ML-Agents案例之蠕虫
Posted 微笑小星
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ML-Agents案例之蠕虫相关的知识,希望对你有一定的参考价值。
本案例源自ML-Agents官方的示例,Github地址:https://github.com/Unity-Technologies/ml-agents,本文是详细的配套讲解。
本文基于我前面发的两篇文章,需要对ML-Agents有一定的了解,详情请见:Unity强化学习之ML-Agents的使用、ML-Agents命令及配置大全。
我前面的相关文章有:

环境说明
本环境可以参考ML-Agents案例之Crawler,两者的环境极其相似,都是仿生机器人,不同的只是仿生的对象不同,一个是蠕虫,一个是爬虫。奖励目标也是一致的,我们需要训练的是一个蠕虫形状的仿生机器人,让它自己学会蠕动前行,面向目标行走,最后吃到绿色的方块,并且这个过程越迅速越好。
首先我们来讲讲智能体本身的构造:

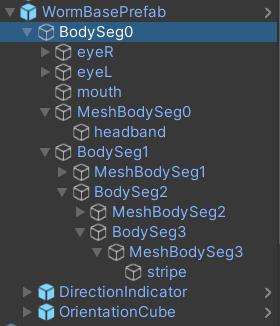
如上图所示,蠕虫分为四个部分。分别是一个头部和三节身躯(可以自己拓展到任意节数),四个部分由三个关节连接而成,可以看到,第一节身躯是头部的子物体,第二节身躯是第一节身躯的子物体,第三节身躯是第二节的子物体。(这里我个人的想法是四个部分应该相互独立,而不是子物体关系,否则前面关节的移动将导致后面整体的移动,待验证,可以自己改一下看看能否训练起来)
下面是第一个关节的设置:
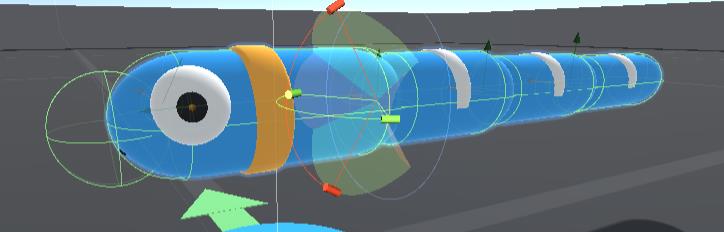
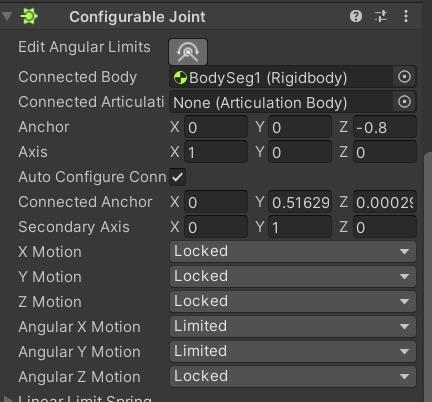
可以看到这个关节的位置移动是锁定的,对于角度移动锁定了z轴,对于x轴和y轴限制一定角度的移动,如上图所示,我们可以通过Edit Angular Limits可视化调节。第二第三个关节同理。
想要控制各个关节的运动,我们需要在智能体上挂载一个JointDriveController.cs的脚本,这个脚本不会自己运作,只有在别的脚本的调用下才会起作用。关于这个脚本的代码说明参考ML-Agents案例之Crawler。
状态输入:首先是整个身体的主干部分到地面的距离,一维。目标的前进向量,三维。目标向量与智能体本体的朝向的夹角除以180,一维。智能体本体的朝向到目标朝向的旋转,四元数,四维。目标方块相对于智能体的坐标,三维。每节躯体的移动速度和角速度和是否接触地面,4 * 7维,每个关节的力度,3 * 1维。除了头部的躯体相对于头部的位置以及旋转,3 * 7维。一共是64维。
动作输出:三个关节,每个关节有x,y两个轴可以旋转,还需要输出关节转动的力度,一共有3 * 3共9维的连续输出。
代码讲解
我们直接看WormAgents.cs脚本:
定义变量
const float m_MaxWalkingSpeed = 10; //最高行走速度
[Header("Target Prefabs")] public Transform TargetPrefab; // 目标方块
private Transform m_Target;
// 智能体的四节躯体位置
[Header("Body Parts")] public Transform bodySegment0;
public Transform bodySegment1;
public Transform bodySegment2;
public Transform bodySegment3;
//这个方块的设置为一个稳定的空间参考点,可以提高学习效果
OrientationCubeController m_OrientationCube;
// 箭头指示器的脚本
DirectionIndicator m_DirectionIndicator;
JointDriveController m_JdController;
private Vector3 m_StartingPos; //starting position of the agent
初始化方法Initialize():
public override void Initialize()
SpawnTarget(TargetPrefab, transform.position); // 生成目标方块
m_StartingPos = bodySegment0.position; // 头部是整个身躯的父物体,代表整个身躯的初始位置
m_OrientationCube = GetComponentInChildren<OrientationCubeController>();
m_DirectionIndicator = GetComponentInChildren<DirectionIndicator>();
m_JdController = GetComponent<JointDriveController>();
// 更新自己身上的指向方块
UpdateOrientationObjects();
// 初始化各节身躯
m_JdController.SetupBodyPart(bodySegment0);
m_JdController.SetupBodyPart(bodySegment1);
m_JdController.SetupBodyPart(bodySegment2);
m_JdController.SetupBodyPart(bodySegment3);
// 生成目标方块
void SpawnTarget(Transform prefab, Vector3 pos)
m_Target = Instantiate(prefab, pos, Quaternion.identity, transform.parent);
// 更新自己身上的指向方块以及地上的指向箭头
void UpdateOrientationObjects()
// 更新指向箭头
m_OrientationCube.UpdateOrientation(bodySegment0, m_Target);
// 更新指向方块
if (m_DirectionIndicator)
m_DirectionIndicator.MatchOrientation(m_OrientationCube.transform);
在OrentationCubeController.cs中有:
public void UpdateOrientation(Transform rootBP, Transform target)
var dirVector = target.position - transform.position;
dirVector.y = 0; //flatten dir on the y. this will only work on level, uneven surfaces
var lookRot =
dirVector == Vector3.zero
? Quaternion.identity
: Quaternion.LookRotation(dirVector); //get our look rot to the target
//UPDATE ORIENTATION CUBE POS & ROT
transform.SetPositionAndRotation(rootBP.position, lookRot);
状态输入CollectObservations方法:
// 对于每节身躯的输入
public void CollectObservationBodyPart(BodyPart bp, VectorSensor sensor)
// 是否接触地面
sensor.AddObservation(bp.groundContact.touchingGround ? 1 : 0);
// 相对于指向方块空间中的刚体速度和角速度,如果是输入是世界空间中的向量,效果会不好
sensor.AddObservation(m_OrientationCube.transform.InverseTransformDirection(bp.rb.velocity));
sensor.AddObservation(m_OrientationCube.transform.InverseTransformDirection(bp.rb.angularVelocity));
// 后面三节身躯相对于头部的位置和本地的空间旋转
if (bp.rb.transform != bodySegment0)
sensor.AddObservation(
m_OrientationCube.transform.InverseTransformDirection(bp.rb.position - bodySegment0.position));
sensor.AddObservation(bp.rb.transform.localRotation);
// 输入每个关节的控制力度
if (bp.joint)
sensor.AddObservation(bp.currentStrength / m_JdController.maxJointForceLimit);
public override void CollectObservations(VectorSensor sensor)
// 输入身躯与地面的距离
RaycastHit hit;
float maxDist = 10;
if (Physics.Raycast(bodySegment0.position, Vector3.down, out hit, maxDist))
sensor.AddObservation(hit.distance / maxDist);
else
sensor.AddObservation(1);
var cubeForward = m_OrientationCube.transform.forward;
var velGoal = cubeForward * m_MaxWalkingSpeed;
// 输入目标的移动速度(三维向量)
sensor.AddObservation(m_OrientationCube.transform.InverseTransformDirection(velGoal));
// 输入现在的rotation和目标rotation的夹角
sensor.AddObservation(Quaternion.Angle(m_OrientationCube.transform.rotation,
m_JdController.bodyPartsDict[bodySegment0].rb.rotation) / 180);
// 输入现在的前进方向到目标前进方向的四元数
sensor.AddObservation(Quaternion.FromToRotation(bodySegment0.forward, cubeForward));
// 输入目标方块相对于自身的坐标
sensor.AddObservation(m_OrientationCube.transform.InverseTransformPoint(m_Target.transform.position));
// 每一节身躯的输入,详情看上面的CollectObservationBodyPart方法
foreach (var bodyPart in m_JdController.bodyPartsList)
CollectObservationBodyPart(bodyPart, sensor);
动作输出方法OnActionReceived:
public override void OnActionReceived(ActionBuffers actionBuffers)
// 获取身躯的字典
var bpDict = m_JdController.bodyPartsDict;
var i = -1;
// 获取连续输入的列表
var continuousActions = actionBuffers.ContinuousActions;
// 输入三个关节的旋转
bpDict[bodySegment0].SetJointTargetRotation(continuousActions[++i], continuousActions[++i], 0);
bpDict[bodySegment1].SetJointTargetRotation(continuousActions[++i], continuousActions[++i], 0);
bpDict[bodySegment2].SetJointTargetRotation(continuousActions[++i], continuousActions[++i], 0);
// 输入关节的力度
bpDict[bodySegment0].SetJointStrength(continuousActions[++i]);
bpDict[bodySegment1].SetJointStrength(continuousActions[++i]);
bpDict[bodySegment2].SetJointStrength(continuousActions[++i]);
// 如果掉到地面的下方,结束游戏
if (bodySegment0.position.y < m_StartingPos.y - 2)
EndEpisode();
每一个episode(回合)开始时执行的方法OnEpisodeBegin:
public override void OnEpisodeBegin()
// 重新初始化各个身躯的参数
foreach (var bodyPart in m_JdController.bodyPartsList)
bodyPart.Reset(bodyPart);
// 随机旋转,使得智能体初始时面朝的方向随机
bodySegment0.rotation = Quaternion.Euler(0, Random.Range(0.0f, 360.0f), 0);
// 更新指向方块和指向箭头
UpdateOrientationObjects();
每0.02秒执行一次的FixedUpdate:
void FixedUpdate()
// 更新指向方块和指向箭头
UpdateOrientationObjects();
// 当实际移动速度和目标速度越接近,获得的奖励越高
var velReward =
GetMatchingVelocityReward(m_OrientationCube.transform.forward * m_MaxWalkingSpeed,
m_JdController.bodyPartsDict[bodySegment0].rb.velocity);
// 指向方块的朝向和躯体朝向的夹角
var rotAngle = Quaternion.Angle(m_OrientationCube.transform.rotation,
m_JdController.bodyPartsDict[bodySegment0].rb.rotation);
var facingRew = 0f;
// 当智能体面朝的方向和目标方向的夹角小于30度,给予一定的奖励
if (rotAngle < 30)
facingRew = 1 - (rotAngle / 180);
// 面朝奖励和移动奖励相乘得到实际奖励
AddReward(velReward * facingRew);
public float GetMatchingVelocityReward(Vector3 velocityGoal, Vector3 actualVelocity)
var velDeltaMagnitude = Mathf.Clamp(Vector3.Distance(actualVelocity, velocityGoal), 0, m_MaxWalkingSpeed);
return Mathf.Pow(1 - Mathf.Pow(velDeltaMagnitude / m_MaxWalkingSpeed, 2), 2);
本案例还给环境加上了一个AdjustTrainingTimescale的脚本:
using UnityEngine;
namespace MLAgentsExamples
public class AdjustTrainingTimescale : MonoBehaviour
// Update is called once per frame
void Update()
if (Input.GetKeyDown(KeyCode.Alpha1))
Time.timeScale = 1f;
if (Input.GetKeyDown(KeyCode.Alpha2))
Time.timeScale = 2f;
if (Input.GetKeyDown(KeyCode.Alpha3))
Time.timeScale = 3f;
if (Input.GetKeyDown(KeyCode.Alpha4))
Time.timeScale = 4f;
if (Input.GetKeyDown(KeyCode.Alpha5))
Time.timeScale = 5f;
if (Input.GetKeyDown(KeyCode.Alpha6))
Time.timeScale = 6f;
if (Input.GetKeyDown(KeyCode.Alpha7))
Time.timeScale = 7f;
if (Input.GetKeyDown(KeyCode.Alpha8))
Time.timeScale = 8f;
if (Input.GetKeyDown(KeyCode.Alpha9))
Time.timeScale = 9f;
if (Input.GetKeyDown(KeyCode.Alpha0))
Time.timeScale *= 2f;
这个脚本可以通过按键盘上方的数字键自由调整游戏运行速率。
配置文件
PPO算法:
behaviors:
Worm:
trainer_type: ppo
hyperparameters:
batch_size: 2024
buffer_size: 20240
learning_rate: 0.0003
beta: 0.005
epsilon: 0.2
lambd: 0.95
num_epoch: 3
learning_rate_schedule: linear
network_settings:
normalize: true
hidden_units: 512
num_layers: 3
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.995
strength: 1.0
keep_checkpoints: 5
max_steps: 7000000
time_horizon: 1000
summary_freq: 30000
SAC算法:
behaviors:
Worm:
trainer_type: sac
hyperparameters:
learning_rate: 0.0003
learning_rate_schedule: constant
batch_size: 256
buffer_size: 500000
buffer_init_steps: 0
tau: 0.005
steps_per_update: 20.0
save_replay_buffer: false
init_entcoef: 1.0
reward_signal_steps_per_update: 20.0
network_settings:
normalize: true
hidden_units: 512
num_layers: 3
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.995
strength: 1.0
keep_checkpoints: 5
max_steps: 5000000
time_horizon: 1000
summary_freq: 30000
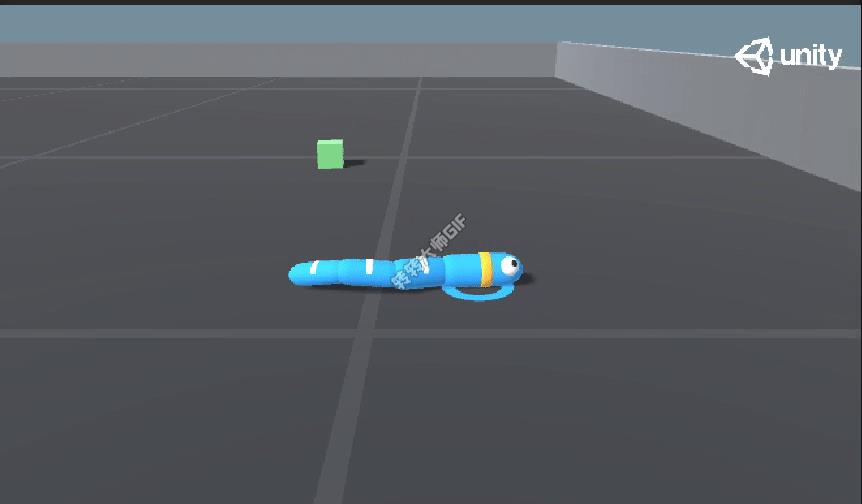
效果演示
后记
本案例是继爬虫机器人Crawler之后的另一个ML-Agents中的仿生机器人的案例,这种案例相比于其他没有关节的智能体来说,难点就是关节和身体各个部位的观测和控制,需要采用更为严格的措施来使训练稳定。例如加入一个指向方块使得输入更加稳定。
和Crawler相比,这里有个新增的ML-Agents实验性的传感器Rigid Body Sensor Component没有用上,这个组件能够给关节提供更好的状态输入接口,对于有关节的智能体来说,可以尝试加上该组件,看看能够改善训练。
以上是关于ML-Agents案例之蠕虫的主要内容,如果未能解决你的问题,请参考以下文章