每日一书丨机器学习解决实际问题的流程
Posted 《新程序员》编辑部
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了每日一书丨机器学习解决实际问题的流程相关的知识,希望对你有一定的参考价值。
采用机器学习方法解决实际问题通常需要包含多个步骤,具体如下图所示。
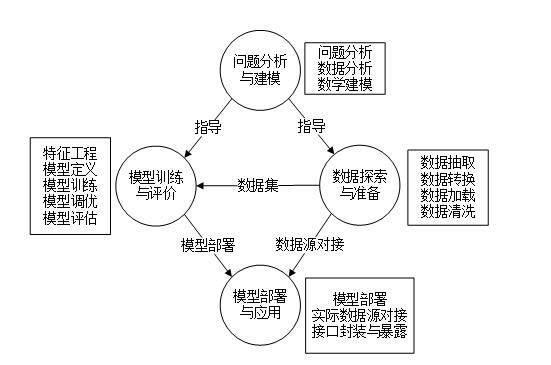
从图中可以看出,采用机器学习方法解决实际问题时主要分为问题分析与建模、模型训练与评价、数据探索与准备、模型部署与应用4个阶段。
问题分析与建模是首先要进行的工作,其主要内容是对原始问题进行领域分析与理解,然后对数据进行初步分析与探索,最后采用数学建模的方法得到该问题的形式化定义,为后续的模型训练与评价和数据探索与准备工作提供精确指导。
数据探索与准备阶段主要包括数据抽取、数据转换、数据加载和数据清洗等4个部分,其中,数据抽取主要实现异构数据源的灵活接入与数据采集;数据转换主要根据数学模型的要求对数据进行必要的转换和处理;数据准备在前面工作的基础上将原始数据保存至统一的数据库或文件系统中;数据清洗主要对原始数据进行异常值剔除与修正等工作,保证数据的正确性和有效性,并为后续的模型训练和评估提供数据集支撑。
模型训练与评价阶段主要分为特征工程、模型定义、模型训练、模型调优和模型评估等5部分工作,其中特征工程部分的主要工作是最大程度地从原始数据中提取特征以供算法和模型使用;模型定义部分的工作是针对问题的特点和数学定义,选择、定制合适的机器学习模型,并给出优化目标;模型训练部分在模型定义的基础上,通过对训练数据集进行分析,并获得经过训练优化的模型;为了提高模型的性能和效果,需要对模型进行调优,主要涉及超参数优化、神经网络搜索等自动化机器学习技术;模型评估是根据优化目标对模型的质量进行评估。
模型部署与应用阶段主要分为模型部署、模型服务实例管理和资源管理等工作。模型部署工作主要将已经开发完成的机器学习模型打包为具有标准接口的服务,并部署在轻量级容器环境中;模型服务实例管理部分支持将每个服务部署多个服务实例,以提升服务可支持的并发请求,并自动将不同实例分布到不同机器上以更好地保障服务高可用性;资源管理工作主要包括弹性扩缩、蓝绿部署(Blue Green Deployment)等能力,支撑用户以最低的资源成本获取高并发、稳定的在线算法模型服务。
基于上述生命周期的定义,下图对每个阶段要完成的工作进行了较为详细的流程化描述。
在问题分析与建模阶段主要包含问题分析、数据分析和数学建模等3项工作。

问题分析过程分为两步:首先是需要明确和理解问题,包括准确地描述问题、明确问题的构成要素、探究问题的本质、显性化问题隐含的假设等四个方面;其次是拆分和定位问题,其核心是将复杂的问题拆解为一个个元问题(最细小的、不可分解的待解决问题)。
数据探索与准备阶段主要包含数据抽取、数据转换、数据加载和数据清洗等4项工作。其中,数据抽取、转化和加载部分主要对ETL(extract-transform-load)技术进行介绍,包括ETL概念、ETL工作方式、ETL实现模式,ETL发展历史和主流ETL工具等内容。数据清洗部分主要包括针对数据集中的空值和乱码数据异常问题等进行处理,对数据进行拆分和采样等步骤。
模型训练与评价阶段主要包含特征工程、模型定义、模型训练、模型调优和模型评价等5项工作。其中,特征工程的目的是最大限度地从原始数据中提取特征以供算法和模型使用,主要包含数据预处理、特征选择和数据降维等三个部分的内容。模型选择过程需要考虑问题的特性、数据规模大小和分布特征、消耗资源等因素;模型训练过程中需要考虑如何划分训练集和测试集,常见的方法包括交叉验证法、自助法等;模型调优过程主要采用超参数调优、元学习和神经网络架构搜索等方法与技术;针对不同的模型,其评价指标包括精确率与召回率、ROC和AUC、混淆矩阵、MSE、MAE等多种指标。
模型部署与应用阶段主要关注如何将模型部署为智能应用模块,对接实际的数据源,进行接口封装,形成标准访问接口,最终为用户提供智能服务,主要包括模型数据格式、模型部署、模型标准访问接口和模型更新等内容。
——本文内容节选自《实战机器学习》,本书2021年10月清华社出版。

感谢清华大学出版社供稿
以上是关于每日一书丨机器学习解决实际问题的流程的主要内容,如果未能解决你的问题,请参考以下文章