通俗易懂谈强化学习之Q-Learning算法实战
Posted Datawhale
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了通俗易懂谈强化学习之Q-Learning算法实战相关的知识,希望对你有一定的参考价值。
Datawhale干货
作者:知乎King James,伦敦国王大学
知乎 | https://www.zhihu.com/people/xu-xiu-jian-33
前言:上篇介绍了什么是强化学习,应大家需求,本篇实战讲解强化学习,所有的实战代码可以自行下载运行。
本篇使用强化学习领域经典的Project-Pacman项目进行实操,Python2.7环境,使用Q-Learning算法进行训练学习,将讲解强化学习实操过程中的各处细节。如何设置Reward函数,如何更新各(State,Action)下的Q-Value值等。有基础的读者可以直接看Part4实战部分。文章略长,细节讲解很多,适合新手入门强化学习。
01 强化学习
关于强化学习的基础介绍,可以阅读我上一篇帖子,本篇不再介绍。如果完全是零基础的读者,建议先阅读上一篇文章。里面介绍了强化学习的五大基本组成部分、训练过程、各大常见算法以及实际工业界应用等。
02 Pacman Project讲解
Pacman-吃豆人游戏,本身是上世纪80年代日本南梦宫游戏公司推出的一款街机游戏,在当时风靡大街小巷。后来加州大学伯克利分校,这所只有诺贝尔奖获得者才配在学校里面拥有固定车位的顶级公立大学,将Pacman游戏引进到强化学习的课程中,作为实操项目。慢慢地成为该领域的经典Project。
项目链接:http://ai.berkeley.edu/project_overview.html,这个项目因为时间比较久,所以整体是Python2.7的源码,没有最新的Python3源码。
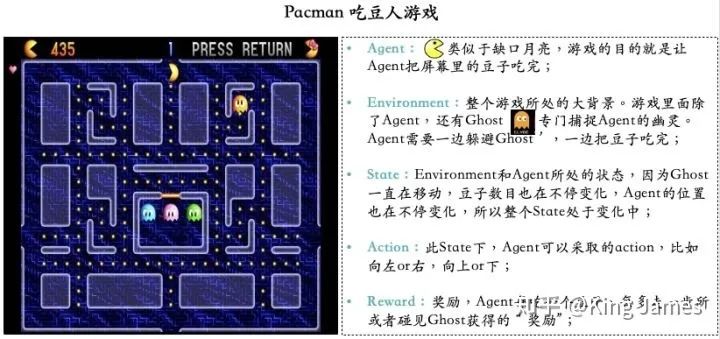
Pacman游戏目标很简单,就是Agent要把屏幕里面所有的豆子全部吃完,同时又不能被幽灵碰到,被幽灵碰到则游戏结束,幽灵也是在不停移动的。Agent每走一步、每吃一个豆子或者被幽灵碰到,屏幕左上方这分数都会发生变化,图例中当前分数是435分。
本次项目,我们基于Q-Learning算法,让Pacman先自行探索训练2000次。探索训练结束后,重新让Pacman运行10次,测试这10次中Pacman成功吃完所有屏幕中所有豆子的次数,10次中至少成功8次才算有效。
03 Q-Learning介绍
Q-Learning是Value-Based的强化学习算法,所以算法里面有一个非常重要的Value就是Q-Value,也是Q-Learning叫法的由来。这里重新把强化学习的五个基本部分介绍一下。
Agent(智能体): 强化学习训练的主体就是Agent:智能体。Pacman中就是这个张开大嘴的黄色扇形移动体。
Environment(环境): 整个游戏的大背景就是环境;Pacman中Agent、Ghost、豆子以及里面各个隔离板块组成了整个环境。
State(状态): 当前 Environment和Agent所处的状态,因为Ghost一直在移动,豆子数目也在不停变化,Agent的位置也在不停变化,所以整个State处于变化中;State包含了Agent和Environment的状态。
Action(行动): 基于当前的State,Agent可以采取哪些action,比如向左or右,向上or下;Action是和State强挂钩的,比如上图中很多位置都是有隔板的,很明显Agent在此State下是不能往左或者往右的,只能上下;
Reward(奖励): Agent在当前State下,采取了某个特定的action后,会获得环境的一定反馈就是Reward。这里面用Reward进行统称,虽然Reward翻译成中文是“奖励”的意思,但其实强化学习中Reward只是代表环境给予的“反馈”,可能是奖励也可能是惩罚。比如Pacman游戏中,Agent碰见了Ghost那环境给予的就是惩罚。
本次项目我们使用Q-Learning,所以在五个基本部分之外多了一个Q-Value。
Q-Value(State, Action): Q-value是由State和Action组合在一起决定的,这里的Value不是Reward,Reward是Value组成的一部分,具体如何生成Q-value下面会单独介绍。实际的项目中我们会存储一张表,我们叫它Q表。key是(state, action), value就是对应的Q-value。每当agent进入到某个state下时,我们就会来这张表进行查询,选择当前State下对应Value最大的Action,执行这个action进入到下一个state,然后继续查表选择action,这样循环。Q-Value的价值就在于指导Agent在不同state下选择哪个action。
重点来了!!!如何知道整个训练过程中,Agent会遇到哪些State,每个State下面可以采取哪些Action。最最重要的是,如何将每个(State, Action)对应的Q-value从训练中学习出来?
3.1 Bellman 方程
首先我们介绍一下贝尔曼方程,它是我们接下来介绍如何更新学习出Q-Value值的前提。贝尔曼方程是由美国一位叫做理查德-贝尔曼科学家发现并提出的。它的核心思想是:当我们在特定时间点和状态下去考虑下一步的决策,我们不仅仅要关注当前决策立即产生的Reward,同时也要考虑当前的决策衍生产生未来持续性的Reward。简单地说就是既要考虑当前收益最大化,还需要去关注未来持续的收益。
3.2 贝尔曼方程的Q-Value版
介绍完贝尔曼方程的思想后,在Q-learning算法中如何去更新Q-Value?

如上图的表达式,我们更新Q(s,a)时不仅关注当前收益也关注未来收益,当前收益就是状态变更环境立即反馈的reward,未来收益就是状态变更后新状态对应可以采取的action中最大的Value,同时乘以折扣率γ。对机器学习不够了解的,可能比较难以理解为什么要加一个学习率和折扣率,意义是什么?简单来说学习率和折扣率的设置是希望学习更新过程缓慢一些,不希望某一步的学习跨度过大,从而对整个的学习结果造成比较大的偏差。因为Q(s,a)会更新迭代很多次,不能因为某一次的学习对最终的Q-value产生非常大的影响。
下图是简版的Q-Learning算法阐述:

04 Q-Learning实战
介绍完Q-Learning算法正式进入Python实战,下面是实战用的代码压缩包。(有需要的伙伴可公众号后台回复日期「20211212」下载)
4.1 预热
首先我们先感受一下Pacman这个游戏,通过人工指挥和随机运动,观察一下整个实验的效果。
手动指挥: 首先进入该文件的工作路径,cd /Users/账户名/Desktop/pacman,执行命令:python pacman.py ;就会看到下图,通过电脑键盘的上下左右键,就可以指挥Pacman行动了。
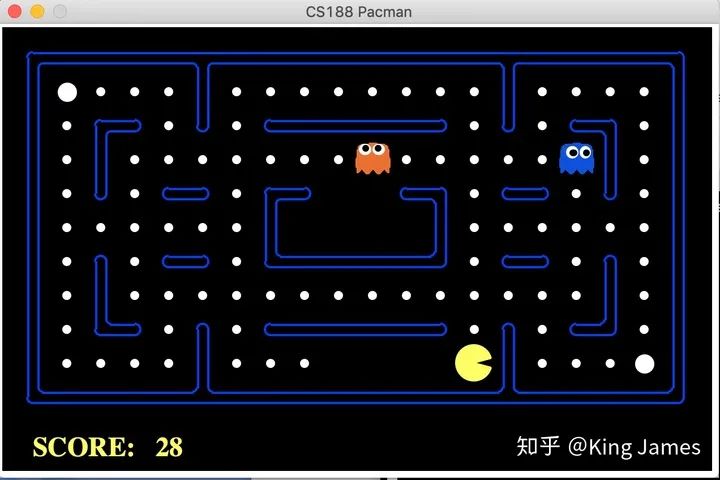
随机行动: 在刚刚的工作路径下执行该命令:python pacman.py -p RandomAgent -n 1
我们让 Pacman采取随机策略玩一遍游戏。
4.2 Q-Learning算法训练
现在我们使用Q-Learning算法来训练Pacman,本次Project编写的代码都在mlLearningAgents.py文件中,我们在该文件里面编写代码。
(1)整体思路
因为本次Pacman Project项目中我们重点在于应用Q-learning算法去进行训练,指导Agent行动。所以项目中有很多其他现成的接口我们都是直接用的。比如
State:game.py文件已经将如何获取Agent当前的State定义成了Class,直接引用即可;
Action:game.py文件已经将Agent在当前State可以采取的Action定义成了Class,直接引用即可;(感兴趣的同学可以自己打开文件查看代码,核心就是建立一个坐标系,然后确定挡板、Ghost、豆子、Agent的位置,然后进行判断和数学表达。)
参数设置:学习率alpha我们设置为0.2,折扣率gamma设置为0.8,最终训练完我们让Pacman运行numTraining=10次查看效果,同时这里面有一个探索率epsilon = 0.05。这就是上一篇介绍的EE问题,我们不能光让Agent去执行Q-value最大的action,同时我们也需要让Pacman有一定的探索。

(2) Q-value表
因为最开始我们无从得知Pacman会经历哪些状态State,以及采取哪些Action,所以我们最开始设置一个Q-value的空表,将训练中Pacman经历过的状态State,以及执行的Action,及最终学习产出的Q-value都保存在此张表里。

(3) 选择Best Move
定义一个Class,在State确认的情况下,首先找到最大的Q-value是多少。
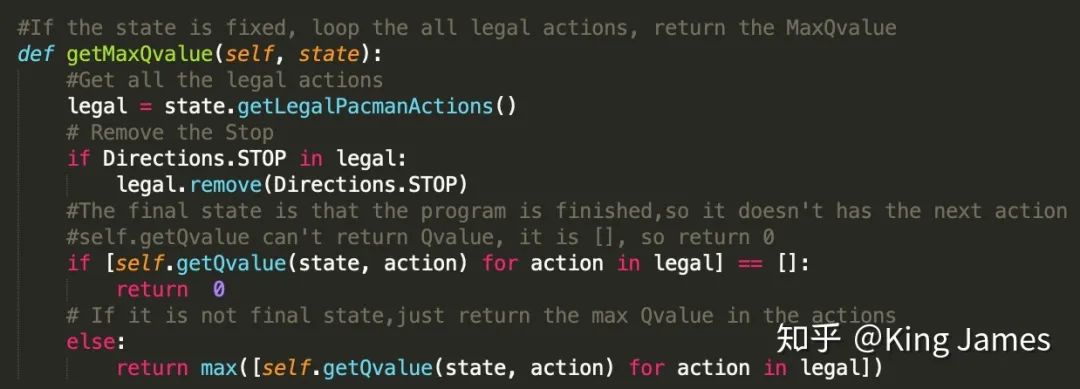
然后找到该Q-value对应的Action:
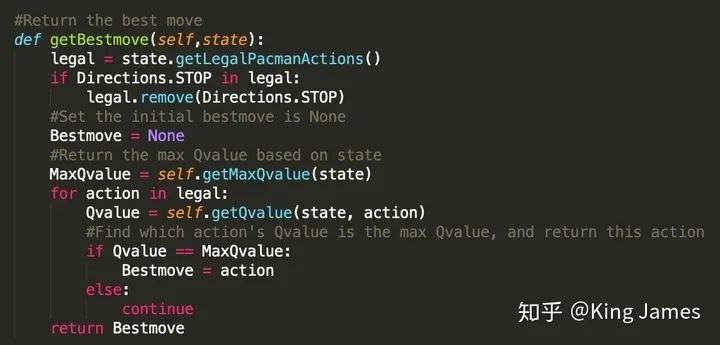
(GetLegalPAcmanActions即为获取当前state下,Agent可以执行的所有合理的action的类,文件里现成的类)
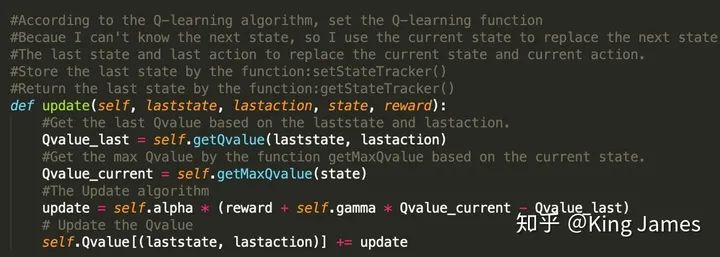
(4) Update Q-value
以下为更新Q-value的表达式,这里面有一个非常细节的地方。Pacman最开始运动的第一步的时候,我们是无法知晓下一步的State是什么的,源文件提供的类只能获取当前的State。但当Pacman从当前State倒推,我们是知道上一个State是什么的,因为Pacman刚刚经历过,只要我们将上一个State记录下来即可。所以整个的更新表达式逻辑变为了用当前的State去更新上一步的(State,Action)对应的Q-value。该思路是解决本问题的关键。
(5) 让Agent运动起来
最后就是指导Pacman行动了,这里面存在大量的状态和动作的记录,我们需要将每一步经历的State和采取的Action都保存进对应的Table中。同时这里面还有一个细节,就是Reward的设置,一直没有提到从一个State变为另一个State如何设置Reward。Pacman项目中,我们可以取巧的使用项目中现有的Pacman每行动一步Score发生的变化作为Reward,两个状态变化时Score的差值我们认为就是Reward,这一步为我们节省了大量设置Reward的功夫。如果想自己设置Reward逻辑就是Pacman采取的行动离豆子越近Reward越多,离Ghost越近Reward越少的
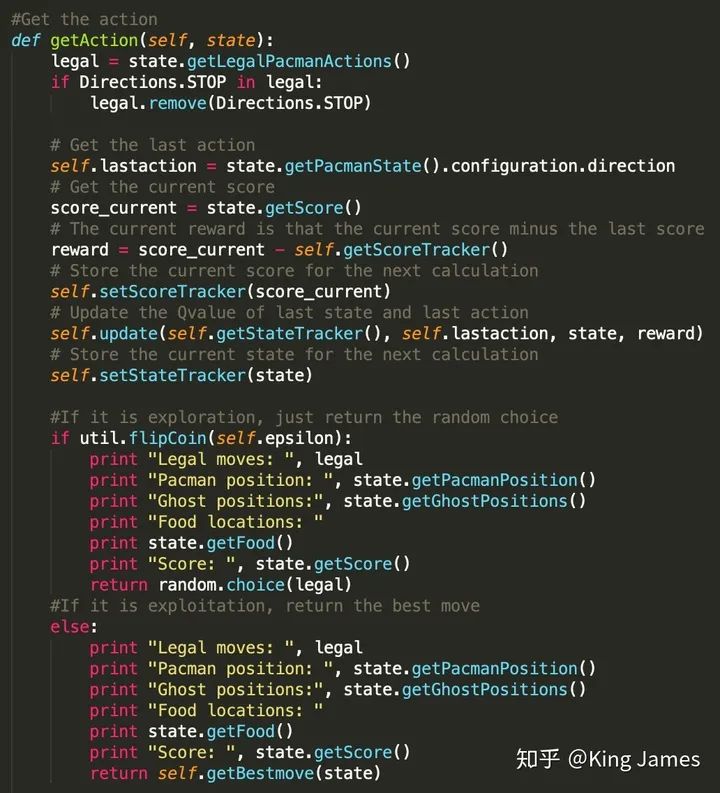
训练时Pacman行动的策略一部分是探索时的Random choice,一部分是利用时的Best Move。探索比例前面参数设置已经提到0.05。以上Print的部分,是训练时我们打印每一步的训练结果。
最后训练完以后,我们打印一条message,进行一下标记
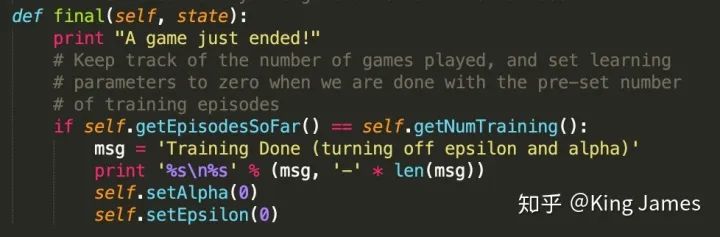
正式训练我们还是在之前的工作路径下执行如下命令:
python pacman.py -p QLearnAgent -x 2000 -n 2010 -l smallGrid
这里面QLearnAgent就是调用我们此次算法的类,2000次是训练次数,2010-2000=10,10即为我们测试的次数。smallGrid是我们此次测试和训练仅使用Pacman的小界面,不使用大的界面进行训练,因为大界面State太多,训练时间过长,为了更快完成实验看到效果我们在小的游戏界面上进行实验。
下图是训练时打印的message;
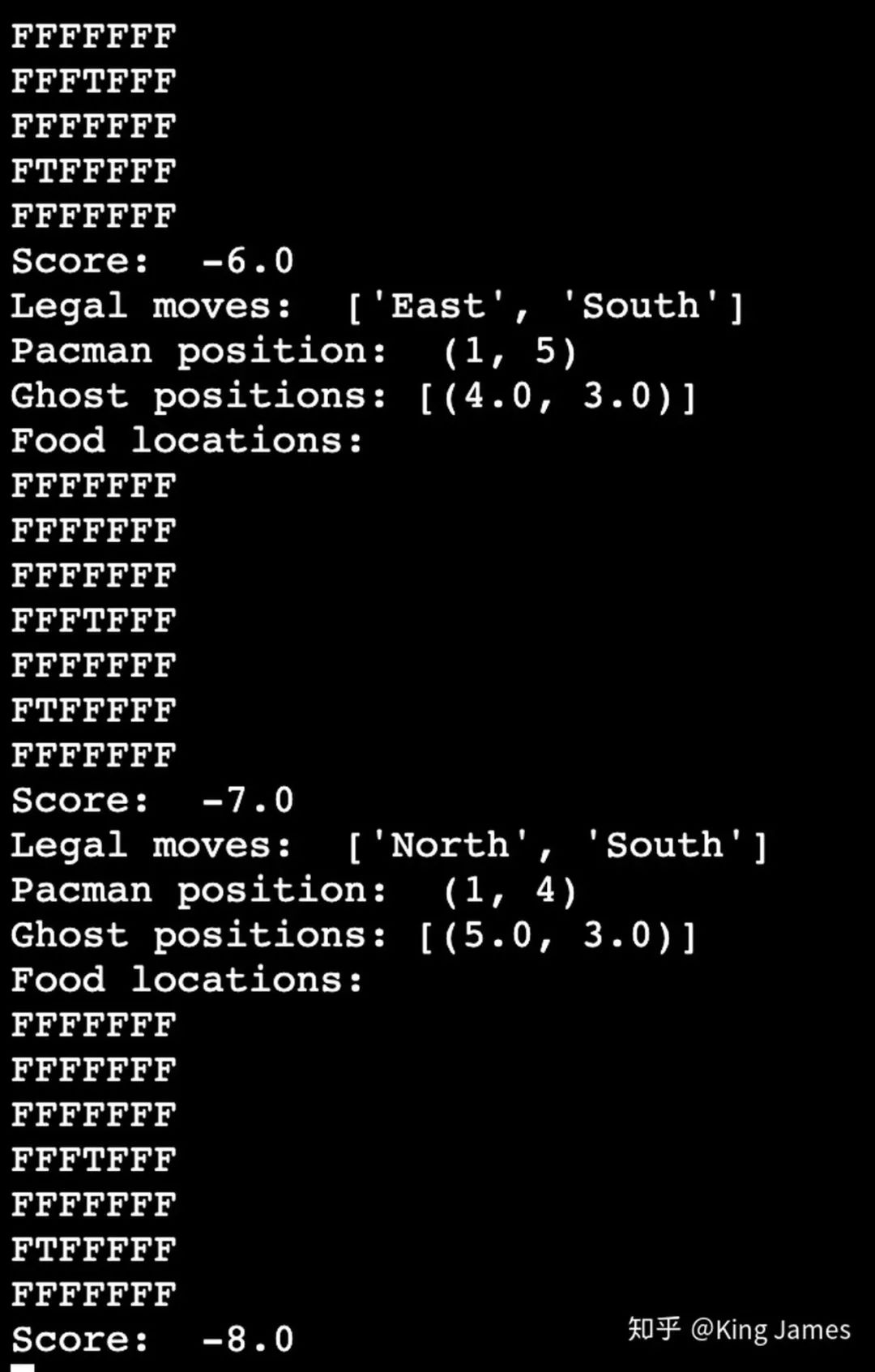
下图就是最终测试时Pacman的运行小界面smallgrid

最后这条就是统计的10次中,Pacman赢的次数,我们可以看到有8次win,所以圆满地完成了我们的实验。

2000次训练对于SmallGrid界面是差不多的,大家也可以将SmallGrid改为MediumGrid,但是要大幅提升训练次数,不然学习效果不明显。大家自己跑起来吧~

King James
伦敦国王学院 数据科学硕士
知乎同名

整理不易,点赞三连↓
以上是关于通俗易懂谈强化学习之Q-Learning算法实战的主要内容,如果未能解决你的问题,请参考以下文章