ffmpeg 源码分析与命令实战和代码实战
Posted 高级iOS开发工程师-蔡令
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ffmpeg 源码分析与命令实战和代码实战相关的知识,希望对你有一定的参考价值。
FFmpeg 源码分析
- 前言
FFMPEG 是一款特别强大专门用于处理音视频的开源库。你即可以使用它的API对音视频进行处理,也可以使用它提供的工具,如ffmpeg,ffplay,ffprobe,来编剧你的音视频文件。以及在直播中推流/拉流的相关处理,其播放器相关开发。
本文件将简要介绍一下FFMPEG库的基本目录结构及其功能,然后详细介绍一下我们在日常工作中,如何使用ffmpeg提供的工具处理音视频文件
最后我们将以一个Xcode 环境下利用FFMPEG 实现播放器,播放我们的视频文件。
- Mac/Linux 编译 ffmpeg
ffmpeg 源码下载地址:http://ffmpeg.org/download.html
利用Mac 的终端命令执行 git clone https://git.ffmpeg.org/ffmpeg.git ffmpeg 把ffmpeg的源码克隆到你的电脑本地如下图:
在你已经克隆到源码的电脑路径上目录下执行:进行编译ffmpeg 依次执行操作:
./configure --prefix=/usr/local/ffmpeg --enable-gpl --enable-nonfree --enable-libfdk-aac --enable-libx264 --enable-libx265 --enable-filter=delogo --enable-debug --disable-optimizations --enable-libspeex --enable-videotoolbox --enable-shared --enable-pthreads --enable-version3 --enable-hardcoded-tables --cc=clang --host-cflags= --host-ldflags=
make - j 4 或者 sudo make -j 4
make install 或者 sudo make install
执行完毕之后如下图:
可以进入cd /usr/local/ffmpeg/bin 查看FFmpeg 编译成功的相关信息

这个时候我们在执行ffmpeg 命令如下:
这样代表我们ffmpeg 编译成功
- FFMPEG/FFPLAY/FFPROBE的区别
- ffmpeg:Hyper fast Audio and Video encoder 超快音视频编码器(类似爱剪辑、小影、乐秀、抖音)等等产品
- ffplay:Simple media player 简单媒体播放器
- ffprobe:Simple multimedia streams analyzer 简单多媒体流分析器
- FFMPEG 目录及作用
目录结构如下图:
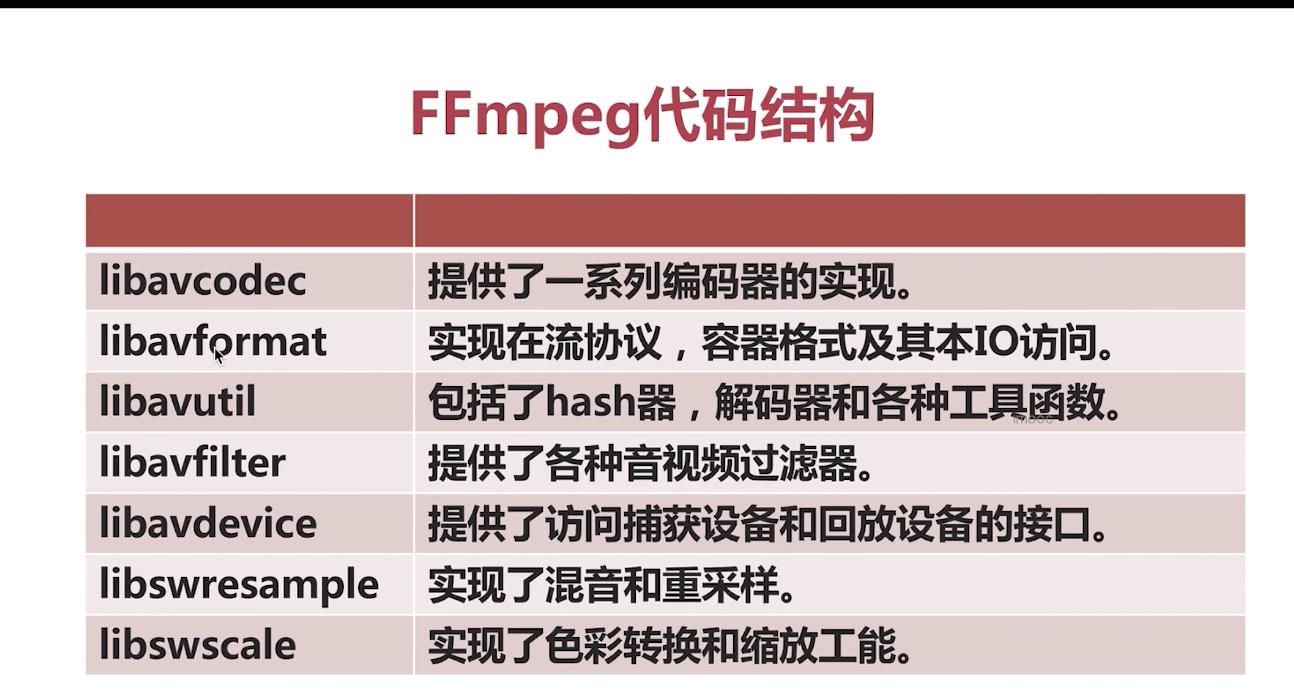
- FFMPEG 基本概念
在讲解FFMPEG 基本概念之前,我们先介绍一些音视频基本的基本概念
1.音/视频流:
在音视频领域,我们把一路音/视频称为一路流,如我们小时候经常使用VCD 看电影,在里边可以选择粤语或者国语声音,其实就是CD 视频文件中存放了两路音频流,和一路视频流,用户可以选择其中一路进行播放。
我们先看一下音频基础知识:
1.1 《声音的物理性质—振动》:
声音是一种由物体振动引发的物理现象,如小提琴的弦声等。物体的振动使其四周空气的压强产生变化,这种忽强弱变化以波的形式向四周传播,当然人耳所接收时,我们就听见了声音:如下图:

1.2 《声音的物理性质-波形》:
声音是由物体的振动产生的,这种振动引起了周围空气压强的振动,我们称这种振动的函数表现形式为波形:如下图

1.3《声音的物理性质》-频率:
声音的频率是周期的倒数,他表示的声音在1秒钟内的周期数,单位是赫兹(Hz)。千赫(KHz),即1000Hz ,表示每秒振动1000次。声音安频率可作如下划分:如图:

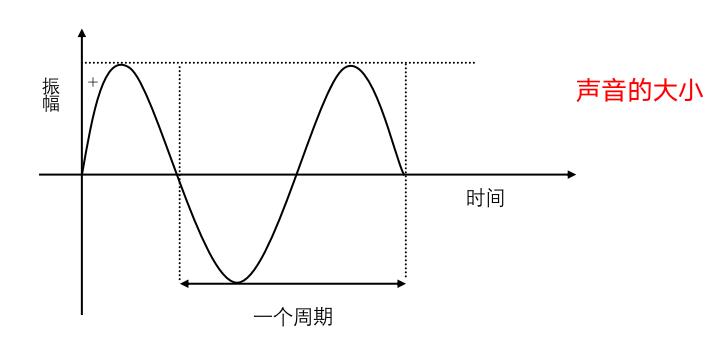
1.4 《声音的物理性质》-振幅:
声音有振幅,振幅的主观感觉是声音的大小。声音的振幅大小取决于空气压力波距平均值(也称平衡态)的最大偏移量。如图:
1.5 数字音频:
为了将模拟信号数字化,数字音频将分为3个概念进行讲解(采样频率、采样量化、编码)。
计算机并不直接使用连续平滑的波形来表示声音,它是每隔固定的时间对波行的幅值进行采样,用得到的一系列数字量来表示声音。如下图:

PCM 脉冲编码调制:PCM(Pulse Code Modulation),脉冲编码调制。人耳听到的是模拟信号,PCM是把声音从模拟信号转化为数字信号的技术。
1.6 数字音频-采样频率:
根据Nyguist 采样定律,要从采样中完全恢复原始信号波形,采样频率必须至少是信号中最高频率的两倍。
前面提到人耳能听到的频率范围是 [20Hz–20KHz],所以采样频率一般为44.1Khz,这样就能保证声音到达20KHz也能被数字化,从而使得经过数字化处理之后,人耳听到的声音质量不会被降低。采样频率如下图:

1.7 数字音频-采样量化:
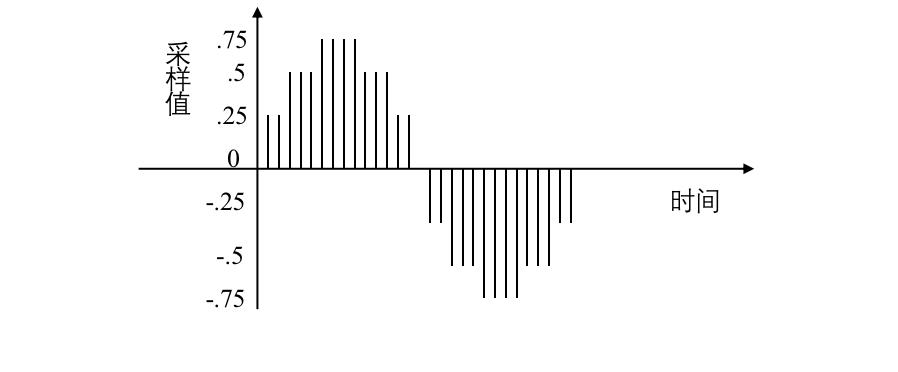
采样是在离散的时间点上进行的,而采样值本身在计算机中也是离散的。
采样值的精度取决于它用多少位来表示,这就是量化。
例如:8位量化可以表示256个不同值,而CD质量的16位量化可以表示65536个值,范围为[-32768,32767]。
下图是一个3位量化的示意图,可以看出3位量化只能表示8个值:0.75,0.5,0.25,0,-0.25,-0.5,-0.75 和-1,因而量化位数越少,波形就越难辨认,还原后的声音质量也就越差(可能除了一片轰轰声之外,什么都没有)
如下图:
1.8 音频常见名词-1:
采样频率:每秒钟采样的点的个数。常用的采样频率有:如下图所示

采样精度(采样深度):每个“样本点”的大小,常用的大小为8bit ,16bit,24bit。
通道数:单声道、双声道、四声道、5.1声道。
1.9 音频常见的名词-2:
比特率:每秒传输的bit 数,单位为:bps (Bit Per Second)
间接衡量声音质量的一个标准。
没有压缩的音频数据的比特率=采样频率 x 采样精度 x 通道数。
码率:压缩后的音频数据的比特率。常见的码率:
96kbps: FM质量。
128-160kbps: 一般质量音频。
192kbps: CD 质量。
256-320kbps: 高质量音频。
码率越大,压缩效率越低,质量越好,压缩后数据越大。
码率 = 音视文件大小/时长。
2.0 音频常见名词-举例:
比如:采样频率44100,采样精度16bit, 2通道(声道),采集4分钟的数据。
44100 x 16 x 2 x 4 x 60 = 338688000 bit
338688000/8/1024/1024 = 40M 字节
比特率:采样频率 x 采样进度 x 通道数 = 44100 x 16 x 2 = 1411200bit/s
如图所示:图 1-5
2.1 音频常见名词-3
帧: 每次编码的采样单元数,比如mp3 通常是1152 个采样点作为一个编码单元,AAC 通常是1024 个采样点作为一个编码单元。
帧长 :
(1).可以指每帧播放持续的时间:每帧持续时间(秒) = 每帧采样点数/采样频率(Hz)
比如:MP3 48K, 1152个采样点,每帧则为24毫秒
1152/48000 = 0.24 秒 = 24 毫秒;
(2) 也可以指压缩后每帧的数据长度。
(3) 所以讲到帧的时候要注意他适用的场合
2.2 音频常见名词- 4

**交错模式:**数字音频信号存储的方式。数据以连续帧的方式存放,即首先记录帧1的左声道样本和右声道样本,再开始帧2的记录…

**非交错模式:**首先记录的是一个周期内所有帧的左声道样本,再记录所有右声道样本

2.3 音频编码原理简介-1:
数字音频信号如果不加压缩地直接进行传送,将会占用极大的带宽。例如:一套双声道数字音频若取样频率为44.1KHz,每样值按16bit 量化,则器码率:
2 x 44.1KHz x 16 bit = 1.411 Mbit/s
如此大的带宽将给信号的传输和处理都带来许多困难和成本(阿里云服务器带宽大于5M后,每M价格是100元/月),
因此必须采取音频压缩技术对音频数据进行处理,才能有效地传输音频数据。
数字音频压缩编码在保证信号在听觉方面不产生失真的前提下,对音频数据信号进行尽可能大的压缩,降低数据量。数字音频压缩编码采取去除声音信号中冗余成分的方法来实现。所谓冗余成分指的是音频中不能被人耳感知到的信号,它们对确定声音的音色,音调等信息没有任何的帮助。
2.4 音频编码原理简介-2:
冗余信号包含人耳听觉范围外的音频信号以及被掩蔽掉的音频信号等。例如,人耳所能察觉的声音信号的频率范围为20Hz~20KHz,除此之外的其它频率人耳无法察觉,都可视为冗余信号。
此外,根据人耳听觉的生理和心理声学现象,当一个强音信号与一个弱音信号同时存在时,弱音信号将被强音信号所掩蔽而听不见,这样弱音信号就可以视为冗余信号而不用传送。这就是人耳听觉的掩蔽效应,主要表现在频谱掩蔽效应和时域掩蔽效应。
2.5 音频编码-频谱掩蔽效应:
一个频率的声音能量小于某个阈值之后,人耳就会听不到。当有另外能量较大的声音出现的时候,该声音频率附近的阈值会提高很多,即所谓的掩蔽效应。如下图所示:
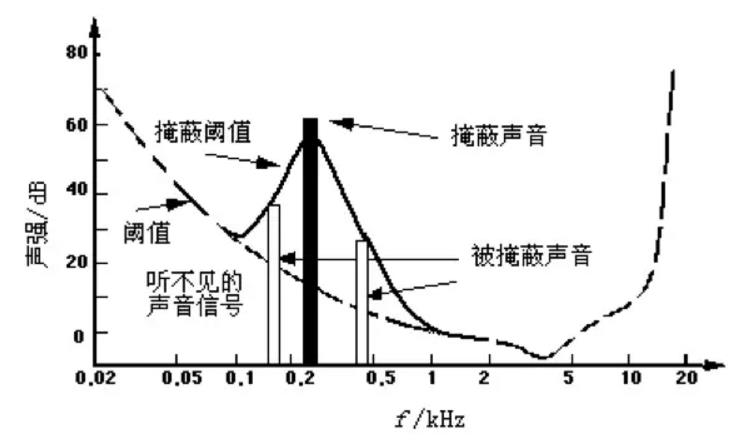
由图中我们可以看出人耳对2KHz~5KHz的声音最敏感,而对频率太低或太高的声音信号都很迟钝,当有一个频率为0.2KHz、强度为60dB的声音出现时,其附近的阈值提高了很多。由图中我们可以看出在0.1KHz以下、1KHz以上的部分,由于离0.2KHz强信号较远,不受0.2KHz强信号影响,阈值不受影响;而在0.1KHz~1KHz范围,由于0.2KHz强音的出现,阈值有较大的提升,人耳在此范围所能感觉到的最小声音强度大幅提升。如果0.1KHz~1KHz范围内的声音信号的强度在被提升的阈值曲线之下,由于它被0.2KHz强音信号所掩蔽,那么此时我们人耳只能听到0.2KHz的强音信号而根本听不见其它弱信号,这些与0.2KHz强音信号同时存在的弱音信号就可视为冗余信号而不必传送。
2.6 音频编码-时域掩蔽效应
当强音信号和弱音信号同时出现时,还存在时域掩蔽效应。即两者发生时间很接近的时候,也会发生掩蔽效应。时域掩蔽过程曲线如图所示,分为前掩蔽、同时掩蔽和后掩蔽三部分。如下图所示:
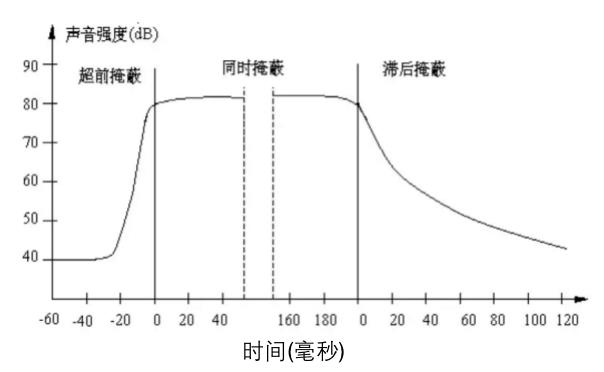
时域掩蔽效应可以分成三种:前掩蔽,同时掩蔽,后掩蔽。前掩蔽是指人耳在听到强信号之前的短暂时间内,已经存在的弱信号会被掩蔽而听不到。同时掩蔽是指当强信号与弱信号同时存在时,弱信号会被强信号所掩蔽而听不到。后掩蔽是指当强信号消失后,需经过较长的一段时间才能重新听见弱信号,称为后掩蔽。这些被掩蔽的弱信号即可视为冗余信号。
2.7 音频编码-压缩编码方法:
当前数字音频编码领域存在着不同的编码方案和实现方式, 但基本的编码思路大同小异, 如下图所示:
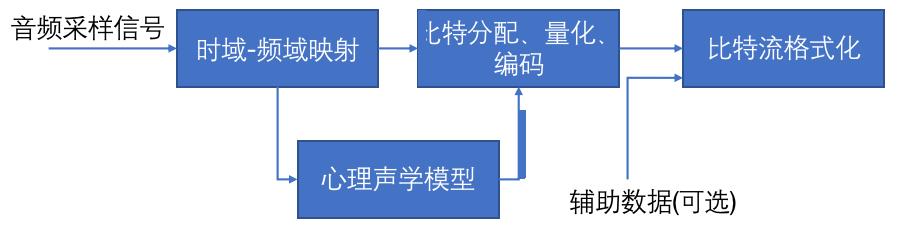
对每一个音频声道中的音频采样信号:
(1).将它们映射到频域中,这种时域到频域的映射可通过子带滤波器实现。每个声道中的音频采样块首先要根据心理声学模型来计算掩蔽门限值;
(2).由计算出的掩蔽门限值决定从公共比特池中分配给该声道的不同频率域中多少比特数,接着进行量化以及编码工作;
(3).将控制参数及辅助数据加入数据之中,产生编码后的数据流。
2.8 音频编解码器选型:
OPUS
MP3
AAC
AC3和EAC3 杜比公司的方案
- FFMPEG 命令
- FFMPEG 基本的信息查询命令
- FFMPEG 处理音视频相关流程
- FFMPEG 录制
- FFMPEG 分解/复用
- FFMPEG 处理原始数据
- FFMPEG 切割与合并
- FFMPEG 图片/视频互相转换
- FFMPEG 直播相关
- 蔡老师视频教学:(音视频基础、WebRTC、FFmpeg )源码分析
-播放地址如下-西瓜视频:
https://studio.ixigua.com/content
后续相续-进行RTMP HLS SRS RTSP ios音频开发 等相关视频教学等待更新:
以上是关于ffmpeg 源码分析与命令实战和代码实战的主要内容,如果未能解决你的问题,请参考以下文章