Spring Data JDBC 详解
Posted Dream_it_possible!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spring Data JDBC 详解相关的知识,希望对你有一定的参考价值。
目录
二、Spring Boot 整合Spring data JDBC
2) PagingAndSortingRepository 分页排序
一、JPA背景
早期的JPA的特性是懒加载和关联查询,一下能查出所有的关联信息,但我们开发者在查询SQL的时候往往只需要某几个字段,而JPA甚至关联表的所有字段查询出来,如果不需要那么多message,那么查询的性能会大大降低。
Spring官网为此提供了另一个解决方案——spring-data-jdbc, 另一种形式的Java持久化的API工具集,相比JPA来讲,更简单,更高效,没有session, 一次查询查询出指定的结果,没有多余数据,Spring 官网提供了为什么使用它的理由:
1. If you load an entity, SQL statements get run. Once this is done, you have a completely loaded entity. No lazy loading or caching is done.
2. If you save an entity, it gets saved. If you do not, it does not. There is no dirty tracking and no session.
3. There is a simple model of how to map entities to tables. It probably only works for rather simple cases. If you do not like that, you should code your own strategy. Spring Data JDBC offers only very limited support for customizing the strategy with annotations.
简单总结就是: 没有拦截在和缓存,每次执行完的SQL得到的就是一个指定想要的完整实体,没有关联的查询或更新操作 ,没有session, 更简单、高效。
spring-data-jdbc相比mybatis有哪些好处?
其实现在有更好的中间件mybatis和相关插件能够帮助我们更好的执行sql, spring-data-jdbc和mybatis同样是基于spring开发出来的框架,那么他们优势和差别分别是什么?
- mybatis: sql与mapper层分离,开发者可以编写复杂的SQL以及动态SQL,适合查询复杂的场景,能够在xml文件里统一管理SQL文件,缺点是有些场景下需要编写复杂的SQL。
- spring-data-jdbc: 无须配置和加载xml映射文件, 简化开发,对于单表查询多的场景下,使用spring-boot-data-jdbc会比mybatis更加简单,另外spring-boot-data-jdbc能够与mybatis做集成,使用更加灵活,支持配置SqlSessionFactoryBean。缺点是: 复杂的业务系统和场景下,复杂的SQL难以维护。
Spring-data-jdbc在简单业务场景下的表现会比myabtis更加方便、好用。
二、Spring Boot 整合Spring data JDBC
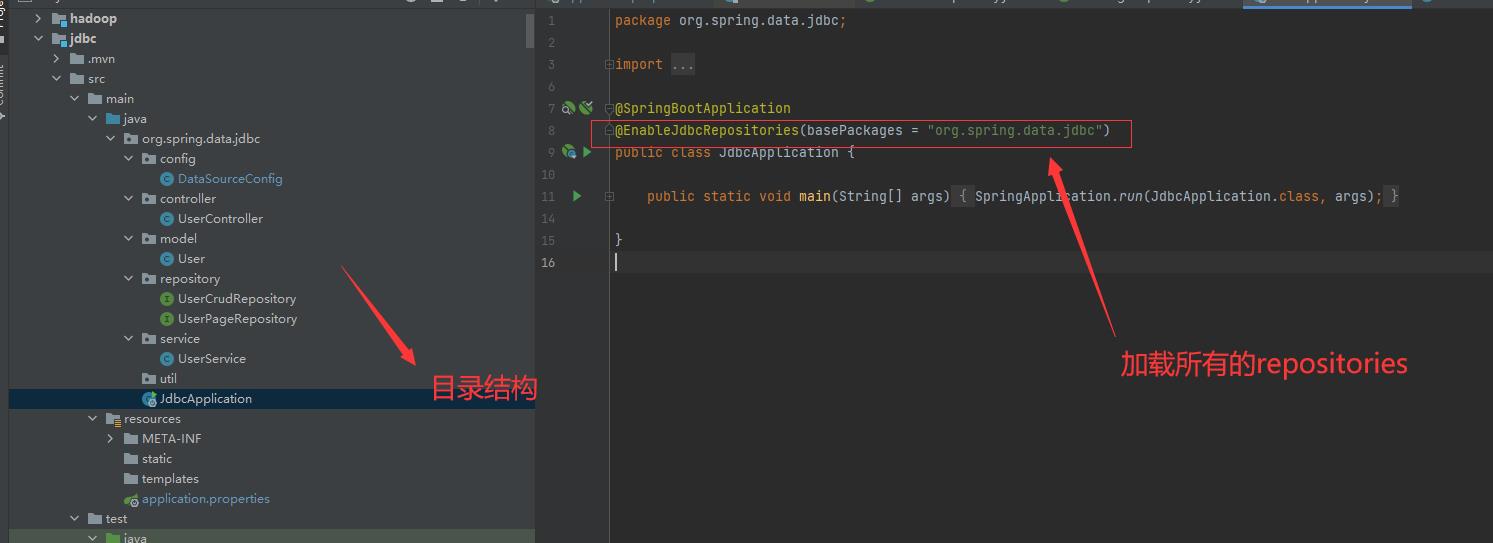
先看一下目录结构:
jdbc
├─ JdbcApplication.java // main方法
├─ config
│ └─ DataSourceConfig.java // 配置数据源,采用druid
├─ controller
│ └─ UserController.java // controler
├─ model
│ └─ User.java // 实体类
├─ repository // dao层,与数据库连接层
│ ├─ UserCrudRepository.java
│ └─ UserPageRepository.java
├─ service // 服务层
│ └─ UserService.java
└─ util启动类的@EnableJdbcRepositories(basePackages = "org.spring.data.jdbc") 注解也可以放在配置类上。
1. 配置数据源
数据库使用mysql,那么首推alibaba的druid数据源,druid是国内数据库连接性能表现最好且功能强大数据库中间件,druid还有自带的数据库监控工具,能够监控慢sql,sql执行的动态还有预防sql注入攻击等功能。
添加pom依赖:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!-- alibaba druid数据源-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.18</version>
</dependency>
<!--spring-data-jdbc-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jdbc</artifactId>
</dependency>添加数据源配置:
server.port=8002
spring.datasource.url=jdbc:mysql://192.168.31.166:3306/my_shop?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai
spring.datasource.username=root
spring.datasource.password=123456
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
下载好jar包后,新建一个配置类DataSourceConfig:
package org.spring.data.jdbc.config;
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.support.http.StatViewServlet;
import com.alibaba.druid.support.http.WebStatFilter;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.boot.web.servlet.ServletRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.jdbc.repository.config.AbstractJdbcConfiguration;
import org.springframework.data.jdbc.repository.config.EnableJdbcRepositories;
import org.springframework.jdbc.core.namedparam.NamedParameterJdbcOperations;
import org.springframework.jdbc.core.namedparam.NamedParameterJdbcTemplate;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
import org.springframework.transaction.TransactionManager;
import javax.sql.DataSource;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
@Configuration
@EnableJdbcRepositories(basePackages = "org.spring.data.jdbc")
public class DataSourceConfig extends AbstractJdbcConfiguration
/**
* 采用阿里数据源druid
*
* @return
*/
@ConfigurationProperties("spring.datasource")
@Bean
DataSource dataSource()
return new DruidDataSource();
/**
* Jdbc Template
* @param dataSource
* @return
*/
@Bean
NamedParameterJdbcOperations namedParameterJdbcOperations(DataSource dataSource)
return new NamedParameterJdbcTemplate(dataSource);
/**
* 事务管理器
* @param dataSource
* @return
*/
@Bean
TransactionManager transactionManager(DataSource dataSource)
return new DataSourceTransactionManager(dataSource);
2. 配置Druid的admin后台
Druid提供了一种直接重写ServletRegistrationBean和FilterRegistrationBean的方式来生成admin后台管理页面和过滤器。
//配置Druid监控
//admin后台, 访问地址: localhost:8002/druid/
@Bean
public ServletRegistrationBean statViewServlet()
ServletRegistrationBean bean = new ServletRegistrationBean<>(new StatViewServlet(), "/druid/*");
Map<String, String> initParams = new HashMap<>();
initParams.put("loginUsername", "admin");
initParams.put("loginPassword", "admin");
initParams.put("allow", "localhost");
initParams.put("deny", "0.0.0.0");
bean.setInitParameters(initParams);
return bean;
//filter
@Bean
public FilterRegistrationBean webStatFilter()
FilterRegistrationBean bean = new FilterRegistrationBean();
bean.setFilter(new WebStatFilter());
Map<String, String> initParams = new HashMap<>();
initParams.put("exclusions", "*.js,*.css,/druid/*");
bean.setInitParameters(initParams);
bean.setUrlPatterns(Arrays.asList("/*"));
return bean;
访问地址: localhost:8002/druid, 即可进入到admin后台管理页面,如下:

输入配置的账号admin,密码admin即可进入到首页, 如下图: 
3. Spring-data-jdbc常用接口查询策略
1) CrudRepository 增删改查
我们可以通过继承CrudRepository来定义基于Model的增删改查操作, 也可以使用CrudRepository里提供对数据库增、删、改查操作的基本API。
@NoRepositoryBean
public interface CrudRepository<T, ID> extends Repository<T, ID>
<S extends T> S save(S entity);
<S extends T> Iterable<S> saveAll(Iterable<S> entities);
Optional<T> findById(ID id);
boolean existsById(ID id);
Iterable<T> findAll();
Iterable<T> findAllById(Iterable<ID> ids);
long count();
void deleteById(ID id);
void delete(T entity);
void deleteAllById(Iterable<? extends ID> ids);
void deleteAll(Iterable<? extends T> entities);
void deleteAll();
自定义接口方法:
@Repository
public interface UserCrudRepository extends CrudRepository<User, String>
User findUserById(Integer id);
@Query("select user_name as userName from sys_user where id = :id")
String findUserNameById(@Param("id") Integer id);
spring-data-jdbc的方便好用、可扩展性进一步显现出来了,如果想分页查询的话,Spring-data-jdbc提供了另外一个接口PagingAndSortingRepository,也可以使用@Query()注解支持原生的sql写入,参数使用过@Param()注入,接收的时候按照顺序接收,但要用 :id来标记接收对应的参数。
2) PagingAndSortingRepository 分页排序
@NoRepositoryBean
public interface PagingAndSortingRepository<T, ID> extends CrudRepository<T, ID>
Iterable<T> findAll(Sort sort);
Page<T> findAll(Pageable pageable);
同样的该接口类似于CrudRepository接口的用法,可以使用自带的api,也可以扩展。
package org.spring.data.jdbc.repository;
import org.spring.data.jdbc.model.User;
import org.springframework.data.repository.PagingAndSortingRepository;
public interface UserPageRepository extends PagingAndSortingRepository<User,String>
//按照id排序
排序: 提供了findAll()方法,Sort.Direction.ASC表示升序,Sort.Direction.DESC表示降序。
/**
* 按照指定字段排序,可以指定升序、降,0升序,1降序
*
* @param sortField 按照指定字段排序
* @param sortRule 排序规则
* @return
*/
public List<User> findUserBySort(String sortField, Integer sortRule)
List<User> results = new ArrayList<>();
Iterable<User> userIterable = userPageRepository.findAll(Sort.by(sortRule == 0 ? Sort.Direction.ASC : Sort.Direction.DESC, sortField));
Iterator<User> userIterator = userIterable.iterator();
while (userIterator.hasNext())
results.add(userIterator.next());
return results;
分页:直接使用import org.springframework.data.domain.Pageable 类作为参数解析分页的page和size就能实现一个简单的分页查询。
public List<User> findUserByPage(Pageable page)
return userPageRepository.findAll(page).getContent();
controller:
/**
* find all user by page
*/
@GetMapping("/findAllUser/by/page")
@ResponseBody
public List<User> findAllUserBySort(Pageable pageable)
return userService.findUserByPage(pageable);
按照id降序排序查询, 访问: localhost:8002/api/user/findAllUser/by/sort?sortRule=0&sortField=id,打印结果:
[
"id": 3,
"userName": "zhang san"
,
"id": 2,
"userName": "zhang san"
,
"id": 1,
"userName": "bingbing"
]
以上是关于Spring Data JDBC 详解的主要内容,如果未能解决你的问题,请参考以下文章
Spring NamedParameterJdbcTemplate详解
Spring NamedParameterJdbcTemplate详解(10)