Uber实战案例:基于Alluxio实现Presto缓存
Posted Alluxio
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Uber实战案例:基于Alluxio实现Presto缓存相关的知识,希望对你有一定的参考价值。

01 Uber的业务场景

如上图所示,在Uber,所有的决策都与数据有关。Presto以及其他各种查询引擎在Uber是被广泛使用的。例如,运营团队在Dashboard等服务中大量使用了Presto,而UberEats和市场团队也依赖于这些查询结果来确定价格。此外,Presto也在Uber的合规部、增长营销部门、ad-hoc数据分析等场景下使用。
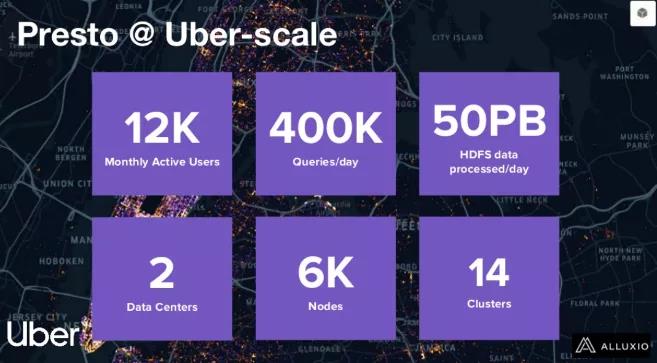
上图展示了Uber内部的一些重要数据。总的来说,目前Presto在Uber内部有12K的月活跃用户,每天要处理400K的查询并且要处理超过50PB的数据。在基础设施方面,Uber有2个数据中心,部署Presto在大约6千个节点和14个集群。
02 Uber的Presto部署
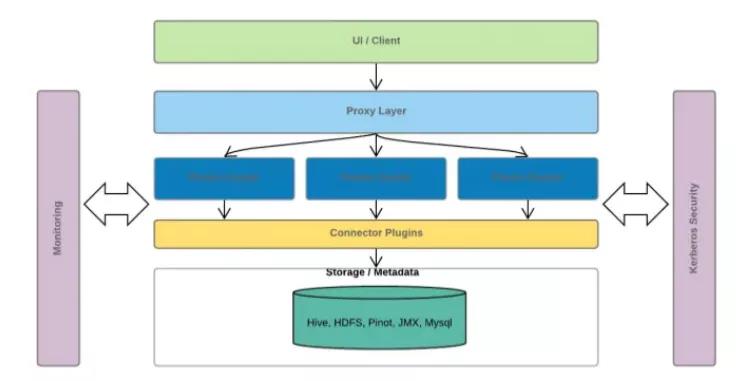
Uber的Presto架构如上图所示。
最上层是UI/Client层,这其中包括了一些内部的Dashboard、Google Data Studio、Tableau等工具。此外,我们还有一些后台服务,使用了JDBC或其他的内部查询引擎来与Presto进行通信。
Proxy层,这一层负责从每一个Presto集群的coordinator拉取数据,以获取query数量、task数量、CPU和Memory使用率等信息,我们也基于此判断应该将每个query调度到哪一个集群,来提供load-balancing和query-gating服务。
在底层,就是多个Presto集群,它们与底层Hive、HDFS、Pinot等进行通信。不同plugin或不同的数据集之间可以进行join操作。
此外,如图中的左右两侧所示,对上述架构中的每一层,我们还有:
内部的监控服务
基于Kerberos Security提供的Security broker
03 Workloads
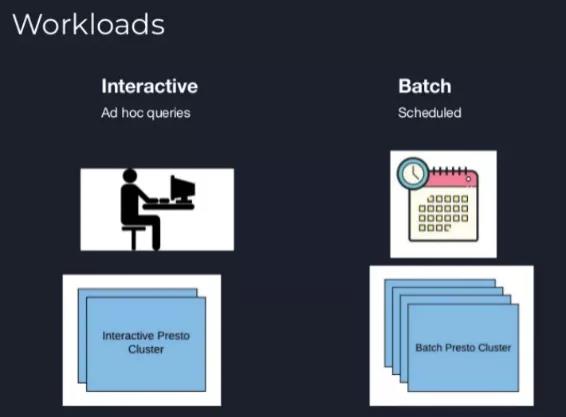
我们的workloads可以大致分为两类:
Interactive:由数据科学家和工程师发送的query
Scheduled:主要是Batch query,包括Dashboard查询、ETL查询等*
04 上云

接下来,我们简单介绍一下我们关于业务上云的思考。
在过去的几年中,Uber的团队一直在思考如何上云和何时上云的问题,以及应该以怎样的布局(layout)来与云进行交互。这里以“what-how-why”模型列出了一些我们认为值得讨论的点。
● What:我们有多种多样的应用布局,比如,应用方面,我们有BI等应用;计算引擎方面,我们不仅有Spark、Presto等。在云这个场景下,我们还有许多云原生的选择;存储方面,有gcs、S3、甚至是HDFS等多种选择。
● Why:对我们来说,上云最重要的一个动机是,我们希望提高cost efficiency,更好地帮助硬件设施来实现资源弹性扩展。同时,我们也希望能提供高可用、可扩展性、可靠性。
● How:如何上云,这其中也有很多要点值得讨论。1.云能提供很多原生的特性,那么我们就需要考虑,这些特性如何才能与开源组件保持相互一致;2.不同规模下的性能如何,Uber维护了一个非常大型的数据湖,因此性能数据对我们和客户来说都是非常重要的;3.我们也很重视云上的Security和Compliance问题;4.我们也可以使用云提供的一些原生的特性,来弥补我们自己的“技术债”(Tech Debt)。
05 Presto on GCP
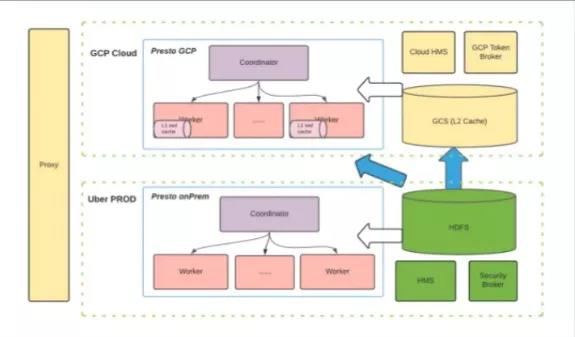
上图展示了我们对于Presto上云的规划。
基于这样的架构,我们的解决方案可以扩展到不同云服务厂商中。这个目前只是作为我们的长期规划和愿景,还处在非常初期的实现阶段。
总体上,我们有Cloud集群和PROD集群。如图中右下角所示,我们希望大部分的数据还是在onPrem HDFS上。图中偏左的蓝色箭头代表了我们做的一些预先测试,我们在HDFS之上不加任何的缓存进行了一些实验,结果表明,网络流量非常高,从而带来了巨大的开销。因此,我们设想能使用云提供的服务,比如GCS或S3,来提供类似于L2 Cache的功能。我们希望能将数据集中的一些高访问频率的重要数据放在这些“云上的L2 Cache”中,而对于云上的每个Presto集群,我们计划利用本地的SSD来缓存一些数据,以提升性能。
06 基于Alluxio提供本地缓存
接下来,我将更深入地分享我们团队如何使用Alluxio的本地缓存,包括我们遇到的问题以及我们如何解决这些问题。
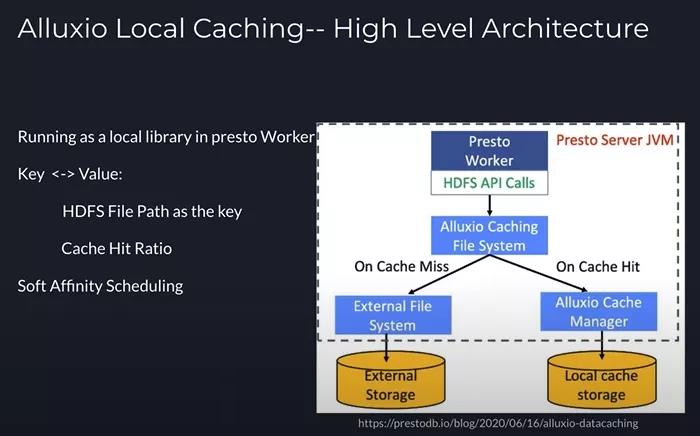
总体来说,Alluxio的Cache Library与Alluxio Service的运行方式很不同。Alluxio Cache Library是在Presto worker内部的运行的本地缓存。我们在默认的HDFS client的实现之上封装了一层,当读取HDFS的API被调用时,系统首先会查看缓存空间,以知晓这是否为一次缓存命中(cache hit or miss)。如果缓存命中,则从本地的SSD中读取数据;否则,将从远端的HDFS中读取并将数据缓存在本地,这样在下一次读取时,我们就能从本地读取。具体实现时,我们将文件在HDFS中的路径作为key。这一过程中,缓存命中率对于整体的性能也有着非常重要的影响。
此外,为了判断缓存是否在Presto worker中,我们还利用了Soft Affinity Scheduling。简而言之,这一功能可以确保将同样的key分发到同一个worker上,这样我们就可以利用本地的library来确认每一次的数据读取是否命中了缓存。我将在下文对此进行详细介绍。
大数据量所带来的问题
下面分享我们所遇到的几个关键问题和解决方案。

-
Uber的数据湖是非常大的,我们每天处理50PB的数据,而Uber的数据湖绝对超过了EB级别。同时,我们有各种各样的表,比如Hudi表、Hive ETL等。我们的数据大部分是按照日期的进行分区的。在Hudi中,由于Hudi会对文件的每个分区进行增量更新,因此同一个文件可以有不同的版本;Hive ETL会生成大量的Staging目录,在新的文件分区产生之后,这些staging目录就失效了。因此,随着时间推移,会有大量的冗余文件和文件更新,我们需要对这一情况进行处理。
-
关于缓存命中率。我们每天都有大于3PB的非重复数据(distinct data)访问,并且有约10%的频繁访问数据(frequently accessed data)和约3%的热访问数据(hot accessed data)。针对频繁访问数据和热访问数据,我们希望能构建一个图,来反映有多少不重复的表访问(distinct table access)和联合表访问(joint table access)。
针对超大数据量所带来的挑战,我们尝试构建一个过滤器布局(filter layout)——只缓存我们需要的数据。一开始,我们只会将热访问数据放入缓存,在此之后,我们逐步扩大缓存空间。
HDFS延迟

上面的图表展示了,在Presto的一次扫描或投影的查询中,由于有些partition/split/task可能非常大,因此有些HDFS节点的延迟甚至达到了4至5秒。在生产环境中这一延迟数据还会更大。这就使得数据节点延迟产生了随机性(random latency)。这会给我们生产环境中的查询带来严重的影响。
如果我们使用了缓存,HDFS缓存的数据就如上图所示。如果缓存能够命中,我们就能取得更低的、更稳定的延迟数据。实验中,我们尝试使用本地缓存来取得百分百的缓存命中,来取得一个非常稳定的延迟性能。另外,在上述的实验过程中,我们也修复了一个Namenode listing相关的bug。
Soft Affinity Scheduling

目前在Presto中,Soft Affinity Scheduling是基于一个简单的“取模”算法来实现的,这一做法的坏处是,如果出现了节点的增删,那么整个缓存的键空间都需要进行更新。针对这一问题,现在已经有了一种开源的解决方案,如果预定义的节点很多而出问题的节点很少的话,这一方案可以很好地解决该问题。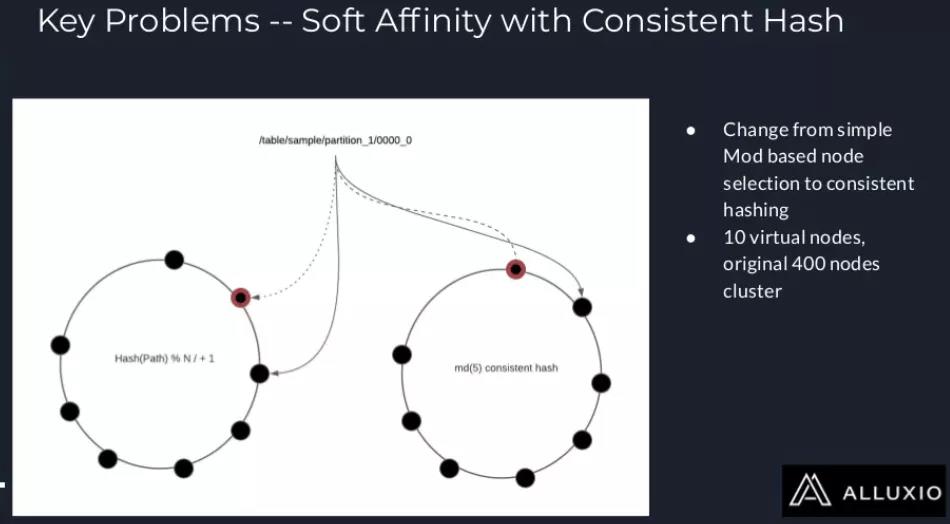
但是在Uber,我们遇到了新的问题:在我们集群中,节点的数量不是固定的。所以我们引入了基于一致性哈希的调度策略。我们一共有400个节点,并为每个节点分配10个虚拟节点。因此所有缓存的键就分布在一个有4000个节点的一致性哈希环上。关于这一改进机制,我们已经向开源社区提交了一个pull request,感兴趣的朋友可以试用此功能。

初期的测试已经完成,而且数据很不错。结果表明,如果数据在缓存中,对于那些依赖于SFP性能的查询而言,它们的性能可以得到大幅度提升。我们目前正在进行的工作包括:
工作一:在TPCDS benchmark上进行sf10k测试;
工作二:尝试从历史数据中分析表或分区的访问模式,找出最热的数据,从而能更好地设置缓存过滤器;
工作三:集成一些Dashboard和监控功能。
07 关于Alluxio的思考与总结
在将Alluxio的本地缓存与Uber的Presto服务相结合的过程中,在Presto这一侧,我们取得了更好、更稳定的性能,同时,在Alluxio侧,我们也做出了一些设计上的改进。
思考总结

其一,是关于所谓的“stale cache”的问题,即缓存空间中可能存储了旧的数据。尽管我们将缓存数据放在了Presto的本地SSD中,但真正的数据实际上存放在GCS或者HDFS等,这些数据可能被其他人修改。比如,在使用Hudi table情况下,我们经常可以看到,数据文件的“最后修改时间戳”一直在变化。因此,如果我们缓存了旧的数据,这就会导致查询的结果不准确。更坏情况下,因为新旧的page被混合在一起,当Presto传送Parquet或者ORC文件时,Presto中可能出现异常(Exception)。
其二,每天从HDFS中读取的不重复数据可能很大,但我们没有足够的缓存空间来缓存所有数据。这就意味着在Uber的缓存过滤器之外,Alluxio需要eviction或allevation策略。此外,我们还可以引入quota管理。我们为每个table设置一个quota,对于那些热访问的表,我们设置一个更大的quota,而对于冷访问的、不需要缓存的表,我们可以设置一个非常小的甚至是0的quota。
其三,尽管我们已经在本地缓存中存放了元数据,但它仅仅在内存中而不在磁盘中。这就导致,当服务器启动时,无法恢复元数据。比如,Presto的服务器宕机重启后,服务器可以重新获取到数据,但是其中没有元数据,这可能导致quota管理被破坏。
文件级元数据

因此,我们提出了文件级元数据(File Level Metadata),其中保存了最后修改时间和每个数据文件的scope。我们需要将这些数据保存在磁盘中,使得Presto worker能在启动时获取这些数据。
引入这种元数据后,数据就会有多个版本(multiple versions of the data)。也就是说,数据被更新后,就会生成一个新的时间戳,对应于一个新的版本。因此我们将创建一个新的文件夹来与这个新的时间戳相对应,这个文件夹中保存了新的page,与此同时,我们会尝试将旧的时间戳删除。
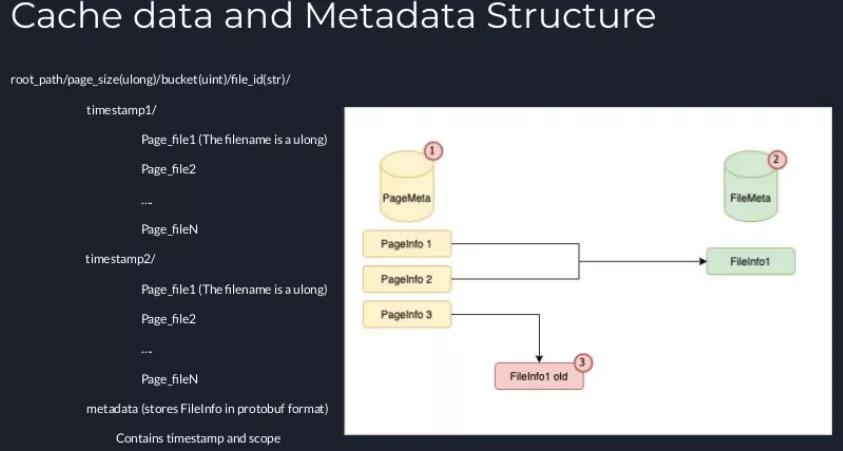
如上图左侧所示,我们有两个文件夹,对应于两个时间戳:timestamp1和timestamp2。通常来说,在系统运行时,不会同时有两个时间戳,因为我们会直接将旧的timestamp1删除而只保留timestamp2。但是,在服务器繁忙或高并发的情况下,我们可能无法准时将时间戳删除,这种情况下,我们就可能会同时有两个时间戳。除此之外,我们还维护一个元数据文件,其中以protobuf格式的保存了文件信息,而且保存了最新的时间戳。这样就能保证,Alluxio的本地缓存只会从最新的时间戳中读取数据,服务器重启时,也从元数据文件中读取到时间戳信息,从而能正确地管理quota和最后修改时间等信息。
元数据感知
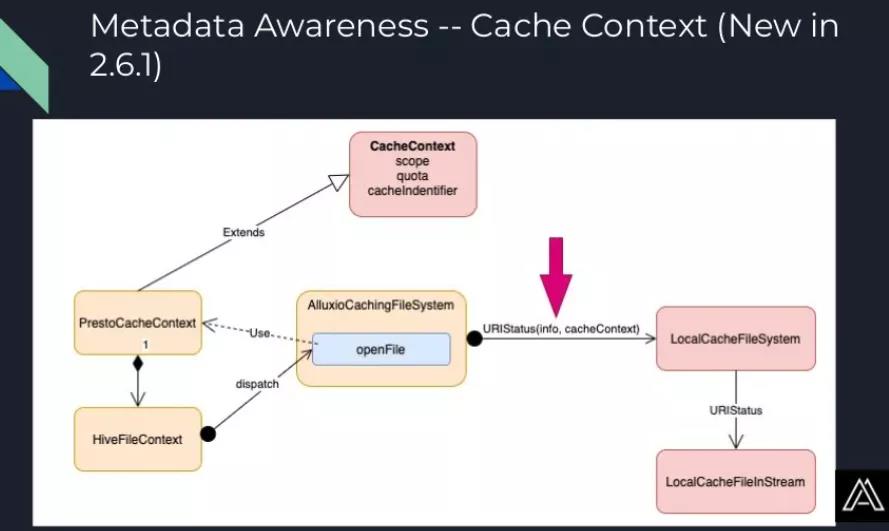
由于Alluxio是一个通用的缓存解决方案,所以它依然需要计算引擎(即Presto)来将元数据传递给它。因此,在Presto一侧,我们利用了HiveFileContext。每一个Hive表或Hudi表都有一个数据文件,而Presto会为每个数据文件创建一个HiveFileContext。Alluxio在打开Presto文件时,就会利用这一信息。在调用openFile时,Alluxio创建一个新的PrestoCacheContext实例,其中保存了HiveFileContext,也有scope(包含四个等级:database、schema、table、partition)、quota、cache identifier(即文件路径的md5值)等信息。我们会将这个cache context传递到我们的本地文件系统中。这样,我们就可以在Alluxio中进行元数据管理和指标收集等工作。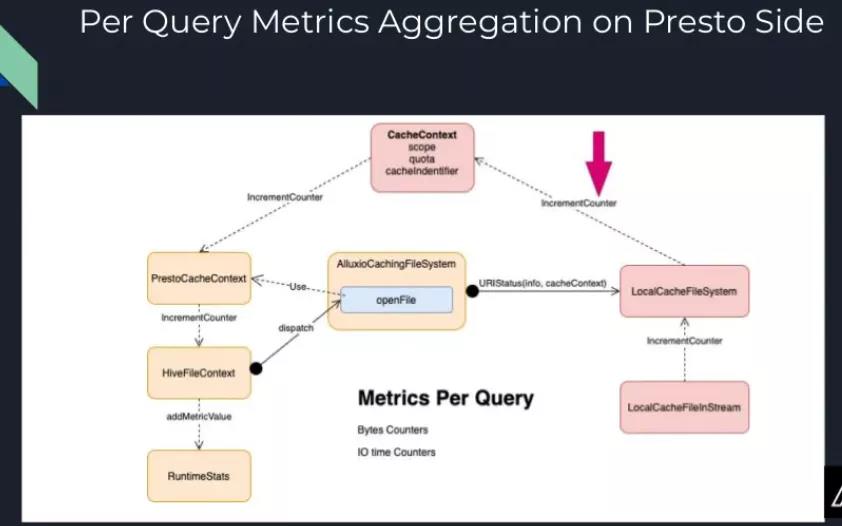
除了从Presto传递数据到Alluxio,我们也可以向Presto调用一些回调函数(callback)。这样,在执行查询操作时,我们就可以知道一些内部消息,比如多少字节数据读取命中了缓存/多少字节的数据是从外部HDFS存储中读取的。
如上图,我们将含有PrestoCacheContext的HiveFileContext传递给本地的缓存文件系统(LocalCacheFileSystem),之后本地的缓存文件系统会向CacheContext调用一些回调函数(IncremetCounter),然后这个回调的调用链会继续进行,到HiveFileContext中,再到RuntimeStats。在Presto中,执行查询时就是利用RuntimeStats来收集指标信息,因此我们就可以在这里进行一些聚合操作。
在此之后,我们就可以在Presto的UI或是JSON文件中看到这些本地缓存文件系统相关的信息。有了上述流程,我们就能让Alluxio和Presto紧密联系并工作在一起。在Presto端,我们有了更好的统计数据;在Alluxio端,我们对元数据有了更清楚的认知。
下一步工作

上文提及的一些工作实际上还在进行中。在此之后,我们还计划进行以下三方面的工作:
1.继续进行性能调优。事实上,因为上述的回调过程使得CacheContext的生命周期大大增长了,我们已经遇到了一些GC延迟上升的问题,我们正在着手解决这一问题;
-
基于上文提出的元数据,我们还可以实现语义缓存(Semantic Cache)。例如,我们可以将Parquet或者ORC文件中的数据结构保存下来,比如footer、索引等;
-
使用更高效的反序列化方法,比如用flat-buffer来代替现有的protobuf。尽管ORC factory中使用了proto buffer来存储元数据,但是在与Facebook的合作中,我们发现,Parquet footer带来的CPU使用率占了总CPU使用率的20%-30%以上。因此,我们正计划用flat buffer来代替现有的proto buffer,来存储缓存和元数据,这有望大大提高反序列化的性能。
以上是关于Uber实战案例:基于Alluxio实现Presto缓存的主要内容,如果未能解决你的问题,请参考以下文章