. Now we need to run it in the cloud on a Hadoop cluster. As the title suggest, and since the good folks at Google Cloud provide a handy managed Hadoop service, we can run it there.
Aaaaaaaaand lets run in the cloud on DataProc!
To run the job on dataproc we must first have a cluster, a GCS bucket with input data, and one for output data. Lets do a wordcount on some public data provided by google for testing purposes. Make sure you have the gcloud sdk installed for this.
Lets set some configs first:
export GCP_PROJECT=<my_project>
export CLUSTER_NAME=tmpcluster-hadoop-wordcount
export GCP_REGION=europe-north1
export GCP_ZONE=europe-north1-a
export IN_BUCKET=demobucket-hadoop-wordcount-in
export OUT_BUCKET=demobucket-hadoop-wordcount-outSet up bucket:
gsutil mb -l $GCP_REGION -p $GCP_PROJECT gs://$IN_BUCKET
gsutil mb -l $GCP_REGION -p $GCP_PROJECT gs://$OUT_BUCKET
gsutil -m cp gs://pub/shakespeare/*.txt gs://$IN_BUCKET/input-shakespeareSet up Dataproc cluster (just using a single node now for demo purposes) and output bucket:$ g gcloud dataproc clusters create $CLUSTER_NAME --region $GCP_REGION --subnet default --zone $GCP_ZONE --single-node --master-machine-type n1-standard-1 --master-boot-disk-size 15 --image-version 1.3-deb9 --project $GCP_PROJECT
Aaaaaaand lets run it!
$ mvn clean install && gcloud dataproc jobs submit hadoop --region europe-north1 --cluster $CLUSTER_NAME --class com.test.wordcount.WordCount --jars target/wordcount-1.0-SNAPSHOT.jar -- gs://$IN_BUCKET/input-shakespeare gs://$OUT_BUCKET/output-shakespeare-wc/
Youll get some logs and the output bucket should have the results after running:gsutil cat gs://demobucket-hadoop-wordcount-out/output-shakespeare-wc/part-r-00000
Check the output bucket now and check that the output data is there. If it is, then congrats on losing your Hadoop virginity!
Finally remember to clean up the resources:
gsutil rb gs://$IN_BUCKET
gsutil rb gs://$OUT_BUCKET
gcloud dataproc clusters delete $CLUSTER_NAME --quiet --region $GCP_REGIONThanks for reading
以上是关于不容错过!动画图文展示 MapReduce 核心思想 & Hadoop 实践的主要内容,如果未能解决你的问题,请参考以下文章