C语言数据结构与算法--------数组和广义表全面总结
Posted 知心宝贝
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C语言数据结构与算法--------数组和广义表全面总结相关的知识,希望对你有一定的参考价值。
目录
一、数组的定义
1.基本概念
- 数组:按照一定格式排列同属性的值,为相同数据类型元素的集合。常用的有一维数组A[5]、二维数组A[5][5]、多维数组等。
- 二维数组:通常把二维数组作为多维数组的代表,可以看出m个n维的线性表组成,如:

2.抽象数据类型
ADT Array
数据对象:D=aj1j2…jn | ji =0,...,bi-1, i=1,2,..,n, n(>0)称为数组的维数,bi是数组第i维的长度, ji是数组元素的第i维下标,aj1j2…jn∈ElemSet
数据关系:R=R1, R2, ..., Rn
Ri=<aj1,...ji,...jn, aj1,...ji+1,...jn, > | 0 ≤jk ≤bk -1, 1 ≤ k ≤ n 且k≠ i, 0 ≤ ji ≤bi -2, aj1…ji…jn , aj1…ji+1…jn∈D, i=2,...,n
二、数组的顺序存储和实现
- 存储结构:数组建立后,数组的个数及维数已经确定,故一般采用顺序存储结构
- 存储位置:Loc(aij)= Loc(a[0][0])+( )*size(0≤i≤m, 0≤j≤n)
- 存储次序:
- 按行优先存储
- 按列优先存储
1.行优先存储

行优先存储:将二维数组从第一行到最后一行,按照次序放到一维线性表中,存储位置首元素地址+((i-1)*n+j-1)*1, n为列数
2.列优先存储

行优先存储:将二维数组从第一列到最后一列,按照次序放到一维线性表中,存储位置首元素地址+((j-1)*m+i-1)*1, m为行数
3.多维数组存储地址

- 以上述的一个四位数组为例,首先我们写一个一维数组A[4](大小和给定的维数相同),上面是四维
- 四维数组大小分别为3 4 5 6,A[3]=1,A[2]=6,A[1]=5*6,A[0]=4*5*6,对应相乘
- 最后因为求A1241所以结果为 A0000+1*A[0]+2*A[1]+4*A[1]+1*A[0]
三、特殊矩阵的压缩存储
1.基本概念
- 稀疏矩阵:矩阵存储的一种特殊情况,其元素为0个数远大于非0元素个数
- 压缩方式:一维线性表存储,如下图:
- 稀疏因子:


2.三角矩阵

- 元素个数:n*(n+1)/2
- 按行存储的上三角矩阵:Loc[i,j]=Loc[1,1]+j*(j-1)/2+i-1
- 按行存储的下三角矩阵:Loc[i,j]=Loc[1,1]+i*(i-1)/2+j-1
3.带状矩阵

按行存储:Loc[i,j]=Loc[1,1]+2(i-1)+(j-1)
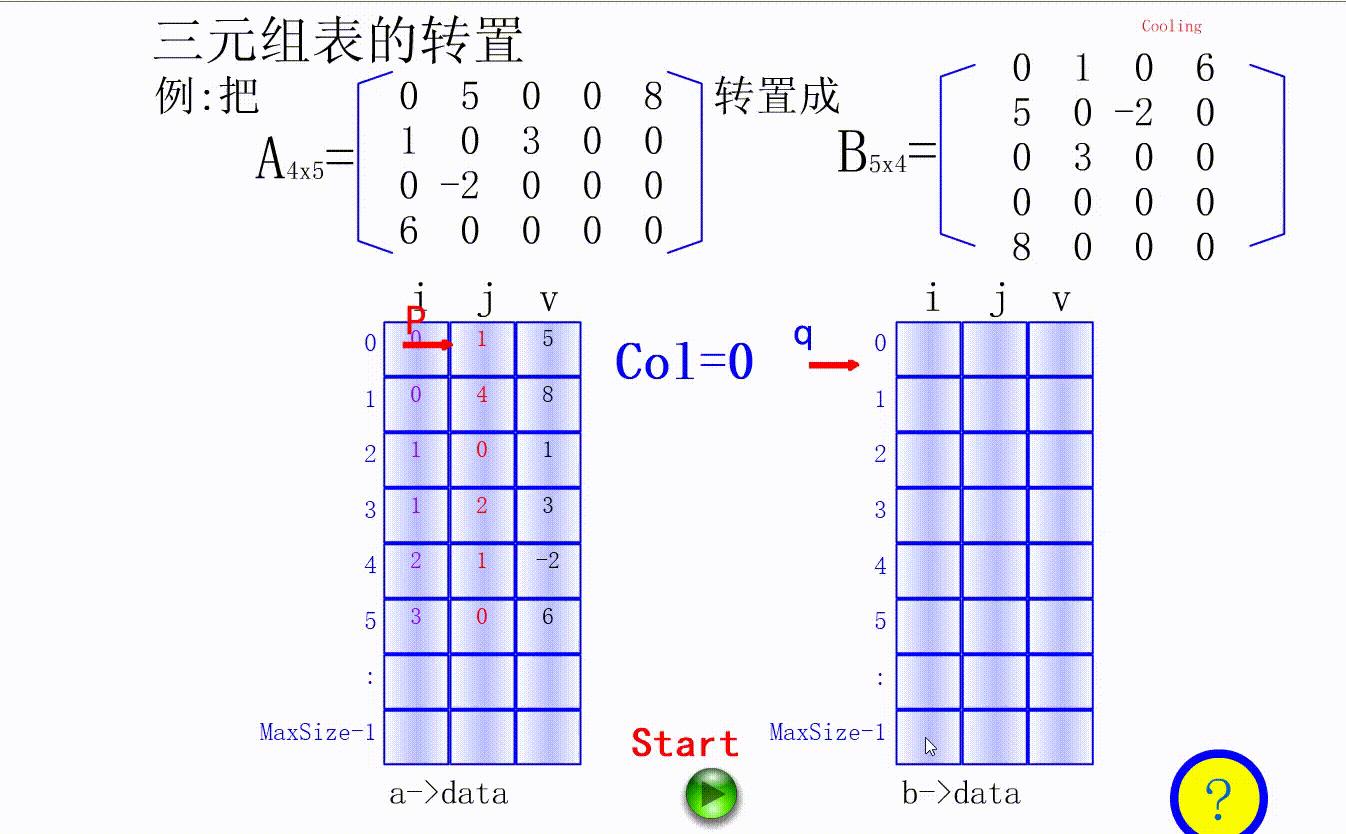
4.三元组表示法

- i j 分别表示二维数组的横纵坐标,v表示坐标对应的非0值
三元组转置动态演示:
编码实现:
void FastTransposeSMatrix(TSMatrix M, TSMatrix &T)
// 采用三元组顺序表存储表示,求稀疏矩阵M的转置矩阵 T
T.mu = M.nu;
T.nu = M.mu;
T.tu = M.tu;
if (T.tu)
for (col=1; col<=M. nu; ++col)
num[col] = 0;
for (t=1; t<=M. tu; ++t)
++num[M.data[t].j]; // 求 M 中每一列所含非零元的个数
cpot[1] = 1;
//求第col列中第一个非零元素在b.data中的序号
for (col=2; col<=M. nu; ++col)
cpot[col] = cpot[col-1] + num[col-1];
// 求T中每一行的第一个非零元在T.data中的序号
for (p=1; p<=M.tu; ++p) // 转置矩阵元素
col = M.data[p].j; q = cpot[col];
T.data[q].i =M.data[p].j;
T.data[q].j =M.data[p].i;
T.data[q].e =M.data[p].e;
++cpot[col];
// for
// if
// FastTransposeSMatrix
T(n)=O(M的列数n+非零元个数t,若 t 与m*n同数量级,则T(n)=O(m*n)
四、广义表
1.概念
- 广义表:n个表元素组成的有限序列,GL = (d0, d1, …, dn-1) GL是表名,d为表元素
- 表头(head):表中第一个元素,GetHead()取表头
- 表尾(tail):表中最后一个元素,GetTail()取表尾
- 长度:最外层包含元素的个数
- 深度:最大所含括弧的重数
2.运算

- GetHead :取广义表的第一个元素,去除最外一层括号
- GetTail : 取广义表的最后一个元素,不去除最外一层括号
- 深度 :最大的括号重数,上图D E F A深度分别为1 2 2 1
- 长度 :表中元素个数,上图E和F元素个数为2
3.存储结构
- 特点:由于广义表是递归定义的一种带有层次的非线性结构,数据元素具有不同的结构,常常采用链式存储
- 表结点:标志域、表头指针域、表尾指针域组成
- 原子结点:标志域、值域组成
头尾链表存储结构:

代码实现:
typedef enumATOM, LIST ElemTag; /* ATOM==0:原子,LIST==1:子表 */
typedef struct GLNode
ElemTag tag; /* 公共部分,用于区分原子结点和表结点 */
union /* 原子结点和表结点的联合部分 */
AtomType atom; /* atom是原子结点的值域,AtomType由用户定义 */
struct
struct GLNode *hp,*tp;
htp; /*表结点的指针域htp,包括表头指针域hp和表尾指针域tp*/
atom_htp; /* atom_htp 是原子结点的值域atom和表结点的指针域htp 的联合体域*/
*GList,GLNode; /* 广义表类型 */扩展线性链表存储结构:

代码实现:
typedef enumATOM, LISTElemTag; // ATOM==0:原子,LIST==1:子表
typedef struct GLNode
ElemTag tag; // 公共部分,用于区分原子结点和表结点 union // 原子结点和表结点的联合部分
AtomType atom; // 原子结点的值域
struct GLNode *hp; // 表结点的表头指针
atom_hp;
struct GLNode *tp; // 相当于线性链表的next,指向下一个元素结点
*GList,GLNode; // 广义表类型GList是一种扩展的线性链表
以上是关于C语言数据结构与算法--------数组和广义表全面总结的主要内容,如果未能解决你的问题,请参考以下文章