Python A*算法的简单实现
Posted 暗光之痕
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python A*算法的简单实现相关的知识,希望对你有一定的参考价值。
总起
A*算法常用于游戏的寻路中,用于求解静态路网中的最短路径,是最有效的直接搜索方法。
这次正好花了几天时间学习了一下Python,便拿这个算法做了一下练习。这篇文章也会对其思路做一个简单介绍。
文章中的源码可以在 GitHub - anguangzhihen/PythonTest 中的AStarTest.py找到。
算法思路
A*算法实际是由广度优先遍历和Dijkstra算法演变而来的:
1.广度优先遍历主要是通过从起点依次遍历周围的点而寻找最优的路径;
2.Dijkstra基本思路跟广度优先遍历一样,只不过给每次遍历的点增加了一个权值,用于表明当前移动了多少距离,然后每次从移动最短距离的点开始遍历;
3.A*在Dijkstra算法增加了一个期望值(启发函数,h),最优化遍历节点的数量。
广度优先遍历 -> Dijkstra算法 -> A*算法。其他寻路相关的算法也很多,如JPS跳点算法,但解决问题的侧重点不同,关键是针对具体问题选择合适的算法。
我们先来看一下地图,橙点为起始点和终点:

本文中,g为已走过的距离,h为期望距离、启发值。文中会频繁使用这两个概念。
A*算法中的h,根据实际地图的拓扑结构,可选用以下三种距离,假设A与B点横纵坐标距离x和y:
1.曼哈顿距离,只允许4个方向移动,AB的距离为:x + y;
2.对角距离,允许8方向移动,AB的距离为:x + y + (sqrt(2)-2)*min(x, y);
3.欧几里得距离,允许任意方向移动,AB的距离为:sqrt(pow2(x)+pow2(y));
网格结构常用的便是8方向移动,所以我们这边会选择对角距离作为h。
数据结构
我在处理程序问题一般是:先定义数据结构,然后再补充算法本体。
我们这次先从底层的数据结构逐级往上定义。从点、路径到整个地图(我这边只展示关键的数据结构代码):
# 点的定义
class Vector2:
x = 0
y = 0
def __init__(self, x, y):
self.x = x
self.y = y
# 树结构,用于回溯路径
class Vector2Node:
pos = None # 当前的x、y位置
frontNode = None # 当前节点的前置节点
childNodes = None # 当前节点的后置节点们
g = 0 # 起点到当前节点所经过的距离
h = 0 # 启发值
D = 1
def __init__(self, pos):
self.pos = pos
self.childNodes = []
def f(self):
return self.g + self.h
# 地图
class Map:
map = None # 地图,0是空位,1是障碍
startPoint = None # 起始点
endPoint = None # 终点
tree = None # 已经搜寻过的节点,是closed的集合
foundEndNode = None # 寻找到的终点,用于判断算法结束
def __init__(self, startPoint, endPoint):
self.startPoint = startPoint
self.endPoint = endPoint
row = [0]*MAP_SIZE
self.map = []
for i in range(MAP_SIZE):
self.map.append(row.copy())
# 判断当前点是否超出范围
def isOutBound(self, pos):
return pos.x < 0 or pos.y < 0 or pos.x >= MAP_SIZE or pos.y >= MAP_SIZE
# 判断当前点是否是障碍点
def isObstacle(self, pos):
return self.map[pos.y][pos.x] == 1
# 判断当前点是否已经遍历过
def isClosedPos(self, pos):
if self.tree == None:
return False
nodes = []
nodes.append(self.tree)
while len(nodes) != 0:
node = nodes.pop()
if node.pos == pos:
return True
if node.childNodes != None:
for nodeTmp in node.childNodes:
nodes.append(nodeTmp)
return False
PS.我们这边使用matplotlib作为图像输出,具体怎么使用或怎么使其更好看可以参考源代码或第一篇参考文章。
算法实现
A*算法的大概思路是:
1.从起始点开始遍历周围的点(专业点的说法是放到了一个open集合中,而我们这边的变量名叫做willProcessNodes);
2.从open集合中寻找估值,即使用Vector2Node.f()函数计算的值,最小的点作为下一个遍历的对象;
3.重复上面的步骤,直到找到了终点。
具体实现:
# 地图
class Map:
def process(self):
# 初始化open集合,并把起始点放入
willProcessNodes = deque()
self.tree = Vector2Node(self.startPoint)
willProcessNodes.append(self.tree)
# 开始迭代,直到找到终点,或找完了所有能找的点
while self.foundEndNode == None and len(willProcessNodes) != 0:
# 寻找下一个最合适的点,这里是最关键的函数,决定了使用什么算法
node = self.popLowGHNode(willProcessNodes)
if self.addNodeCallback != None:
self.addNodeCallback(node.pos)
# 获取合适点周围所有的邻居
neighbors = self.getNeighbors(node.pos)
for neighbor in neighbors:
# 初始化邻居,并计算g和h
childNode = Vector2Node(neighbor)
childNode.frontNode = node
childNode.calcGH(self.endPoint)
node.childNodes.append(childNode)
# 添加到open集合中
willProcessNodes.append(childNode)
# 找到了终点
if neighbor == self.endPoint :
self.foundEndNode = childNode
# 广度优先,直接弹出先遍历到的节点
def popLeftNode(self, willProcessNodes):
return willProcessNodes.popleft()
# dijkstra,寻找g最小的节点
def popLowGNode(self, willProcessNodes):
foundNode = None
for node in willProcessNodes:
if foundNode == None:
foundNode = node
else:
if node.g < foundNode.g:
foundNode = node
if foundNode != None:
willProcessNodes.remove(foundNode)
return foundNode
# A*,寻找f = g + h最小的节点
def popLowGHNode(self, willProcessNodes):
foundNode = None
for node in willProcessNodes:
if foundNode == None:
foundNode = node
else:
if node.f() < foundNode.f():
foundNode = node
if foundNode != None:
willProcessNodes.remove(foundNode)
return foundNode
我们可以看到在寻找点的时候使用了popLowGHNode,这是使用A*的关键函数,可以替换成上面两个函数使用不同的算法。以下展示使用不同算法的效果。
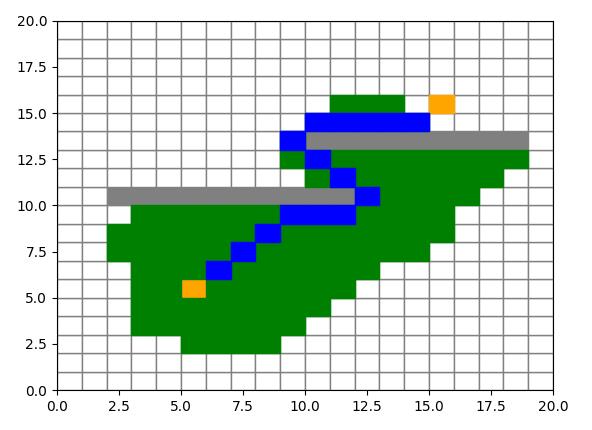
广度优先遍历(绿点代表遍历过的,蓝点代表路径结果):

Dijkstra算法:
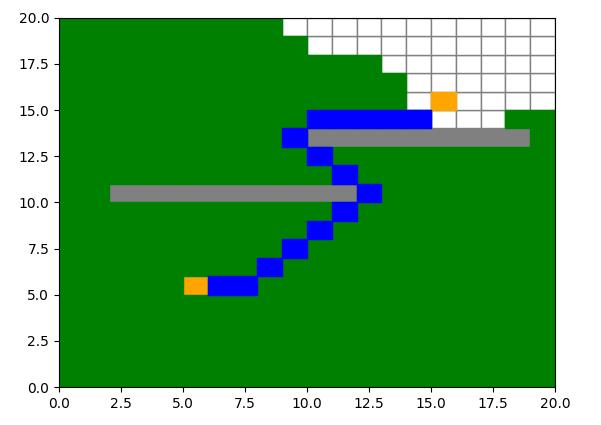
A*算法:
在A*的实现中,h的计算也是个重要的参数,像是本文上面中使用真实的预估距离作为h,为了方便我们称该值为d:
1.h = 0,即Dijkstra算法;
2.h < d,预估值有一定的用处,但相比 h = d 而言性能较差;
3.h = d,性能最优,并且能找到最佳路径;
4.h > d,性能可能进一步优化(也可能更差),但不一定是最优路径;
5.h >> g,变成了最佳优先搜索。
可以尝试调节Vector2Node.D查看效果。
参考
《游戏人工智能编程案例精粹》
以上是关于Python A*算法的简单实现的主要内容,如果未能解决你的问题,请参考以下文章