IDC网络传输优化的罪与罚
Posted dog250
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了IDC网络传输优化的罪与罚相关的知识,希望对你有一定的参考价值。
IDC网络中,deep buffer是原罪,延时是惩罚。
IDC网路拥塞控制,南辕北辙了。
拥塞的本质是对共享资源的争抢,这件事放到网路上,低效的做法却正常了。
操作系统实现中,针对共享资源互斥,自然而然的做法是细粒度拆分临界区,比如Linux内核per-CPU变量越来越多,诡异的是,在网络中遇到同样的问题,做法却相反。
普遍的共识是尽可能避免访问共享资源。比如,当线程进临界区失败,如还有别的路,便不会死等:
// 版本1
if (!spin_trylock(&my_lock))
do_something_1();
else
do_something_2();
spin_unlock(&my_lock);
除此之外就是饱受诟病的死等了:
// 版本2
spin_lock(&my_lock);
do_something_2();
spin_unlock(&my_lock);
还有更拉胯的做法:
// 版本3
retry:
if (!spin_trylock(&my_lock))
sleep(&tiny_slice);
goto retry;
do_something_2();
spin_unlock(&my_lock);
看看网络如何处理共享资源争抢的:
- 版本1:从来没有用过,但当一个交换机端口拥塞时,别的端口是可以绕路的。
- 版本2:最常规做法,遇到交换机端口拥塞,就排队等待,直到轮到自己。
- 版本3:随机访问常规,如CSMA/CD,CSMA/CA以及更古老的ALOHAnet。
低效的自旋以及更低效的retry显然在网络中绝对正确,这和在操作系统的做法截然相反。为什么不能绕路,回答一般是:
- 绕路不保证最短路径。
- 绕路可能导致环路。
- TCP数据流会乱序。
有道理,但循环论证了,典型的用原因A的结果B去推导原因A本身。
看下面的做法:
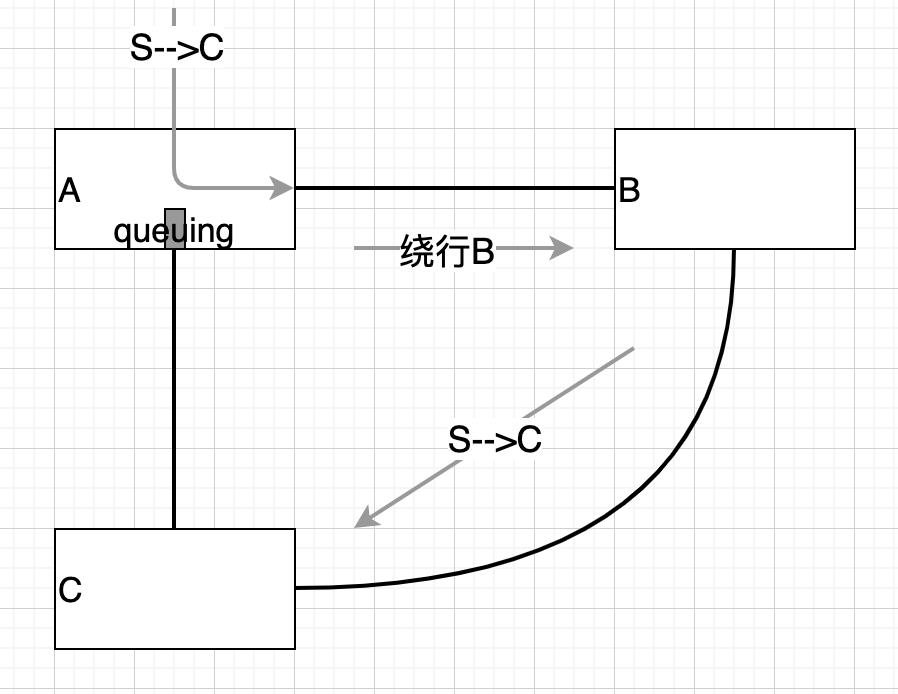
交换机A与C之间拥塞时,经由B到C无疑可行。
上面的做法看起来违反常规,其实这才是常规。如果开车想经A到C,发现A到C之间拥堵了,你会在A死等吗?有一条路到B,而且你确信经B可以到C,你肯定会绕行B,是吗?
但话还没有说完,关键还要看AB,BC的开销是否比排队开销更大,若是,就没必要绕行了,反之,绕行就有收益。
人们花大量的精力去研究buffer大小和IDC网络各指标之间的关系,却从没想过绕开它。既然问题的根源是buffer,拿掉它就是了。
还是思维定势。将广域网的那套搬到IDC网络,显然就有问题了。
广域网距离远,传播延时占比大,排队延时占比小,绕行的开销显然过大,于是最短路径就成了广域网路由的首要追求。
但IDC网络传播延时在100us级,排队延时依然在1ms~10ms级,若避开排队,收益将巨大,IDC网络显然可为避排队放弃最短路径。
来看环路问题。
IDC网络是相对规则的比如CLOS胖树,将同级交换机横向连接,为每个交换机以其在该层的位置进行编号,当数据包到达时,实施以下算法,保证数据包始终逐层向下就能避免环路:
if 下出口拥塞
if 当前交换机偏左
发往右边交换机
else
发往左边交换机
fi
else
从下出口发出
fi
收益是大大减少了交换机的buffer配置:
- 从两边到中间,交换机buffer逐渐减小,中间交换机可以配置极小buffer。
显然,只有最边上的交换机才可能导致不得已排队,因为不能继续转发了,但有同层至少一半交换机可供尝试,下端口同时拥塞的概率非常低。
至于TCP乱序问题,这个问题不值得讨论,将保序放在传输层本来就不合理,为了保序,带宽便无法池化,甚至在广域网上,一半以上的传输性能问题均和保序有关。
…
网络是数据包尽快离开的地方。所有将数据包驻留在网络的措施都不是拥塞控制的目标。buffer的作用是缓解统计突发,用buffer解决拥塞的思路是错误的,拥塞应该疏导才对。
buffer是必要的,互联网是分组交换网,其两个特征都依赖buffer:
- 统计复用,需要buffer缓存统计突发。
- 存储转发,需要buffer平滑转发(比如查表)损耗。
对于广域网和IDC网络两者,buffer的作用向两个极端延展:
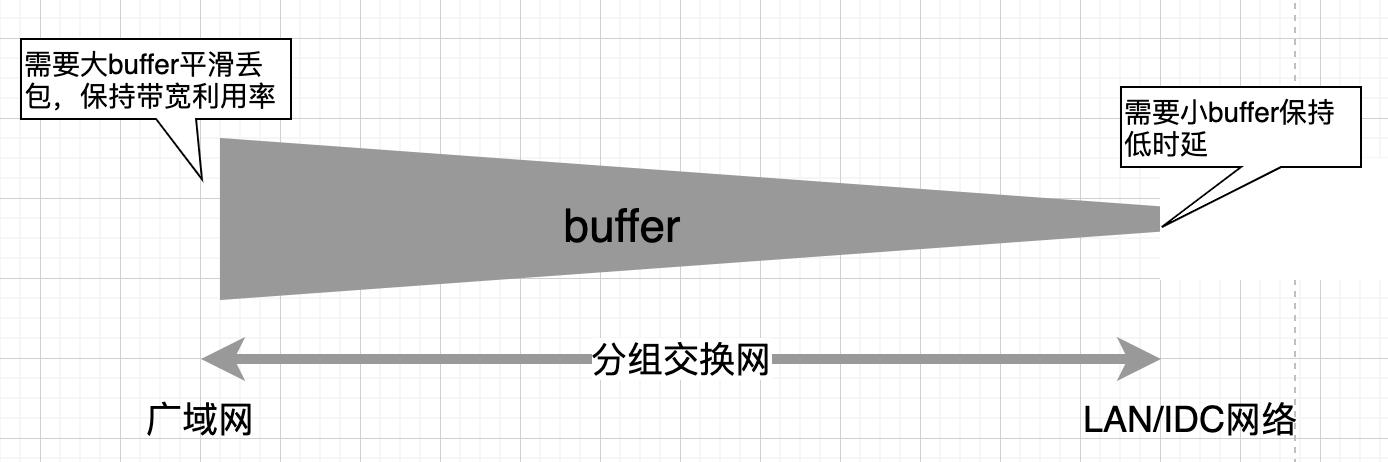
bufferbloat往往出现在长肥链路的端点处,由于链路长,危害并不算大,如果deep buffer确实始终诱导数据流用尽它们,bufferbloat导致的IDC网络10ms级的延时将是灾难性的,因此在IDC网络事实上应该避免部署deep buffer。
在IDC网络,要部署shallow buffer。但你又需要buffer来缓解大burst带来的丢包所以必须部署deep buffer不是吗?如何是好?所以说,既然burst非常态,当它发生时,绕路不就可以了嘛,方法就是上面说的。
我描述一下CSMA/CD共享式以太网到交换式以太网的进化,看看到底发生了什么。
当CSMA/CD网络进化到交换式网络后,buffer仍然是一个冲突域,二者本质上一致,所不同的是,交换机将CSMA/CD网络分散的buffer集中在一起,以空间换时间。
CSMA/CD网络站点越多,冲突越频繁,整体效能就越低,对应到交换机,deep buffer意味着可以承载更多的冲突,但更多的冲突也意味着成功发送一个数据包的平均时延会更高。
背后的铁律是守恒律,这也是BBR背后的依据。当bottleneck带宽一定,网络半径一定,该网络统计容量就一定,与接入的站点数无关,如果增加buffer,延时必增加,数据包只是从主机网卡转移到了buffer。
数据包发送成功可能是buffer给的假象,被对端接收才真实。有意思的是,CSMA/CD网络中,冲突意味着发送失败被承认,但在交换式网络却假设即便排在buffer中也算发送成功,显然是掩耳盗铃。
浙江温州皮鞋湿,下雨进水不会胖。
以上是关于IDC网络传输优化的罪与罚的主要内容,如果未能解决你的问题,请参考以下文章