RabbitMQ01_消息队列概述使用场景劣势架构图与主要概念Docker快速安装Rabbitmq角色分类
Posted 所得皆惊喜
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RabbitMQ01_消息队列概述使用场景劣势架构图与主要概念Docker快速安装Rabbitmq角色分类相关的知识,希望对你有一定的参考价值。
文章目录
①. 消息队列概述
-
①. 消息中间(消息队列)是分布式系统中重要的组件,主要解决应用耦合,异步消息,流量削锋等问题实现高性能,高可用,可伸缩和最终一致性[架构]使用较多的消息队列有ActiveMQ,RabbitMQ,ZeroMQ, Kafka,MetaMQ,RocketMQ
-
②. 消息中间件的本质及设计:接受数据、接受请求、存储数据、发送数据等功能的技术服务
-
③. AMQP:(全称:Advanced Message Queuing Protocol)是高级消息队列协议。由摩根大通集团联合其他公司共同设计。是一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。基于此协议的客户端与消息中间件可传递消息,并不受客户端/中间件不同产品,不同的开发语言等条件的限制。Erlang中的实现由RabbitMQ等
-
④. 为什么消息中间件不直接使用http协议?
- 因为http请求报文头和响应报文头是比较复杂的,包含了Cookie,数据的加密解密,窗台吗,响应码等附加的功能,但是对于一个消息而言,我们并不需要这么复杂,也没有这个必要性,MQ其实就是负责数据传递,存储,分发就行,一定要追求的是高性能。尽量简洁,快速
- 大部分情况下 http大部分都是短链接,在实际的交互过程中,一个请求到响应都很有可能会中断,中断以后就不会执行持久化,就会造成请求的丢失。这样就不利于消息中间件的业务场景,因为消息中间件可能是一个长期的获取信息的过程,出现问题和故障要对数据或消息执行持久化等,目的是为了保证消息和数据的高可靠和稳健的运行
②. 消息中间件的使用场景
-
①. 异步处理:
如果某系统直接发给另外一个系统,那叫同步(dubbo);同步就是一个系统调用另一个系统,另外一个系统必须在线,调用完后你就要接收返回结果,如果说并发量很大,这种方式有问题。如果你的逻辑代码很复杂,耗时长,我们就要考虑这种异步处理了

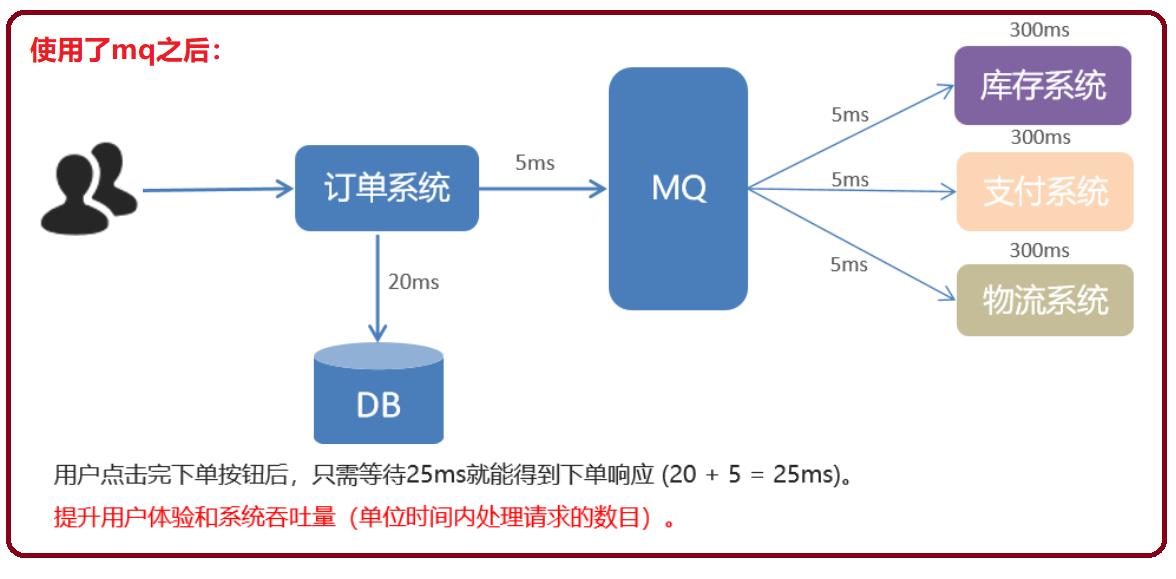
-
②. 应用解耦
dubbo之间通过一个接口工程来进行两个工程的调用,从某中意义上来说是耦合的,它共同使用了这个接口。如果你一个系统调用另一个系统,不想它耦合,可以使用消息中间件
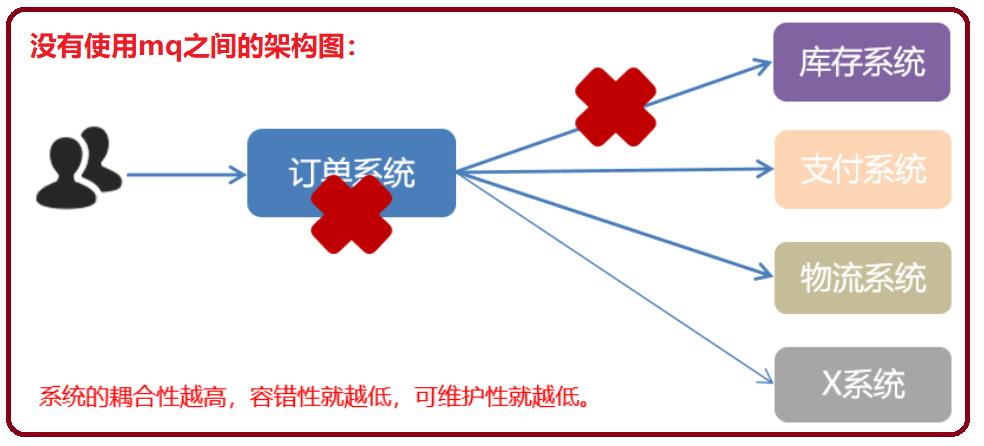

- ③. 流量削锋
- 我们去调用发短信的功能是很耗时的,在高并发的情况下,容易造成高并发的问题。这个时候我们利用消息中间件,将信息发送消息中间件,然后拿另外一个线程去接收消息,然后发消息。就进行了流量的一个削锋
- 如订单系统,在下单的时候就会往数据库写数据。但是数据库只能支撑每秒1000左右的并发写入,并发量再高就容易宕机。低峰期的时候并发也就100多个,但是在高峰期时候,并发量会突然激增到5000以上,这个时候数据库肯定卡死了
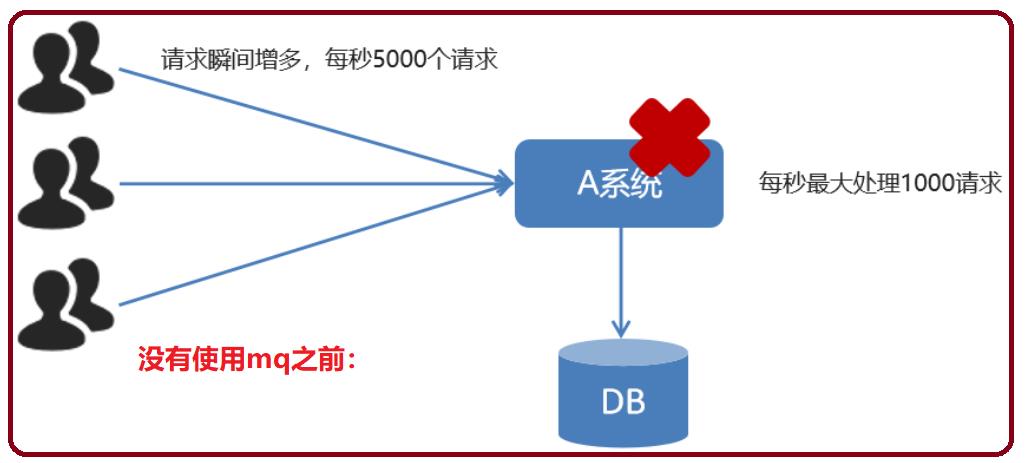
- 消息被MQ保存起来了,然后系统就可以按照自己的消费能力来消费,比如每秒1000个数据,这样慢慢写入数据库,这样就不会卡死数据库了

- 但是使用了MQ之后,限制消费消息的速度为1000,但是这样一来,高峰期产生的数据势必会被积压在MQ中,高峰就被“削”掉了。但是因为消息积压,在高峰期过后的一段时间内,消费消息的速度还是会维持在1000QPS,直到消费完积压的消息,这就叫做“填谷”

- ④. 消息通讯
两个系统之间想传递消息,用消息中间件比较方便

③. 使用MQ的劣势、使用场景
-
①. 系统可用性降低:系统引入的外部依赖越多,系统稳定性越差。一旦MQ宕机,就会对业务造成影响。如何保证MQ的高可用?
-
②. 系统复杂度提高:MQ的加入大大增加了系统的复杂度,以前系统间是同步的远程调用,现在是通过MQ进行异步调用。如何保证消息没有被重复消费?怎么处理消息丢失情况?那么保证消息传递的顺序性
-
③.一致性问题:A系统处理完业务,通过MQ给B、C、D三个系统发消息数据。如果B系统、C系统处理成功,D系统处理失败。如何保证消息数据处理的一致性
-
④. 什么情况下会使用RabbitMQ?
- 生产者不需要从消费者处获取得反馈
- 容许短暂的不一致性
- Mq的优势>mq的缺点
④. RabbitMQ架构图与主要概念
-
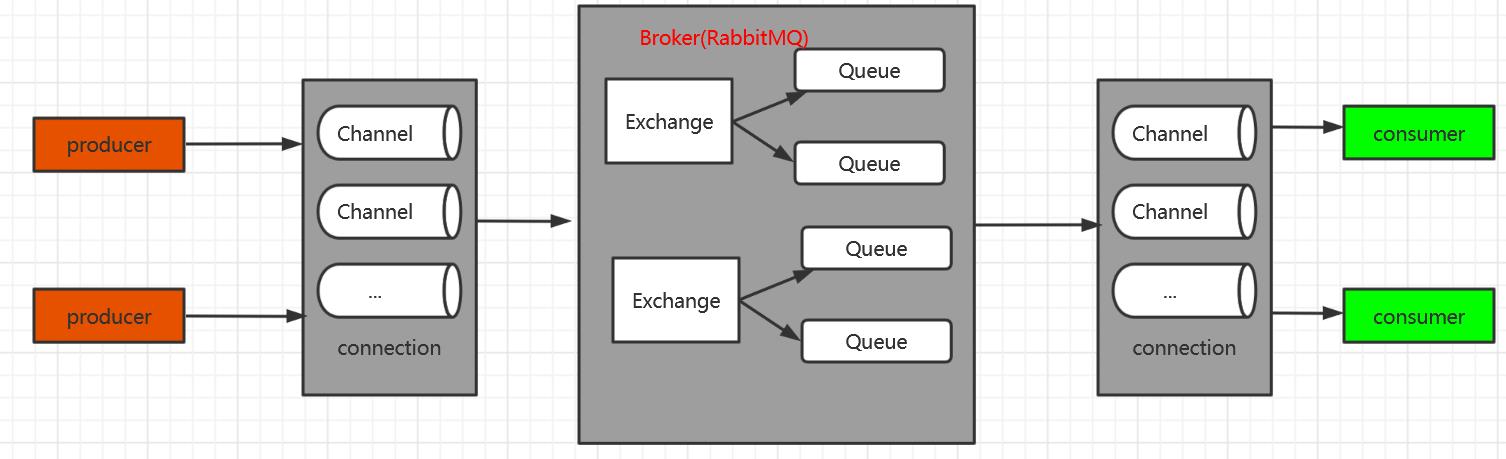
①. RabbitMQ Server:也叫broker server,它是一种传输服务。他的角色就是维护一条从Producer到Consumer的路线,保证数据能够按照指定的方式进行传输
-
②. Producer:消息生产者,如图A、B、C,数据的发送方。消息生产者连接RabbitMQ服务器然后将消息投递到Exchange
-
③. Consumer:消息消费者,如图1、2、3,数据的接收方。消息消费者订阅队列,RabbitMQ将Queue中的消息发送到消息消费者
-
④. Exchange:生产者将消息发送到Exchange(交换器),由Exchange将消息路由到一个或多个Queue中(或者丢弃)。Exchange并不存储消息。RabbitMQ中的Exchange有direct、fanout、topic、headers四种类型,每种类型对应不同的路由规则
-
⑤. Queue:(队列)是RabbitMQ的内部对象,用于存储消息。消息消费者就是通过订阅 队列来获取消息的,RabbitMQ中的消息都只能存储在Queue中,生产者生产消息并最终投递到Queue中,消费者可以从Queue中获取消息并消费。多个消费者可以订阅同一个 Queue,这时Queue中的消息会被平均分摊给多个消费者进行处理,而不是每个消费者 都收到所有的消息并处理
-
⑥. RoutingKey:生产者在将消息发送给Exchange的时候,一般会指定一个routing key, 来指定这个消息的路由规则,而这个routing key需要与Exchange Type及binding key联合使用才能最终生效。在Exchange Type与binding key固定的情况下(在正常使用时一 般这些内容都是固定配置好的),我们的生产者就可以在发送消息给Exchange时,通过指定routing key来决定消息流向哪里。RabbitMQ为routing key设定的长度限制为255 bytes
- Connection(连接):Producer和Consumer都是通过TCP连接到RabbitMQ Server的。以后我们可以看到,程序的起始处就是建立这个TCP连接
- Channels(信道):它建立在上述的TCP连接中。数据流动都是在Channel中进行的。也就是说,一般情况是程序起始建立TCP连接,第二步就是建立这个Channel
- VirtualHost:权限控制的基本单位,一个VirtualHost里面有若干Exchange和MessageQueue,以及指定被哪些user使用

⑤. Docker快速安装Rabbitmq
- ①. 获取镜像
#指定版本,该版本包含了web控制页面
docker pull rabbitmq:management
- ②. 运行镜像
#方式一:默认guest 用户,密码也是 guest
docker run -d --hostname my-rabbit --name rabbit -p 15672:15672 -p 5672:5672 rabbitmq:management
#方式二:设置用户名和密码
docker run -d --hostname my-rabbit --name rabbit -e RABBITMQ_DEFAULT_USER=user -e RABBITMQ_DEFAULT_PASS=password -p 15672:15672 -p 5672:5672 rabbitmq:management
- ③. 访问ui页面
http://服务器ip:15672/

⑥. 用户以及Virtual Hosts配置
- ①. 用户角色:RabbitMQ在安装好后,可以访问http://服务器ip:15672,其自带了guest/guest的用户名和密码;如果需要创建自定义用户;那么也可以登录管理界面后,如下操作:
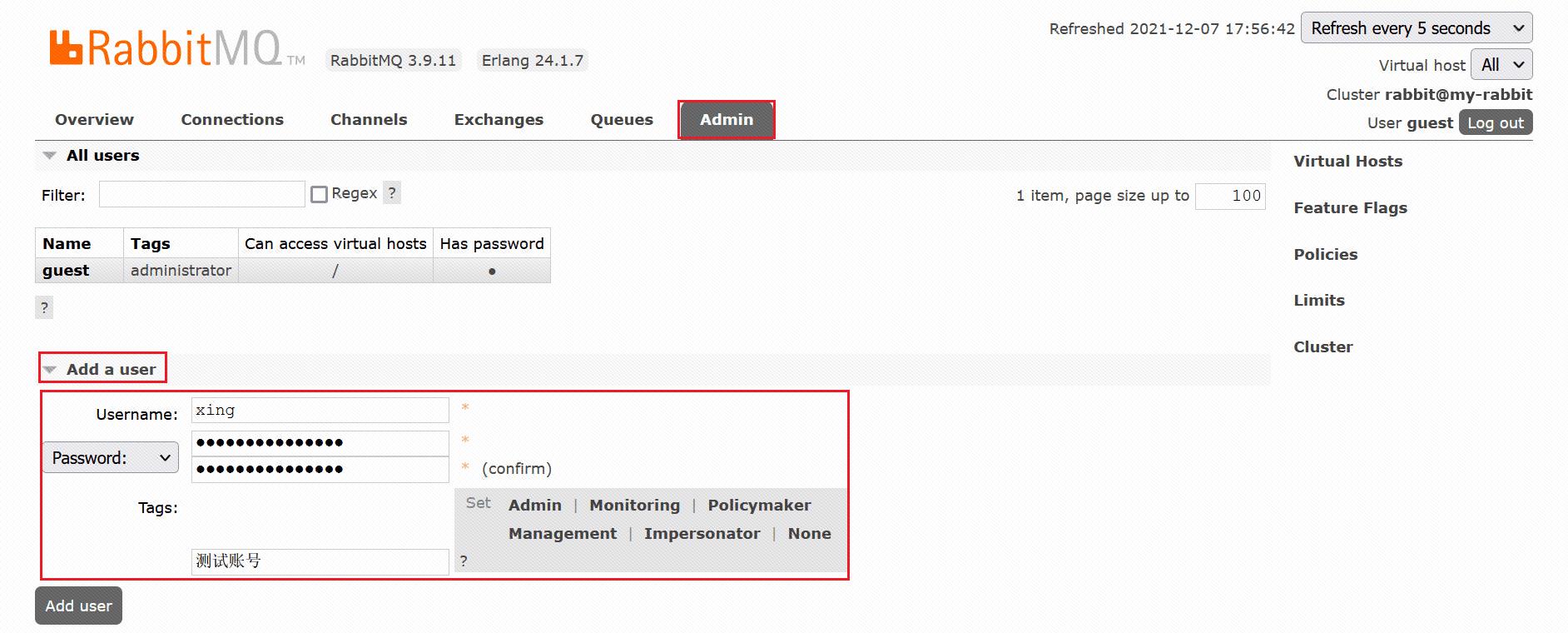
角色说明:
1、 超级管理员(administrator)
可登陆管理控制台,可查看所有的信息,并且可以对用户,策略(policy)进行操作。
2、 监控者(monitoring)
可登陆管理控制台,同时可以查看rabbitmq节点的相关信息(进程数,内存使用情况,磁盘使用情况
等)
3、 策略制定者(policymaker)
可登陆管理控制台, 同时可以对policy进行管理。但无法查看节点的相关信息(上图红框标识的部分)
4、 普通管理者(management)
仅可登陆管理控制台,无法看到节点信息,也无法对策略进行管理。
5、 其他
无法登陆管理控制台,通常就是普通的生产者和消费者。
- ②. Virtual Hosts配置像mysql拥有数据库的概念并且可以指定用户对库和表等操作的权限。RabbitMQ也有类似的权限管理;在RabbitMQ中可以虚拟消息服务器Virtual Host,每个Virtual Hosts相当于一个相对独立的RabbitMQ服务器,每个VirtualHost之间是相互隔离的。 exchan ge、queue、message不能互通。 相当于mysql的db。Virtual Name一般以/开头
步骤:
1.创建Virtual Hosts
2.设置Virtual Hosts权限
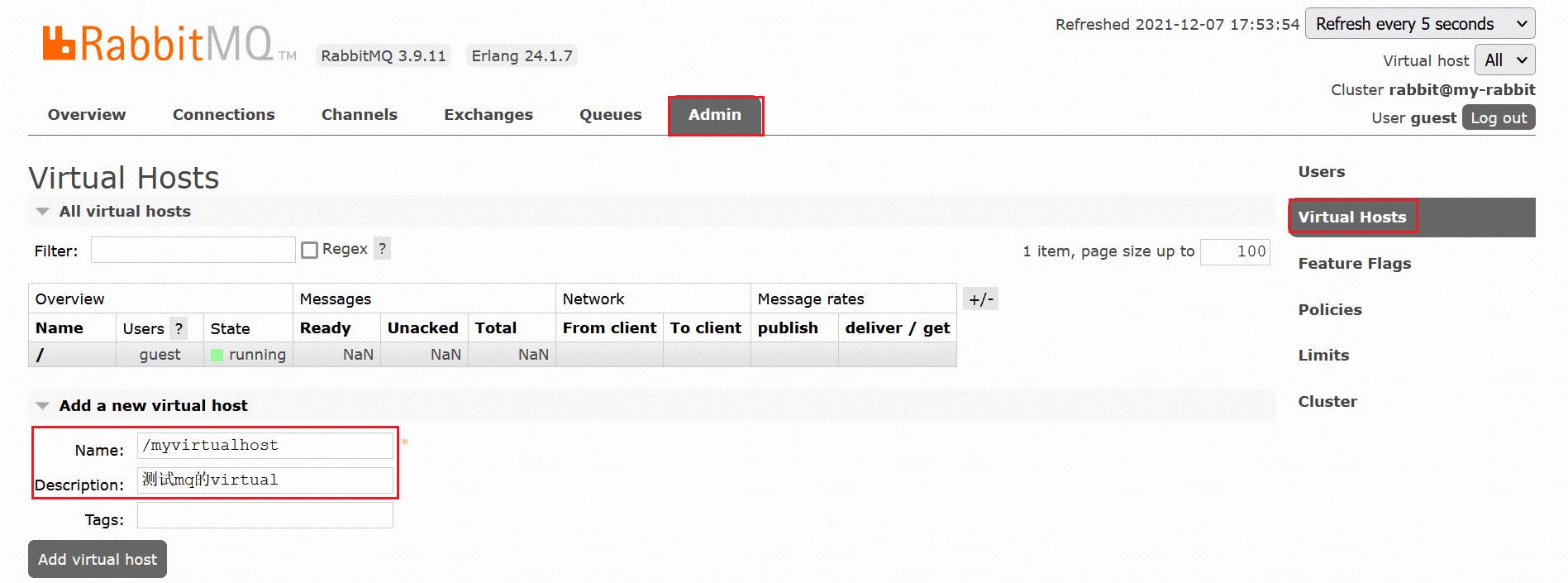


⑦. RabbitMQ的角色分类
-
①. none:不能访问managerment plugin
-
②. managerment:查看自己相关节点信息
- 列出自己可以通过AMQP登入的虚拟机
- 查看自己的虚拟节点Virtual hosts的queues,exchanges和bindings信息
- 查看和关闭自己的channels和connections
- 查看有关自己的虚拟机节点virtual hosts的统计信息。包括其他用户在这个节点virtual hosts中的活动信息
- ③. Policymaker
- 包含managerment所有权限
- 查看和创建和删除自己的virtual hosts所属的policies和parameters信息
- ④. Monitoring
- 包含management所有权限
- 罗列出所有的virtual hosts,包括不能登录的virtual hosts
- 查看其他用户的connection和channels信息
- 查看节点级别的数据和clustering和memory使用情况
- 查看所有的virtual hosts的全局统计信息
- ⑤. Administrator
- 最高权限
- 可以创建和删除virtual hosts
- 可以查看,创建和删除users
- 查看创建permissions
- 关闭所有用户的connections
以上是关于RabbitMQ01_消息队列概述使用场景劣势架构图与主要概念Docker快速安装Rabbitmq角色分类的主要内容,如果未能解决你的问题,请参考以下文章
高并发架构系列:KafkaRocketMQRabbitMQ的优劣势比较