CUDA入门
Posted mutourend
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CUDA入门相关的知识,希望对你有一定的参考价值。
1. 引言
CUDA为a platform and programming model for CUDA-enabled GPUs。该平台通过GPU来进行计算。CUDA为GPU编程和管理 提供C/C++语言扩展和API。
CUDA编程中,会同时使用CPU和GPU进行计算:
- CPU system:称为host。
- GPU system:称为device。
CPU和GPU为独立的系统,具有各自的内存空间。通常,在CPU上运行的串行工作,而降并行计算卸载给GPU。
2. CUDA和C对比
以Hello world程序为例:
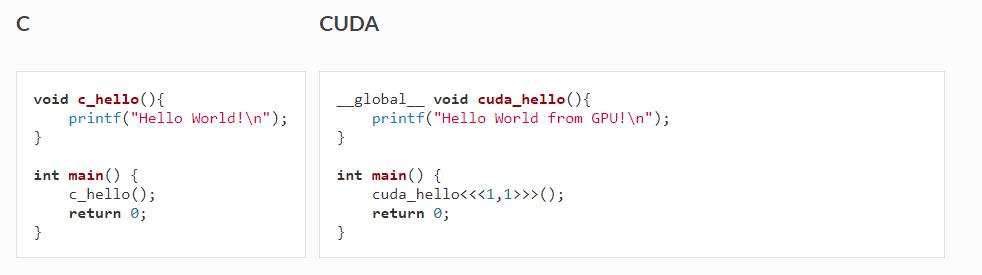
二者最大的不同在于__global__说明符 和 <<<...>>>语法:
__global__说明符:用于标明该函数运行于device(GPU)。这类函数可通过host code调用,如通过main()函数调用。也可被称为“kernels”。<<<...>>>语法:当kernel被调用时,其执行配置由<<<...>>>语言提供,如cuda_helo<<<1,1>>>()。在CUDA术语中,这被称为“kernel launch”。
编译CUDA程序与编译C语言类似。NVIDIA在其CUDA toolkit中提供了名为nvcc的CUDA编译器来编译CUDA code——通常源代码文件名为.cu。
以vector addition为例,相应的C语言实现为(vector_add.c):
#define N 10000000
void vector_add(float *out, float *a, float *b, int n)
for(int i = 0; i < n; i++)
out[i] = a[i] + b[i];
int main()
float *a, *b, *out;
// Allocate memory
a = (float*)malloc(sizeof(float) * N);
b = (float*)malloc(sizeof(float) * N);
out = (float*)malloc(sizeof(float) * N);
// Initialize array
for(int i = 0; i < N; i++)
a[i] = 1.0f; b[i] = 2.0f;
// Main function
vector_add(out, a, b, N);
对应的CUDA程序(vector_add.cu)若为:
#define N 10000000
__global__ void vector_add(float *out, float *a, float *b, int n)
for(int i = 0; i < n; i++)
out[i] = a[i] + b[i];
int main()
float *a, *b, *out;
// Allocate memory
a = (float*)malloc(sizeof(float) * N);
b = (float*)malloc(sizeof(float) * N);
out = (float*)malloc(sizeof(float) * N);
// Initialize array
for(int i = 0; i < N; i++)
a[i] = 1.0f; b[i] = 2.0f;
// Main function
vector_add<<<1,1>>>(out, a, b, N);
但是,以上CUDA程序并无法运行,因为CPU和GPU为不同的实体,二者具有各自的内存空间。CPU无法直接访问GPU内存,GPU也无法直接访问CPU内存。在CUDA术语中:
- CPU内存:称为host memory。指向CPU内存的指针称为host pointer。
- GPU内存:称为device memory。指向GPU内存的指针称为device pointer。
GPU想访问的数据因存储在device memory中。CUDA提供了API来分配device memory,并进行host memory和device memory之间的数据传送。
CUDA程序的基本流程为:
- 1)分配host memory并初始化host data。
- 2)分配device memory:可通过
cudaMalloc()和cudaFree()来分配和释放device memory。分别于C语言中的malloc()和free()对应。
cudaMalloc(void **devPtr, size_t count);
cudaFree(void *devPtr);
- 3)内存转换:将host data由host memory 传送至 device memory。可通过
cudaMemcpy函数来实现数据拷贝,类似于C语言中的memcpy。
// kind表示方向,为`cudaMemcpyHostToDevice` 或 `cudaMemcpyDeviceToHost`
cudaMemcpy(void *dst, void *src, size_t count, cudaMemcpyKind kind)
- 4)运行kernels。
- 5)将device memory执行的结果输出到host memory。
根据以上流程,对应的CUDA程序(vector_add.cu)需修改为:
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <assert.h>
#include <cuda.h>
#include <cuda_runtime.h>
#define N 10000000
#define MAX_ERR 1e-6
__global__ void vector_add(float *out, float *a, float *b, int n)
for(int i = 0; i < n; i ++)
out[i] = a[i] + b[i];
int main()
float *a, *b, *out;
float *d_a, *d_b, *d_out;
// Allocate host memory
a = (float*)malloc(sizeof(float) * N);
b = (float*)malloc(sizeof(float) * N);
out = (float*)malloc(sizeof(float) * N);
// Initialize host arrays
for(int i = 0; i < N; i++)
a[i] = 1.0f;
b[i] = 2.0f;
// Allocate device memory
cudaMalloc((void**)&d_a, sizeof(float) * N);
cudaMalloc((void**)&d_b, sizeof(float) * N);
cudaMalloc((void**)&d_out, sizeof(float) * N);
// Transfer data from host to device memory
cudaMemcpy(d_a, a, sizeof(float) * N, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, b, sizeof(float) * N, cudaMemcpyHostToDevice);
// Executing kernel
vector_add<<<1,1>>>(d_out, d_a, d_b, N);
// Transfer data back to host memory
cudaMemcpy(out, d_out, sizeof(float) * N, cudaMemcpyDeviceToHost);
// Verification
for(int i = 0; i < N; i++)
assert(fabs(out[i] - a[i] - b[i]) < MAX_ERR);
printf("PASSED\\n");
// Deallocate device memory
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_out);
// Deallocate host memory
free(a);
free(b);
free(out);
编译并可使用time来验证程序性能:
$> nvcc vector_add.cu -o vector_add
$> time ./vector_add
NVIDIA也提供了名为nvprof的命令行profiler工具,可提供更多程序性能信息:
$> nvprof ./vector_add
以Tesla M2050为例,相应profiling为:
==6326== Profiling application: ./vector_add
==6326== Profiling result:
Time(%) Time Calls Avg Min Max Name
97.55% 1.42529s 1 1.42529s 1.42529s 1.42529s vector_add(float*, float*, float*, int)
1.39% 20.318ms 2 10.159ms 10.126ms 10.192ms [CUDA memcpy HtoD]
1.06% 15.549ms 1 15.549ms 15.549ms 15.549ms [CUDA memcpy DtoH]
3. CUDA并行化
CUDA使用kernel execution configuration <<<...>>> 来告诉CUDA runtime该在GPU中启动多少个线程。
CUDA organizes threads into a group called “thread block”。
Kernel可启动多个thread blocks,organized into a “grid” structure。
kernel execution configuration的语法为:
<<<M, T>>>
表示kernel launches with a gird of M thread blocks。每个thread block具有T parallel threads。
接下来,将使用multithread来parallelize上例中的vector addition,如使用a thread block with 256 threads,相应的kernel execution configuration为:
vector_add <<< 1 , 256 >>> (d_out, d_a, d_b, N);
CUDA提供了内置变量来访问thread information,此例中包含了一下2个内置变量:
threadIdx.x:包含了the index of the thread within the block。此例中,index范围为0~255。blockDim.x:包含了the size of thread block(number of threads in the thread block)。此例中,该值为256。

完整的vector_add_thread.cu源代码为:
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <assert.h>
#include <cuda.h>
#include <cuda_runtime.h>
#define N 10000000
#define MAX_ERR 1e-6
__global__ void vector_add(float *out, float *a, float *b, int n)
int index = threadIdx.x;
int stride = blockDim.x;
for(int i = index; i < n; i += stride)
out[i] = a[i] + b[i];
int main()
float *a, *b, *out;
float *d_a, *d_b, *d_out;
// Allocate host memory
a = (float*)malloc(sizeof(float) * N);
b = (float*)malloc(sizeof(float) * N);
out = (float*)malloc(sizeof(float) * N);
// Initialize host arrays
for(int i = 0; i < N; i++)
a[i] = 1.0f;
b[i] = 2.0f;
// Allocate device memory
cudaMalloc((void**)&d_a, sizeof(float) * N);
cudaMalloc((void**)&d_b, sizeof(float) * N);
cudaMalloc((void**)&d_out, sizeof(float) * N);
// Transfer data from host to device memory
cudaMemcpy(d_a, a, sizeof(float) * N, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, b, sizeof(float) * N, cudaMemcpyHostToDevice);
// Executing kernel
vector_add<<<1,256>>>(d_out, d_a, d_b, N);
// Transfer data back to host memory
cudaMemcpy(out, d_out, sizeof(float) * N, cudaMemcpyDeviceToHost);
// Verification
for(int i = 0; i < N; i++)
assert(fabs(out[i] - a[i] - b[i]) < MAX_ERR);
printf("PASSED\\n");
// Deallocate device memory
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_out);
// Deallocate host memory
free(a);
free(b);
free(out);
$> nvcc vector_add_thread.cu -o vector_add_thread
$> nvprof ./vector_add_thread
相应的性能为:
==6430== Profiling application: ./vector_add_thread
==6430== Profiling result:
Time(%) Time Calls Avg Min Max Name
39.18% 22.780ms 1 22.780ms 22.780ms 22.780ms vector_add(float*, float*, float*, int)
34.93% 20.310ms 2 10.155ms 10.137ms 10.173ms [CUDA memcpy HtoD]
25.89% 15.055ms 1 15.055ms 15.055ms 15.055ms [CUDA memcpy DtoH]
以上为1个thread block。CUDA GPU具有多个并行处理器,名为Streaming Multiprocessors(SMs)。每个SM包含了多个并行处理器,可运行多个concurrent thread blocks。为了充分利用CUDA GPU,kernel应启动多个thread blocks。此时CUDA再额外提供2个内置变量:
blockIdx.x:包含the index of the block with in the grid。gridDim.x:包含the size of the grid。

若一共需要
N
N
N个线程,每个thread block有256个线程,则至少需要
N
/
256
N/256
N/256个thread blocks。对于每个thread需要有a unique index,该index的计算规则为:
int tid = blockIdx.x * blockDim.x + threadIdx.x;
多个thread block的vector_add_grid.cu源代码为:
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <assert.h>
#include <cuda.h>
#include <cuda_runtime.h>
#define N 10000000
#define MAX_ERR 1e-6
__global__ void vector_add(float *out, float *a, float *b, int n)
int tid = blockIdx.x * blockDim.x + threadIdx.x;
// Handling arbitrary vector size
if (tid < n)
out[tid] = a[tid] + b[tid];
int main()
float *a, *b, *out;
float *d_a, *d_b, *d_out;
// Allocate host memory
a = (float*)malloc(sizeof(float) * N);
b = (float*)malloc(sizeof(float) * N);
out = (float*)malloc(sizeof(float) * N);
// Initialize host arrays
for(int i = 0; i < N; i++)
a[i] = 1.0f;
b[i] = 2.0f;
// Allocate device memory
cudaMalloc((void**)&d_a, sizeof(float) * N);
cudaMalloc((void**)&d_b, sizeof(float) * N);
cudaMalloc((void**)&d_out, sizeof(float) * N);
// Transfer data from host to device memory
cudaMemcpy(d_a, a, sizeof(float) * N, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, b, sizeof(float) * N, cudaMemcpyHostToDevice);
// Executing kernel
int block_size = 256;
int grid_size = ((N + block_size) / block_size);
vector_add<<<grid_size,block_size>>>(d_out, d_a, d_b, N);
// Transfer data back to host memory
cudaMemcpy(out, d_out, sizeof(float) * N, cudaMemcpyDeviceToHost);
// Verification
for(int i = 0; i < N; i++)
assert(fabs(out[i] - a[i] - b[i]) < MAX_ERR);
printf("PASSED\\n");
// Deallocate device memory
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_out);
// Deallocate host memory
free(a);
free(b);
free(out);
编译并profile性能:
$> nvcc vector_add_grid.cu -o vector_add_grid
$> nvprof ./vector_add_grid
在Tesla M2050上的性能表现为:
==6564== Profiling application: ./vector_add_grid
==6564== Profiling result:
Time(%) Time Calls Avg Min Max Name
55.65% 20.312ms 2 10.156ms 10.150ms 10.162ms [CUDA memcpy HtoD]
41.24% 15.050ms 1 15.050ms 15.050ms 15.050ms [CUDA memcpy DtoH]
3.11% 1.1347ms 1 1.1347ms 1.1347ms 1.1347ms vector_add(float*, float*, float*, int)
4. 性能对比
| Version | Execution Time (ms) | Speedup |
|---|---|---|
| 1 thread | 1425.29 | 1.00x |
| 1 block | 22.78 | 62.56x |
| Multiple blocks | 1.13 | 1261.32x |
5. OpenCL
OpenCL全称为:Open Computing Language。
OpenCL为:
- Open, royalty-free standard C-language extension
- For parallel programming of heterogeneous system using GPUs, CPUS, CBE, DSP’s and other processors including embedded mobile devices。
- 初始由苹果公司发起。苹果公司put OpenCL in OSX Snow Leopard and is active in the working group。Wroking group内包含NVIDIA, Intel,AMD,IBM等等。
- 由Khronos Group管理。该Group同时管理了OpenGL std。

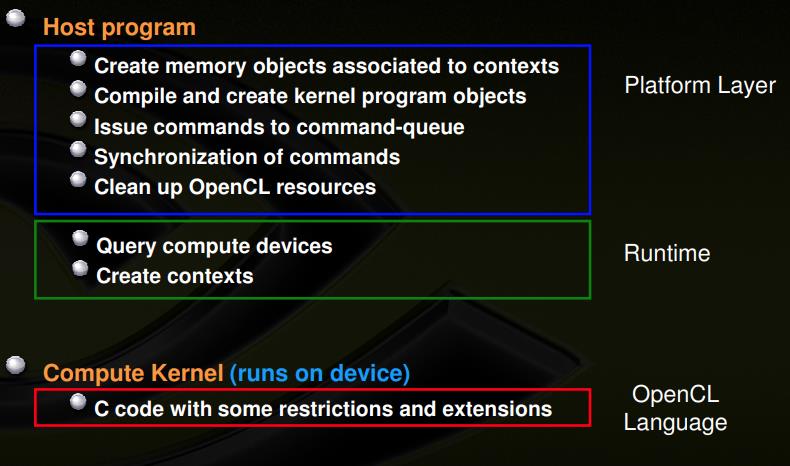
基本的程序结构为:
参考资料
[1] Getting started with OpenCL and GPU Computing
[2] Introduction to GPU Computing with OpenCL
[3] OpenCL™ Programming Guide for the CUDA™ Architecture
[4] CUDA Tutorial
以上是关于CUDA入门的主要内容,如果未能解决你的问题,请参考以下文章