深度强化学习-Dueling DQN算法原理与代码
Posted indigo love
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度强化学习-Dueling DQN算法原理与代码相关的知识,希望对你有一定的参考价值。
Dueling Deep Q Network(Dueling DQN)是对DQN算法的改进,有效提升了算法的性能。如果对DQN算法还不太了解的话,可以参考我的这篇博文:深度强化学习-DQN算法原理与代码,里面详细讲述了DQN算法的原理和代码实现。本文就带领大家了解一下Dueling DQN算法,论文链接见下方。
论文:http://proceedings.mlr.press/v48/wangf16.pdf
代码:https://github.com/indigoLovee/Dueling_DQN
喜欢的话可以点个star呢。
1 Dueling DQN算法简介
Dueling DQN算法提出了一种新的神经网络结构——对偶网络(duel network)。网络的输入与DQN和DDQN算法的输入一样,均为状态信息,但是输出却有所不同。Dueling DQN算法的输出包括两个分支,分别是该状态的状态价值V(标量)和每个动作的优势值A(与动作空间同维度的向量)。DQN和DDQN算法的输出只有一个分支,为该状态下每个动作的动作价值(与动作空间同维度的向量)。具体的网络结构如下图所示:
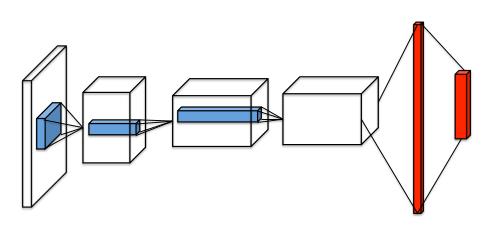
单分支网络结构(DQN和DDQN)
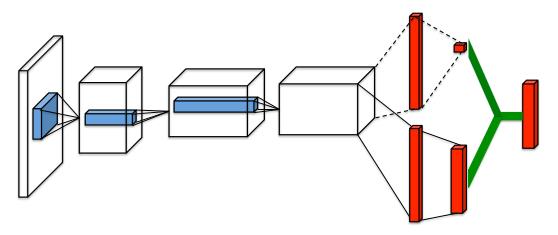
对偶网络结构(Dueling DQN)
在DQN算法的网络结构中,输入为一张或多张照片,利用卷积网络提取图像特征,之后经过全连接层输出每个动作的动作价值;在Dueling DQN算法的网络结构中,输入同样为一张或多张照片,然后利用卷积网络提取图像特征获取特征向量,输出时会经过两个全连接层分支,分别对应状态价值和优势值,最后将状态价值和优势值相加即可得到每个动作的动作价值(即绿色连线操作)。
为什么要采用对偶网络结构?
其实动机很简单:很多游戏的Q值,只受当前状态影响,无论采取什么动作区别不大。如下图所示:
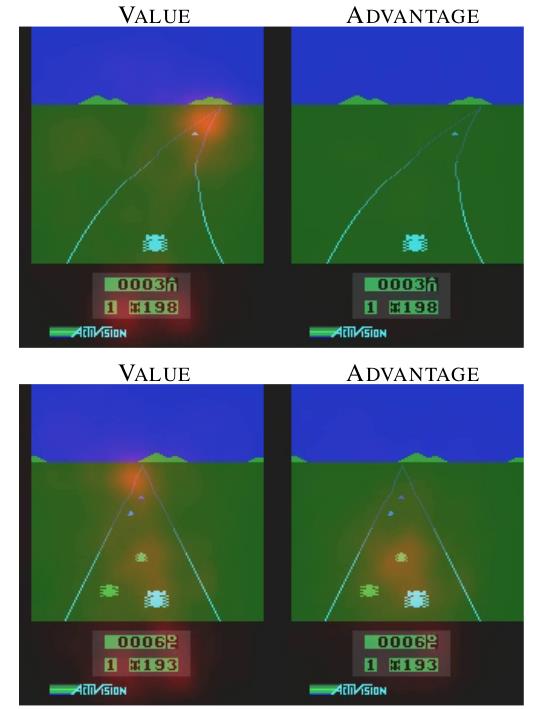
这是Atari game中的一个赛车游戏,Value表示状态价值,Advantage表示动作优势值,图中黄色部分表示注意力。当前方没有车辆时,智能体左右移动并没有影响,说明动作对Q值没有影响,但是状态对Q值很有影响。从上面两幅图可以看出,Value更加关注远方道路,因为开的越远,对应的状态值越大;Advantage没有特别注意的地方,说明动作没有影响。当前方存在车辆阻挡时,智能体的动作选择至关重要,说明动作对Q值存在影响,同样状态对Q值也会存在影响。从下面两幅图可以看出,Value同样更加关注远方道路,但是Advantge此时会关注前方车辆,因为如果不采取相应动作,智能体很有可能会发生碰撞,分数就会很低。对偶网络思想符合很多场景的设定。
2 Dueling DQN算法原理
2.1 优势函数(Advantage function)
在讲优势函数之前,我们先来回顾一些基本概念吧。
折扣回报(Discounted return):
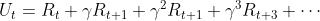
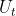 表示从t时刻开始,未来所有奖励的加权求和。在t时刻,是未知的,它依赖于未来所有状态和动作。
表示从t时刻开始,未来所有奖励的加权求和。在t时刻,是未知的,它依赖于未来所有状态和动作。
动作价值函数(Action-value function):
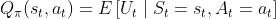
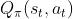 是回报的条件期望,将t+1时刻以后的状态和动作全部消掉。依赖于状态
是回报的条件期望,将t+1时刻以后的状态和动作全部消掉。依赖于状态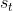 、动作
、动作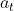 以及策略
以及策略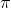 。
。
状态价值函数(State-value function):
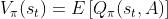
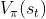 是的期望,将中的动作消掉。依赖于状态 和策略。
是的期望,将中的动作消掉。依赖于状态 和策略。
最优动作价值函数(Optimal action-value function):
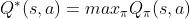
动作价值函数依赖于策略,对关于求最大值,消除掉,得到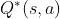 ,只依赖于状态
,只依赖于状态 和动作
和动作 ,不依赖于策略。用于评价在状态下做动作的好坏。
,不依赖于策略。用于评价在状态下做动作的好坏。
最优状态价值函数(Optimal state_value function):
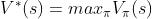
对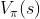 关于求 最大值,消除掉,得到
关于求 最大值,消除掉,得到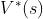 ,只依赖于状态, 不依赖于策略。用于评价状态的好坏。
,只依赖于状态, 不依赖于策略。用于评价状态的好坏。
最优优势函数(Optimal advantage function):
将作为baseline,则优势函数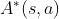 表示动作相对于baseline的优势。动作越好,其优势越大。
表示动作相对于baseline的优势。动作越好,其优势越大。
2.2 优势函数性质
为了推导优势函数的性质,这里给出定理1(大家可以从确定性策略角度来理解定理1,这里不给出该定理的证明):
定理1:

针对优势函数
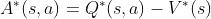
两边同时对动作取最大值,得到
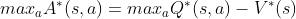
根据定理1进一步得到
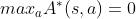
接着对优势函数做变换,得到

不妨在上式右边减去 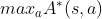 ,由于其等于0,等号不变,得到
,由于其等于0,等号不变,得到

看到这里小伙伴可能会疑惑,为什么要 减去 ,这不是多此一举吗?不急,这个后面2.4节会解释。至此,我们得到了定理2,这是一个非常重要的等式,Dueling Network就是根据定理2得到的。
定理2:
2.3 对偶网络
在DQN算法中,我们利用神经网络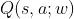 来近似最优动作值函数,从而得到最优策略,其中
来近似最优动作值函数,从而得到最优策略,其中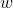 为网络参数。但是在Dueling Network中,我们利用神经网路
为网络参数。但是在Dueling Network中,我们利用神经网路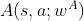 来近似最优优势函数,利用神经网络
来近似最优优势函数,利用神经网络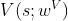 来近似最优状态值函数,其中
来近似最优状态值函数,其中 和
和 均为网络参数。
均为网络参数。
根据定理2,将其中的用神经网络来替代,用神经网络来代替,得到

其中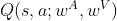 近似,它被成为Dueling Network。令
近似,它被成为Dueling Network。令 ,则
,则

现在,我们发现Dueling Network与DQN完全一致,包括输入和输出,唯一不同在于神经网络的结构。Dueling Network的网络结构更好,因此它的表现比DQN更好。另外,DQN中的一些技巧也同样可以用于Dueling Network中,例如优先经验回放、Double DQN和Multi-step TD target等。
2.4 唯一性
观察下面两个等式:
下面的式子相较于上面的式子只是减去了,前面已经讨论过 ,既然如此,这一项有必要的吗,直接用上面的式子不就行了吗?
答案是有必要的。因为上面的式子存在一个缺点:无法通过学习来唯一确定和。举个栗子:令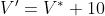 ,
,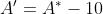 ,那么
,那么

因此结果不唯一。这种不唯一性会带来什么问题呢?
如果神经网络V和A上下波动,幅度相同,方向相反,那么网络的输出相同,但是由于两个网络都在上下波动,两个网络都不稳定,因此都训练不好。
针对上面式子的不唯一性,下面的式子可以解决。通过加入最大化强可以有效避免不唯一性问题,仍然用上面的栗子来分析,令,,那么

此时发生了变化,解决了不唯一性问题,这就是要加上最大化项的原因了。
2.5 两种数学形式
通过前面的推导,我们得到了Dueling Network的数学形式为
实际中将最大化形式变成均值形式效果更好,更稳定,其数学形式如下

这种替换没有任何理论依据,就是实验效果好,简单!粗暴!有效!
3 Dueling DQN算法代码
经验回放采用集中式均匀回放,代码如下(脚本buffer.py):
import numpy as np
class ReplayBuffer:
def __init__(self, state_dim, action_dim, max_size, batch_size):
self.mem_size = max_size
self.mem_cnt = 0
self.batch_size = batch_size
self.state_memory = np.zeros((self.mem_size, state_dim))
self.action_memory = np.zeros((self.mem_size, ))
self.reward_memory = np.zeros((self.mem_size, ))
self.next_state_memory = np.zeros((self.mem_size, state_dim))
self.terminal_memory = np.zeros((self.mem_size, ), dtype=np.bool)
def store_transition(self, state, action, reward, state_, done):
mem_idx = self.mem_cnt % self.mem_size
self.state_memory[mem_idx] = state
self.action_memory[mem_idx] = action
self.reward_memory[mem_idx] = reward
self.next_state_memory[mem_idx] = state_
self.terminal_memory[mem_idx] = done
self.mem_cnt += 1
def sample_buffer(self):
mem_len = min(self.mem_size, self.mem_cnt)
batch = np.random.choice(mem_len, self.batch_size, replace=False)
states = self.state_memory[batch]
actions = self.action_memory[batch]
rewards = self.reward_memory[batch]
states_ = self.next_state_memory[batch]
terminals = self.terminal_memory[batch]
return states, actions, rewards, states_, terminals
def ready(self):
return self.mem_cnt > self.batch_size
目标网络的更新方式为软更新,Dueling DQN的实现代码如下(脚本Dueling_DQN.py):
import torch as T
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import numpy as np
from buffer import ReplayBuffer
device = T.device("cuda:0" if T.cuda.is_available() else "cpu")
class DuelingDeepQNetwork(nn.Module):
def __init__(self, alpha, state_dim, action_dim, fc1_dim, fc2_dim):
super(DuelingDeepQNetwork, self).__init__()
self.fc1 = nn.Linear(state_dim, fc1_dim)
self.fc2 = nn.Linear(fc1_dim, fc2_dim)
self.V = nn.Linear(fc2_dim, 1)
self.A = nn.Linear(fc2_dim, action_dim)
self.optimizer = optim.Adam(self.parameters(), lr=alpha)
self.to(device)
def forward(self, state):
x = T.relu(self.fc1(state))
x = T.relu(self.fc2(x))
V = self.V(x)
A = self.A(x)
return V, A
def save_checkpoint(self, checkpoint_file):
T.save(self.state_dict(), checkpoint_file, _use_new_zipfile_serialization=False)
def load_checkpoint(self, checkpoint_file):
self.load_state_dict(T.load(checkpoint_file))
class DuelingDQN:
def __init__(self, alpha, state_dim, action_dim, fc1_dim, fc2_dim, ckpt_dir,
gamma=0.99, tau=0.005, epsilon=1.0, eps_end=0.01, eps_dec=5e-4,
max_size=1000000, batch_size=256):
self.gamma = gamma
self.tau = tau
self.batch_size = batch_size
self.epsilon = epsilon
self.eps_min = eps_end
self.eps_dec = eps_dec
self.checkpoint_dir = ckpt_dir
self.action_space = [i for i in range(action_dim)]
self.q_eval = DuelingDeepQNetwork(alpha=alpha, state_dim=state_dim, action_dim=action_dim,
fc1_dim=fc1_dim, fc2_dim=fc2_dim)
self.q_target = DuelingDeepQNetwork(alpha=alpha, state_dim=state_dim, action_dim=action_dim,
fc1_dim=fc1_dim, fc2_dim=fc2_dim)
self.memory = ReplayBuffer(state_dim=state_dim, action_dim=action_dim,
max_size=max_size, batch_size=batch_size)
self.update_network_parameters(tau=1.0)
def update_network_parameters(self, tau=None):
if tau is None:
tau = self.tau
for q_target_params, q_eval_params in zip(self.q_target.parameters(), self.q_eval.parameters()):
q_target_params.data.copy_(tau * q_eval_params + (1 - tau) * q_target_params)
def remember(self, state, action, reward, stata_, done):
self.memory.store_transition(state, action, reward, stata_, done)
def decrement_epsilon(self):
self.epsilon = self.epsilon - self.eps_dec \\
if self.epsilon > self.eps_min else self.eps_min
def choose_action(self, observation, isTrain=True):
state = T.tensor([observation], dtype=T.float).to(device)
_, A = self.q_eval.forward(state)
action = T.argmax(A).item()
if (np.random.random() < self.epsilon) and isTrain:
action = np.random.choice(self.action_space)
return action
def learn(self):
if not self.memory.ready():
return
states, actions, rewards, next_states, terminals = self.memory.sample_buffer()
batch_idx = T.arange(self.batch_size, dtype=T.long).to(device)
states_tensor = T.tensor(states, dtype=T.float).to(device)
actions_tensor = T.tensor(actions, dtype=T.long).to(device)
rewards_tensor = T.tensor(rewards, dtype=T.float).to(device)
next_states_tensor = T.tensor(next_states, dtype=T.float).to(device)
terminals_tensor = T.tensor(terminals).to(device)
with T.no_grad():
V_, A_ = self.q_target.forward(next_states_tensor)
q_ = V_ + A_ - T.mean(A_, dim=-1, keepdim=True)
q_[terminals_tensor] = 0.0
target = rewards_tensor + self.gamma * T.max(q_, dim=-1)[0]
V, A = self.q_eval.forward(states_tensor)
q = (V + A - T.mean(A, dim=-1, keepdim=True))[batch_idx, actions_tensor]
loss = F.mse_loss(q, target.detach())
self.q_eval.optimizer.zero_grad()
loss.backward()
self.q_eval.optimizer.step()
self.update_network_parameters()
self.decrement_epsilon()
def save_models(self, episode):
self.q_eval.save_checkpoint(self.checkpoint_dir + 'Q_eval/DuelingDQN_q_eval_.pth'.format(episode))
print('Saving Q_eval network successfully!')
self.q_target.save_checkpoint(self.checkpoint_dir + 'Q_target/DuelingDQN_Q_target_.pth'.format(episode))
print('Saving Q_target network successfully!')
def load_models(self, episode):
self.q_eval.load_checkpoint(self.checkpoint_dir + 'Q_eval/DuelingDQN_q_eval_.pth'.format(episode))
print('Loading Q_eval network successfully!')
self.q_target.load_checkpoint(self.checkpoint_dir + 'Q_target/DuelingDQN_Q_target_.pth'.format(episode))
print('Loading Q_target network successfully!')算法仿真环境为gym库中的LunarLander-v2,因此需要先配置好gym库。进入Anaconda3中对应的Python环境中,执行下面的指令
pip install gym但是,这样安装的gym库只包括少量的内置环境,如算法环境、简单文字游戏和经典控制环境,无法使用LunarLander-v2。因此还需要安装一些其他依赖项,具体可以参考我的这篇博文:AttributeError: module ‘gym.envs.box2d‘ has no attribute ‘LunarLander‘ 解决办法
让智能体在环境中训练500轮,训练代码如下(脚本train.py):
import gym
import numpy as np
import argparse
from utils import plot_learning_curve, create_directory
from Dueling_DQN import DuelingDQN
parser = argparse.ArgumentParser()
parser.add_argument('--max_episodes', type=int, default=500)
parser.add_argument('--ckpt_dir', type=str, default='./checkpoints/DuelingDQN/')
parser.add_argument('--reward_path', type=str, default='./output_images/reward.png')
parser.add_argument('--epsilon_path', type=str, default='./output_images/epsilon.png')
args = parser.parse_args()
def main():
env = gym.make('LunarLander-v2')
agent = DuelingDQN(alpha=0.0003, state_dim=env.observation_space.shape[0], action_dim=env.action_space.n,
fc1_dim=256, fc2_dim=256, ckpt_dir=args.ckpt_dir, gamma=0.99, tau=0.005, epsilon=1.0,
eps_end=0.05, eps_dec=5e-4, max_size=1000000, batch_size=256)
create_directory(args.ckpt_dir, sub_dirs=['Q_eval', 'Q_target'])
total_rewards, avg_rewards, eps_history = [], [], []
for episode in range(args.max_episodes):
total_reward = 0
done = False
observation = env.reset()
while not done:
action = agent.choose_action(observation, isTrain=True)
observation_, reward, done, info = env.step(action)
agent.remember(observation, action, reward, observation_, done)
agent.learn()
total_reward += reward
observation = observation_
total_rewards.append(total_reward)
avg_reward = np.mean(total_rewards[-100:])
avg_rewards.append(avg_reward)
eps_history.append(agent.epsilon)
print('EP: reward: avg_reward: epsilon:'.
format(episode + 1, total_reward, avg_reward, agent.epsilon))
if (episode + 1) % 50 == 0:
agent.save_models(episode + 1)
episodes = [i for i in range(args.max_episodes)]
plot_learning_curve(episodes, avg_rewards, 'Reward', 'reward', args.reward_path)
plot_learning_curve(episodes, eps_history, 'Epsilon', 'epsilon', args.epsilon_path)
if __name__ == '__main__':
main()训练时还会用到画图函数和创建文件夹函数,它们均放置在utils.py脚本中,具体代码如下:
import os
import matplotlib.pyplot as plt
def plot_learning_curve(episodes, records, title, ylabel, figure_file):
plt.figure()
plt.plot(episodes, records, linestyle='-', color='r')
plt.title(title)
plt.xlabel('episode')
plt.ylabel(ylabel)
plt.show()
plt.savefig(figure_file)
def create_directory(path: str, sub_dirs: list):
for sub_dir in sub_dirs:
if os.path.exists(path + sub_dir):
print(path + sub_dir + ' is already exist!')
else:
os.makedirs(path + sub_dir, exist_ok=True)
print(path + sub_dir + ' create successfully!')仿真结果如下图所示:
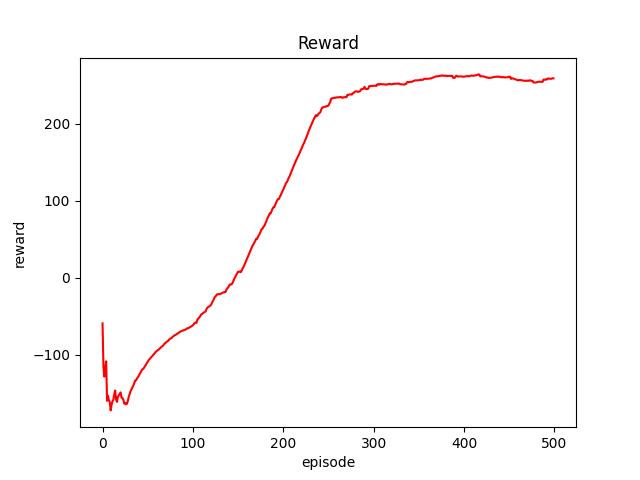
平均累积奖励曲线

epsilon变化曲线
通过平均累积奖励可以看出,Dueling DQN算法大约在250步时趋于收敛。
以上是关于深度强化学习-Dueling DQN算法原理与代码的主要内容,如果未能解决你的问题,请参考以下文章
(pytorch复现)基于深度强化学习(CNN+dueling network/DQN/DDQN/D3QN)的自适应车间调度(JSP)
(pytorch复现)基于深度强化学习(CNN+dueling network/DQN/DDQN/D3QN)的自适应车间调度(JSP)
(pytorch复现)基于深度强化学习(CNN+dueling network/DQN/DDQN/D3QN/PER)的自适应车间调度(JSP)