基于Kubernetes的hpa实现pod实例数量的自动伸缩
Posted DrunkCat90
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于Kubernetes的hpa实现pod实例数量的自动伸缩相关的知识,希望对你有一定的参考价值。
Pod 是在 Kubernetes 体系中,承载用户业务负载的一种资源。Pod 们运行的好坏,是用户们最为关心的事情。在业务流量高峰时,手动快速扩展 Pod 的实例数量,算是玩转 Kubernetes 的基本操作。实际上这个操作还可以更加自动化,运维人员可以事先设置好规则,让 Pod 实例的数量,在指定情况下自动的调整实例的数量,这一操作依靠 Horizontal Pod Autoscaler 来实现。
场景描述
如果企业应用的最终用户是人,那么它的访问压力情况,都会有潮汐特征。好比一款供企业内部人员使用的OA系统,工作日的流量远比休息日高,工作时间的流量远比下班时间高。那么可否让这款 OA 系统根据流量的大小,自动调整实例的数量。令其忙时启动足够数量的实例抵御访问压力,闲时自动降低实例数量,将资源留给其他企业应用。
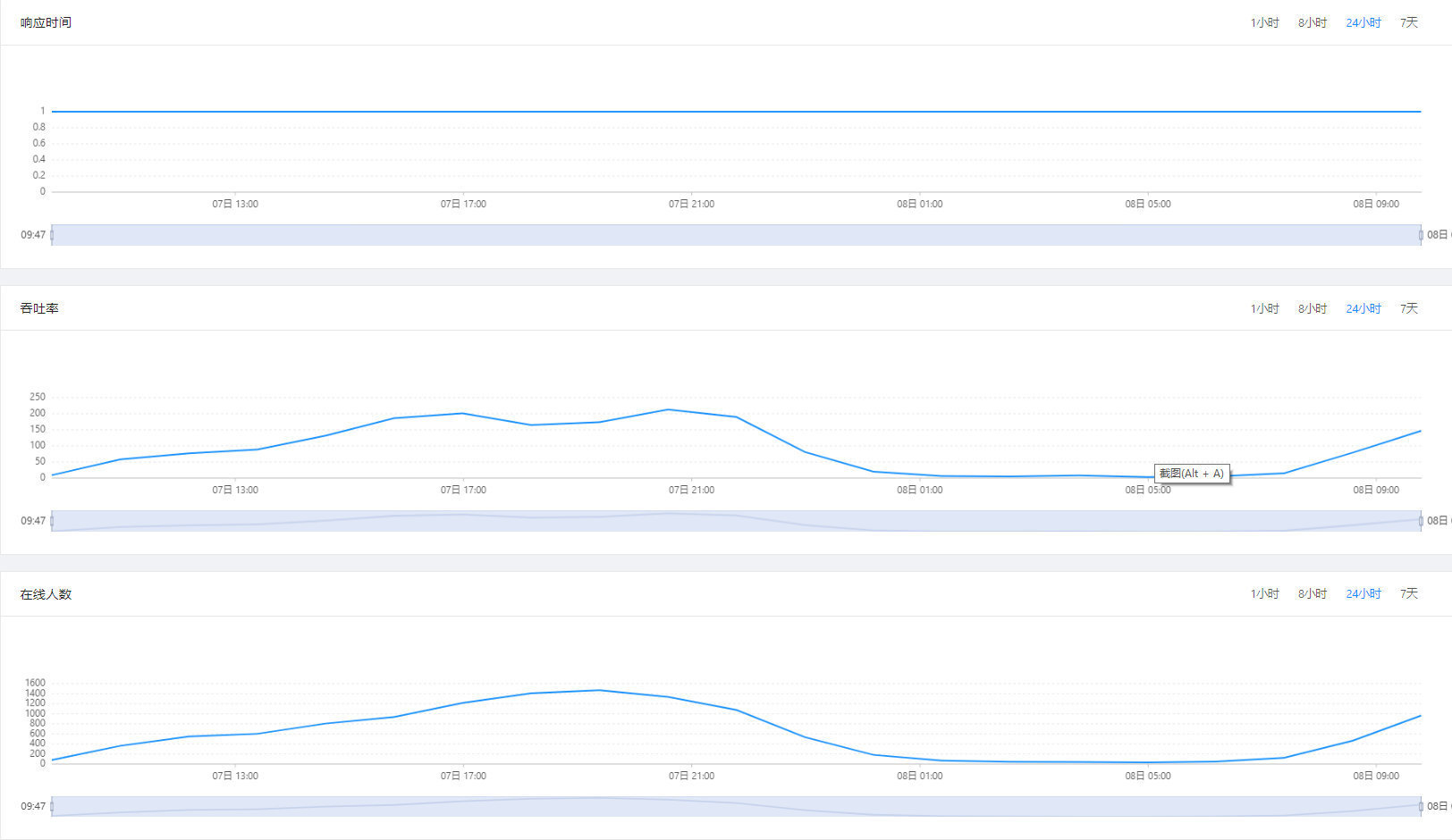
下图是某个业务系统,在 24 小时内的性能监控曲线。其吞吐率和在线人数曲线都可以反映出一定的潮汐特性:
- 午夜 0 点直到次日早上8 点,这个系统都处于无人使用的状态。在这一段时间里,可以自动将业务系统的实例数量降下来,释放一些计算资源。
- 上午 9 点直到晚间 21 点为系统使用高峰期,最高在线人数达到 1600 人。在这一段时间里,业务系统的实例数量可以自动提升起来,满足业务的需要。
关于 hpa
Kubernetes 在 1.2 版本开始支持了 Horizontal Pod Autoscaler(hpa) ,来应对 Pod 实例的自动伸缩场景。它可以基于实例的 CPU 使用率来决定是否为 Pod 进行实例数量的扩容。我们知道 Pod 的副本数量是被其控制器的配置所决定的,比如 Deployment、StatefulSet、ReplicaSet 。所以,hpa 是在获取了 Pod 实际 CPU 使用率这一指标,和扩展实例的目标指标对比后,操作了其控制器来实现副本数量的扩缩的。
了解了以上内容后,我们起码可以知道,在使用 hpa 进行自动伸缩的设置之前,Kubernetes 集群和 Pod 的控制器都应该符合一定的先决条件。
- 存在 Metrics-server。Metrics-server 是 Kubernetes 集群范围资源用量数据的聚合器。Pod 的 CPU 使用率这一指标,是从 Metrics-server 中获取 CPU 实际用量之后,与控制器中指定的 Pod 资源做比后所得。大多数 Kubernetes 发行版中都已经默认安装了 Metrics-server ,它一般部署在 kube-system 命名空间中。
- Pod 资源限额。既然使用的指标是 CPU 使用率,那么就必须存在一个 CPU 可用的上限作为分母。这个上限,实际上就是在控制器中规定的 Pod 资源限额
spec.resources.limits.cpu。
创建 hpa
创建 hpa 之前, 我们需要确保 Pod 控制器中规定了CPU资源限额。我当前使用的案例,使用了 Deployment 控制器。其 Pod 的 CPU 资源限额给到 500m。
Kubernetes 体系中,CPU 是一种可以再分的资源,1000m = 1 Core
kubectl get deployment demo-java -n my-namespace -o yaml
返回的结果中,包含了事先设置的资源限额信息:
spec:
resources:
limits:
cpu: 200m
memory: 1Gi
requests:
cpu: 200m
最简单的创建 hpa 的方式,是使用 kubectl autoscale 命令进行操作。下面的示例,意味着在 Pod 的 CPU 使用率超过 50% 之后,将会触发自动伸缩,最多伸缩到 3 个实例。
kubectl autoscale deployment demo-java -n my-namespace --cpu-percent=50 --min=1 --max=3
返回结果:
horizontalpodautoscaler.autoscaling/demo-java autoscaled
创建完成后,我们可以查看 hpa 资源的状态:
kubectl get hpa -n my-namespace
返回结果中,自动伸缩已经被触发,所有实例的综合 CPU 使用率,已经低于设定的值:
hpa 资源只需要被设定一次,就会始终监控 Pod 指标,并根据设定进行自动伸缩
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
demo-java Deployment/demo-java 49%/50% 1 3 2 3m34s
查看 Pod 实际 CPU 使用量,可以得出相应的使用率计算值,和 hpa 中的显示是相符的。
kubectl top pod -n my-namespace
NAME CPU(cores) MEMORY(bytes)
demo-java-7d6d7d4c9c-lz8sw 197m 87Mi
demo-java-7d6d7d4c9c-52sdl 1m 90Mi
另一种创建 hpa 的方式,是通过 yaml 文件进行定义。我们可以将已存在的 hpa 资源导出,便可以了解这一资源的定义方式。
kubectl get hpa demo-java -n my-namespace -o yaml > hpa.yaml
其定义方式可以归结如下:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: demo-java
namespace: my-namespace
spec:
maxReplicas: 3
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: demo-java
targetCPUUtilizationPercentage: 50
通过命令,可以将这一yaml文件加载进 Kubernetes 集群:
kubectl apply -f hpa.yaml
更多的伸缩指标
在上一个章节,已经实现基于 Pod 的 CPU 使用率来进行自动伸缩。利用 CPU 使用率作为伸缩判定指标,是官方默认提供的方式。那么是否还有其他类型的指标可以作为伸缩判定指标呢?这需要 Kubernetes 用户自行扩展。
我建议从两个方向挑选更多的伸缩判定指标。第一个方向是资源的选择,相较于 CPU 而言,内存也可以作为判定指标;第二个方向是维度,相较于使用率而言,使用量也可以作为判定指标。两个方向彼此组合之后,除了 CPU 使用率,我们还得到了另外 3 种伸缩判定指标:
- CPU 使用量,单位 m
- 内存使用率,单位 %
- 内存使用量,单位 MB
在 CPU 与内存之间,个人更建议使用内存作为伸缩指标,原因是资源的不可压缩性。CPU 是一种可以压缩的资源,而内存不是,资源可压缩意味着当 Pod 的 CPU 用量无限接近于资源限额时,对 Pod 实例的影响很小,只是性能表现不佳而已。但是当 Pod 的内存用量无限接近于资源限额时, Kubernetes 会对 Pod 执行 OOM kill 操作,这对业务的影响很大。如果当内存用量/率达到一定程度,Pod 的实例数量得到了扩展,就有可能避免 Pod 被系统杀死重启。
Kubernetes 官方提供了如何扩展指标的方案,但这对于一般的用户而言并不好掌握。我的建议是选用市面上可见的基于 Kubernetes 实现的应用管理平台。它们往往已经将自动伸缩功能封装成为简单易用的功能,并且提供了上述几种伸缩判断指标。推荐使用北京好雨科技开源的 Rainbond 云原生管理平台。
Rainbond 目前已经集成了开箱可用的自动伸缩功能,下面是功能截图。

功能界面已经将易用性做到了极致,即使不去关注之前章节所写的纯技术内容,也可以掌握相关的设置。
在这个功能界面的示例中,将 CPU 使用率和内存使用率同时设定了。在 Kubernetes 中,一旦出现同个 hpa 设定中,包含了多个判定条件时,会分别计算在每一种条件下,满足条件的 Pod 实例数量,并在所有结果之中选择最大值作为最终的实例数量。
更多需要了解的内容,可以参考 Kubernetes 官方手册
以上是关于基于Kubernetes的hpa实现pod实例数量的自动伸缩的主要内容,如果未能解决你的问题,请参考以下文章