用生产者消费者模式爬取斗图吧,一次性收获超多表情包python爬虫入门进阶(11)
Posted 码农飞哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用生产者消费者模式爬取斗图吧,一次性收获超多表情包python爬虫入门进阶(11)相关的知识,希望对你有一定的参考价值。
您好,我是码农飞哥,感谢您阅读本文,欢迎一键三连哦。
😁 1. 社区逛一逛,周周有福利,周周有惊喜。码农飞哥社区,飞跃计划
💪🏻 2. Python基础专栏,基础知识一网打尽。 Python从入门到精通
❤️ 3. Ceph实战,从原理到实战应有尽有。 Ceph实战
❤️ 4. Java高并发编程入门,打卡学习Java高并发。 Java高并发编程入门
关注下方公众号,众多福利免费嫖;加我VX进群学习,学习的路上不孤单

为啥写这篇文章?
前两篇文章我们分别介绍了
用正则表达式爬取古诗文网站,边玩边学【python爬虫入门进阶】(09)
CSV文件操作起来还挺方便的【python爬虫入门进阶】(10)
还没来得及看的小伙伴们可以看一波。
本文以斗图吧网站为例,介绍如何将生产者消费者模式运用到爬虫当中以提高爬虫效率。抢先预览一波效果,如下图1所示:
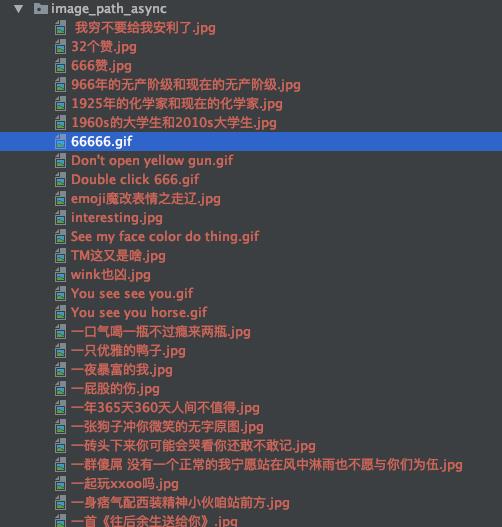
为了方便大家更好的学习交流,我这边建了个Python学习交流群。

Queue 安全队列
在介绍生产者和消费者模式之前,我们首先需要了解多线程的相关知识。如果对多线程还比较模糊的小伙伴可以先看下下面这两篇文章。
【Python从入门到精通】(二十)Python并发编程的基本概念-线程的使用以及生命周期
【Python从入门到精通】(二十一)Python并发编程互斥锁的运用以及线程通信
通读这两篇文章你会掌握线程的创建以及如何运用互斥锁来处理多个线程修改以及访问全局变量的线程安全问题。
如果你不想使用全局变量的方式存储数据,而是想将数据以线程安全的方式存储到某个队列中的话。python内置了一个线程安全的模块叫做queue模块。Python中的queue模块中提供了同步的,线程安全的队列类,包括FIFO(先进先出)队列Queue,LIFO(后进先出)队列 LifoQueue。这些队列都实现了锁原语(可以理解为原子操作),能够在多线程中直接使用。这样就可以使用队列实现线程间的同步。相关的函数如下:
- 初始化 Queue(maxsize):创建一个先进先出的队列
- qsize(): 返回队列的大小
- empty(): 判断队列是否为空
- full() : 判断队列是否满了
- get():从队列中取最后一个数据
- put() : 将一个数据放到队列中。
下面用一张小图说明下队列:
举个小🌰说明下队列的使用:
下面代码定义了两个线程一个线程用于向队列中设值,一个线程用于从队列中取值。设值的那个线程每设完一个值之后会睡眠3秒。
def set_value(feige_queue):
index = 1
while True:
feige_queue.put(index)
print('放入的元素是' + str(index) + ' 队列的大小' + str(feige_queue.qsize()) + "\\n")
index += 1
time.sleep(3)
def get_value(feige_queue):
while True:
index = feige_queue.get()
print('取出的元素是' + str(index) + ' 后队列的大小' + str(feige_queue.qsize()) + "\\n")
def main():
feige_queue = Queue(4)
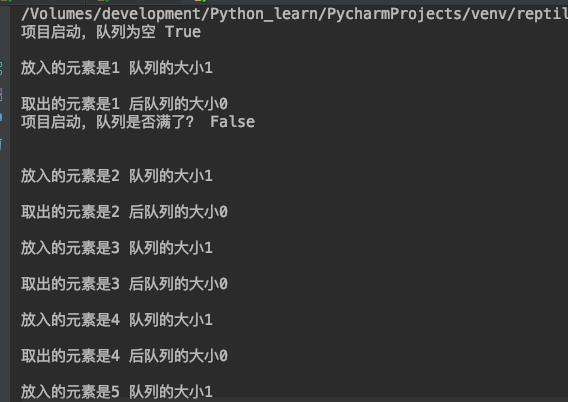
print('项目启动,队列为空', feige_queue.empty() , "\\n")
t1 = threading.Thread(target=set_value, args=(feige_queue,))
t2 = threading.Thread(target=get_value, args=(feige_queue,))
t1.start()
t2.start()
print('项目启动,队列是否满了?', feige_queue.full() , "\\n")
if __name__ == '__main__':
main()
运行结果如下图2所示:
分析页面规律
斗图吧的地址,这里以系列表情包为例,如下图3所示:
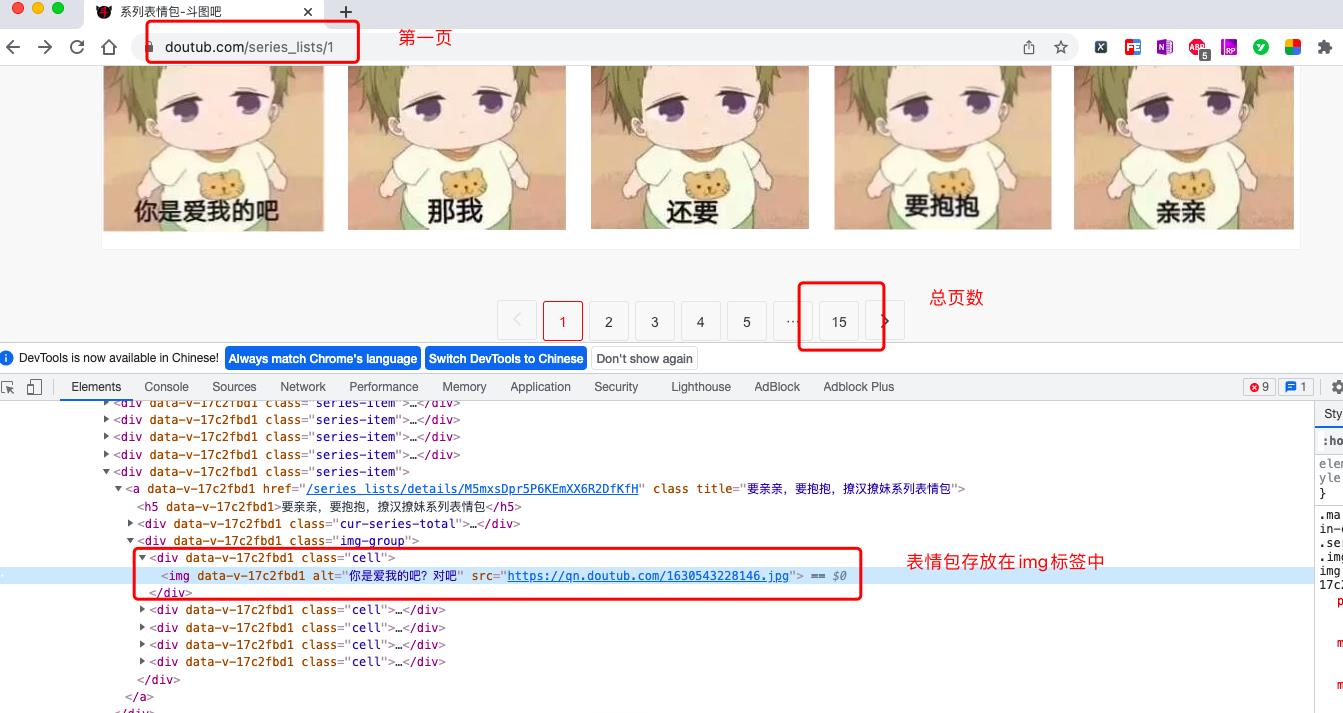
从图3我们可以发现几个规律:
- 第一个规律是:第一页的地址是:https://www.doutub.com/series_lists/1 ,第二页的地址是:https://www.doutub.com/series_lists/2,那么第n页面的地址就是:https://www.doutub.com/series_lists/n。
- 第二个规律是:总页数是15页,被存放在
<a data-v-07bcd2f3="" href="/series_lists/15" class="last" title="系列表情包第15页">15</a>标签中。所以,它的xpath表达式是//a[@class="last"]/text() - 第三个规律是:表情包图片被存放在
<div data-v-17c2fbd1="" class="cell"><img data-v-17c2fbd1="" alt="你是爱我的吧?对吧" src="https://qn.doutub.com/1630543228146.jpg"></div>
中,所以它的xpath表达式是//div[@class="cell"]//img。
单线程爬取表情包
分析完页面规律之后,接下来就是编写代码爬取表情包了。为了让大家更好的理解生产者消费者模式与普通同步模式的不同。这里先用单线程同步模式来爬取表情包。核心代码如下所示:
这里重点介绍了提取页面数据和保存表情包的方法。提取页面数据的方法主要就是获取到存放表情包img标签,接着就是获取表情包链接和表情包的名称。
这里表情包的名称可能有特殊的符号,所以需要通过sub方法进行过滤替换。
def parse_article_list(url):
resp = requests.get(url, headers=headers, verify=False)
html = etree.HTML(resp.content.decode('utf-8'))
# 获取所有的表情包的地址
imgs = html.xpath('//div[@class="cell"]//img')
for img in imgs:
img_url = img.get('src')
filename = img_url.split('/')[-1]
suffix = filename.split('.')[1]
alt = img.get('alt')
# 去掉标题中的特殊符号
alt = re.sub(r'[??\\.,。!!]', '', alt)
if alt is not None and len(alt) != 0:
filename = alt + '.' + suffix
save_img(url, filename)
#保存图片
def save_img(url, filename):
resp = requests.get(url, verify=False)
with open(os.path.join(image_path, filename), 'wb') as f:
f.write(resp.content)
从上面分析可以得出单线程爬取表情包的主要的耗时点:
- 每页数据的爬取都是同步的,某个页面的如果阻塞了就会影响到下一个页面的数据爬取
- 下载网络图片到本地也是比较耗时的一个动作。
生产者和消费者模式爬取表情包
说完了单线程爬取表情包的代码之后,接下来就是介绍运用多线程的生产者和消费者模式来爬取表情包。之所以运用多线程就是为了提高爬取效率。 其主要思路是:
- 定义一个队列page_queue用于存放每页的url地址,比如:
https://www.doutub.com/series_lists/1。 - 定义一个队列img_queue用于存放表情包的url地址。比如:
https://qn.doutub.com/1630543228146.jpg。
就是将这两个耗时的动作改成异步并行执行。用队列可以保证数据的安全。
生产者和消费者的关系如下图4所示:

生产者主要的任务就是消费page_queue队列中的数据,提取每页的表情包链接和表情包的名称,
然后将得到的数据放到队列img_queue中取。
消费者的主要任务就是消费img_queue队列中的数据,然后对将每个表情包图片下载保存到本地。
定义生产者
import threading
class Producer(threading.Thread):
headers =
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36'
def __init__(self, page_queue, img_queue):
super().__init__()
self.page_queue = page_queue
self.img_queue = img_queue
def run(self):
while True:
if self.page_queue.empty():
break
url = self.page_queue.get()
self.parse_page(url)
def parse_page(self, url):
resp = requests.get(url, headers=self.headers, verify=False)
html = etree.HTML(resp.content.decode('utf-8'))
# 获取所有的表情包的地址
imgs = html.xpath('//div[@class="cell"]//img')
for img in imgs:
img_url = img.get('src')
filename = img_url.split('/')[-1]
suffix = filename.split('.')[1]
alt = img.get('alt')
# 去掉标题中的特殊符号
alt = re.sub(r'[??\\.,。!!]', '', alt)
if alt is not None and len(alt) != 0:
filename = alt + '.' + suffix
self.img_queue.put((img_url, filename))
这里通过继承threading.Thread类使生产者成为一个线程,初始化方法__init__ 传入page_queue, img_queue 两个队列参数。需要注意的是__init__ 必须要首先调用它的父类构造方法,不然,就不能成功的创建线程。
这里重点需要介绍的是run方法
def run(self):
while True:
if self.page_queue.empty():
break
url = self.page_queue.get()
self.parse_page(url)
该方法采用一个死循环的方式来不断的消费page_queue队列中的数据。直到page_queue队列为空,就跳出循环,不然死循环无法结束。
parse_page方法作为Producer类的实例方法。在获取到图片的链接和图片名称之后不再是直接调用下载保存的方法。而是将图片链接和文件名以元组的形式保存到img_queue队列中。
定义消费者
class Consumer(threading.Thread):
def __init__(self, page_queue, img_queue):
super().__init__()
self.img_queue = img_queue
self.page_queue = page_queue
def run(self):
while True:
if self.img_queue.empty() and self.page_queue.empty():
break
img_url, filename = self.img_queue.get()
self.save_img(img_url, filename)
def save_img(self, img_url, filename):
resp = requests.get(img_url, verify=False)
with open(os.path.join(image_path, filename), 'wb') as f:
f.write(resp.content)
print(threading.current_thread().getName() + '' + filename + '下载完成')
Consumer类通过继承threading.Thread类成为一个线程类。__init__ 方法同Producer类的构造方法。
同样的,这里还是需要重点介绍下run方法。
def run(self):
while True:
if self.img_queue.empty() and self.page_queue.empty():
break
img_url, filename = self.img_queue.get()
self.save_img(img_url, filename)
run方法定义了一个死循环,在死循环中不断的消费img_queue队列,从中取出图片的地址然后调用save_img方法将图片保存到本地。
该死循环的结束标识是当img_queue队列为空,并且page_queue队列为空时跳出循环。也就是说当没有图片下载并且所有的页面都已经遍历完成。
调用生产者和消费者
生产者类和消费者类定义好之后,接下来就是 1. 创建page_queue队列和img_queue队列,2. 创建生产者的实例和消费者的实例了并启动。相关代码如下:
page_queue = Queue(15)
img_queue = Queue()
for i in range(1, 16):
url = 'https://www.doutub.com/series_lists/%d' % i
page_queue.put(url)
for i in range(5):
producer_thread = Producer(page_queue, img_queue)
producer_thread.start()
for i in range(5):
consumer_thread = Consumer(page_queue, img_queue)
consumer_thread.start()
这里创建了5个生产者和5个消费者。在初始化时就向page_queue队列中放入所有的页面的url地址。
完整代码
"""
@url: https://blog.csdn.net/u014534808
@Author: 码农飞哥
@File: doutula_sync_test.py
@Time: 2021/12/9 18:56
@Desc: 生产者和消费者的模式
"""
import re
import requests
from lxml import etree
import os
from queue import Queue
import ssl
import threading
requests.packages.urllib3.disable_warnings()
image_path = os.path.join(os.path.abspath('.'), 'image_path_async')
if not os.path.exists(image_path):
os.mkdir(image_path)
context = ssl._create_unverified_context()
# 定义生产者
class Producer(threading.Thread):
headers =
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36'
def __init__(self, page_queue, img_queue):
super().__init__()
self.page_queue = page_queue
self.img_queue = img_queue
def run(self):
while True:
if self.page_queue.empty():
break
url = self.page_queue.get()
self.parse_page(url)
def parse_page(self, url):
resp = requests.get(url, headers=self.headers, verify=False)
html = etree.HTML(resp.content.decode('utf-8'))
# 获取所有的表情包的地址
imgs = html.xpath('//div[@class="cell"]//img')
for img in imgs:
img_url = img.get('src')
filename = img_url.split('/')[-1]
suffix = filename.split('.')[1]
alt = img.get('alt')
# 去掉标题中的特殊符号
alt = re.sub(r'[??\\.,。!!]', '', alt)
if alt is not None and len(alt) != 0:
filename = alt + '.' + suffix
self.img_queue.put((img_url, filename))
# 定义消费者
class Consumer(threading.Thread):
def __init__(self, page_queue, img_queue):
super().__init__()
self.img_queue = img_queue
self.page_queue = page_queue
def run(self):
while True:
if self.img_queue.empty() and self.page_queue.empty():
break
img_url, filename = self.img_queue.get()
self.save_img(img_url, filename)
def save_img(self, img_url, filename):
resp = requests.get(img_url, verify=False)
with open(os.path.join(image_path, filename), 'wb') as f:
f.write(resp.content)
print(threading.current_thread().getName() + '' + filename + '下载完成')
if __name__ == '__main__':
page_queue = Queue(15)
img_queue = Queue()
for i in range(1, 16):
url = 'https://www.doutub.com/series_lists/%d' % i
page_queue.put(url)
for i in range(5):
producer_thread = Producer(page_queue, img_queue)
producer_thread.start()
for i in range(5):
consumer_thread = Consumer(page_queue, img_queue)
consumer_thread.start()
总结
本文以生产者消费者模式爬取斗图吧中的表情包为例,介绍了如何通过多线程,生产者消费者的模式来提高爬取效率。
粉丝专属福利
软考资料:实用软考资料
面试题:5G 的Java高频面试题
学习资料:50G的各类学习资料
脱单秘籍:回复【脱单】
并发编程:回复【并发编程】
👇🏻 验证码 可通过搜索下方 公众号 获取👇🏻
以上是关于用生产者消费者模式爬取斗图吧,一次性收获超多表情包python爬虫入门进阶(11)的主要内容,如果未能解决你的问题,请参考以下文章