numpy 笔记 view,copy和numpy的运行速度
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了numpy 笔记 view,copy和numpy的运行速度相关的知识,希望对你有一定的参考价值。
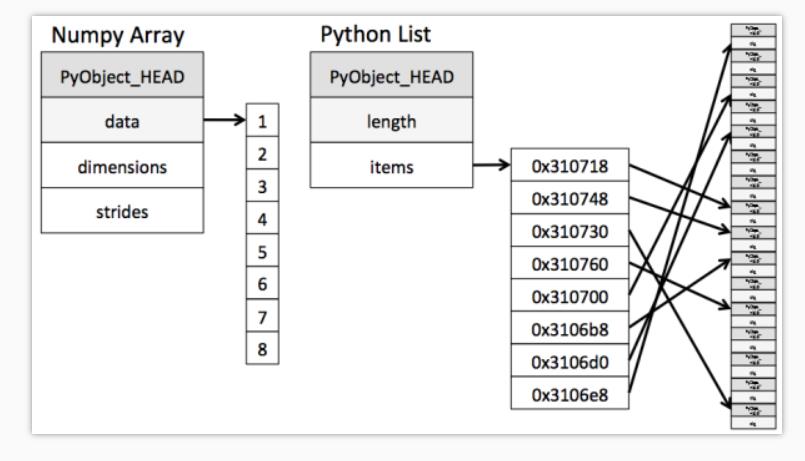
1 ndarray VS python-list
- Numpy 就是 C 的逻辑, 创建存储容器 Array 的时候是寻找内存上的一段连续空间来存放
- Python 存放的时候则是不连续的区域(只是它用索引将这些区域联系起来了), 这使得 Python 在索引这个容器里的数据时不是那么有效率
2 View & Copy
Copy 顾名思义, 会将 Array 中的数据 copy 出来存放在内存中另一个地方
View 不 copy 数据, 而是给源数据加一个窗(视图),从外面看窗户里的数据。具体来说,view 不会新建数据,而只是在源数据上建立索引部分。
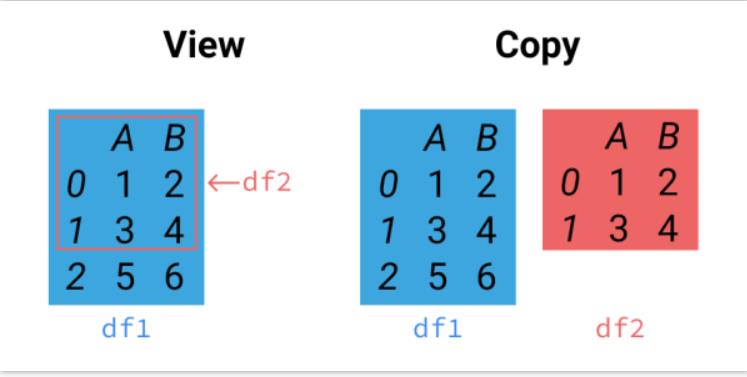
df1经过view 之后得到的df2全部都是 df1的东西, 动 df2的任何地方, df1 都会受到牵扯, 因为他们在内存中的位置是一模一样的, 本质上就是自己。
而 df1经过copy 之后得到的df2则是将df1 copy 了一份, 然后把df2 放在内存中的另外的地方, 这样改变df2,df1 是不会被改变的.
2.1 示例比较view和copy的快慢
View 只是加了窗,不会复制东西, 速度快!
2.1.1 b=2*b VS b*=2
第一个是copy,第二个是view!
b=np.ones(5)
print(id(b))
b=b*2
print(id(b))
'''
1921309681504
1921309680624
'''b=np.ones(5)
print(id(b))
b*=2
print(id(b))
'''
1921285077472
1921285077472
'''2.1.2 比较时间
import time
t1=time.time()
b=np.ones(1000)
for i in range(1000):
b=b*2
t2=time.time()
print(t2-t1)
#0.0029931068420410156
b=np.ones(1000)
t2=time.time()
for i in range(1000):
b*=2
t3=time.time()
print(t3-t2)
#0.001993894577026367可以看到 view比copy用时要少一些
2.2 示例比较flatten和ravel的快慢
在python包介绍:numpy_UQI-LIUWJ的博客-CSDN博客 中,提到了flatten和ravel
flatten返回一份数据拷贝,对拷贝所做的修改不影响原始数组
ravel和flatten差不多,唯一的区别是,修改会影响原始数组
也就是说,flatten是拷贝,ravel是视图
import time
t1=time.time()
b=np.ones(1000)
for i in range(1000):
b.flatten()
t2=time.time()
print(t2-t1)
#0.0009980201721191406
b=np.ones(1000)
t2=time.time()
for i in range(1000):
b.ravel()
t3=time.time()
print(t3-t2)
#0.0009784698486328125也看得出来,ravel(view)的运行速度比flatten(copy)要快一些
2.3 总结 哪些是view哪些是copy
| view | copy |
| 切片操作 (切片索引不涉及列表) | 切片操作,切片索引涉及列表 |
| 布尔索引 | |
| |
| |
2.4 涉及列表的索引的加速方法——np.take
如果用 index 来选数据, 像 a[[1,4,6], [2,4,6]], 用 take 在大部分情况中会快一些
np.take(ndarray,index_lst)
import time
b=np.ones(100).reshape(10,10)
t1=time.time()
for i in range(1000):
b[[1,2,3,4],[5,6,7,8]]
t2=time.time()
print(t2-t1)
#0.0069811344146728516
b=np.ones(100).reshape(10,10)
lst=[[1,2,3,4],[5,6,7,8]]
t2=time.time()
for i in range(1000):
np.take(b,lst)
t3=time.time()
print(t3-t2)
#0.005984067916870117参考内容 对速度有洁癖?快来了解 Numpy 的 View 与 Copy - Numpy 数据怪兽 | 莫烦Python (mofanpy.com)
以上是关于numpy 笔记 view,copy和numpy的运行速度的主要内容,如果未能解决你的问题,请参考以下文章