数仓开发那些事
Posted 徐一闪_BigData
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数仓开发那些事相关的知识,希望对你有一定的参考价值。
某不愿意透露姓名的神州实习生:一闪,听说你最近一直在摸鱼?
我:开发人的事,能叫摸鱼吗,一个需求给我3天,我1天就做完了,要是直接交上去,那不得被压榨吗?
神州实习生:原来是这样,那你抽个时间帮我写数据接口,晚上我把SQL发你

Spark与Flink的区别
老程序员:明天咱们要招实习生了,快给我出点面试题
我:(???)那之前面我的时候题目谁出的
老程序员:(= =)那肯定是我亲自出的,因为我很欣赏你
我:……那开局第一个问题:Spark和Flink的区别
老程序员:这问题人人都问,他们估计都背熟了
我:可以问深一点嘛,比如他们会说”Spark只支持处理时间,但是Flink还支持事件时间”,然后就告诉他们”StructStreaming是支持事件时间的,有了解吗?”
老程序员:真笋啊(我喜欢)

我:如果他们没提到CK的话,就让补充一下,比如Flink只存储状态数据,SparkStreaming还存储计算逻辑,因为底层调用的是ssc的getActiveOrCreate()方法巴拉巴拉
深究
老程序员:不错不错.再说两个
我:Emmmm,那就再问个共享组,这东西据我所知不是经常问,出其不意(必自bi),Map在G1组中,因为FlatMap被指定为G1组后,与前面的Filter无法组成任务链,但是与后面的Map仍有可能组成任务链,从这一点出发,Map是属于G1组的(你可别问我源码怎么写的,我可不会啊)
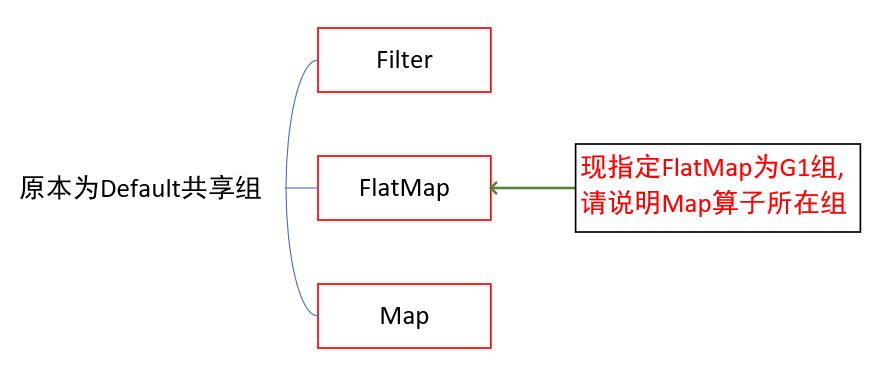
老程序员:源码里怎么体现的?

我:...我又想到一个问题(赶紧扯开话题),对于事件时间,当一条流中的数据有时稀疏有时密集时,我们选用间歇型生成WaterMark还是周期型?
老程序员:周期型,因为对于在面对数据密集的流时,使用间歇型会导致我们的每一条数据都带有WaterMark,如果再考虑WaterMark的广播,数据量会急剧增长,所以只要有数据密集的可能性,就应该避免间歇型.对于数据稀疏的情况,虽然周期型也会生成多余的WaterMark,但是当数据量少时,程序压力也较小,这是完全可以接受的.
我:那你再说说看,FlinkCDC、MaxWell、Canal的区别
老程序员: ↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
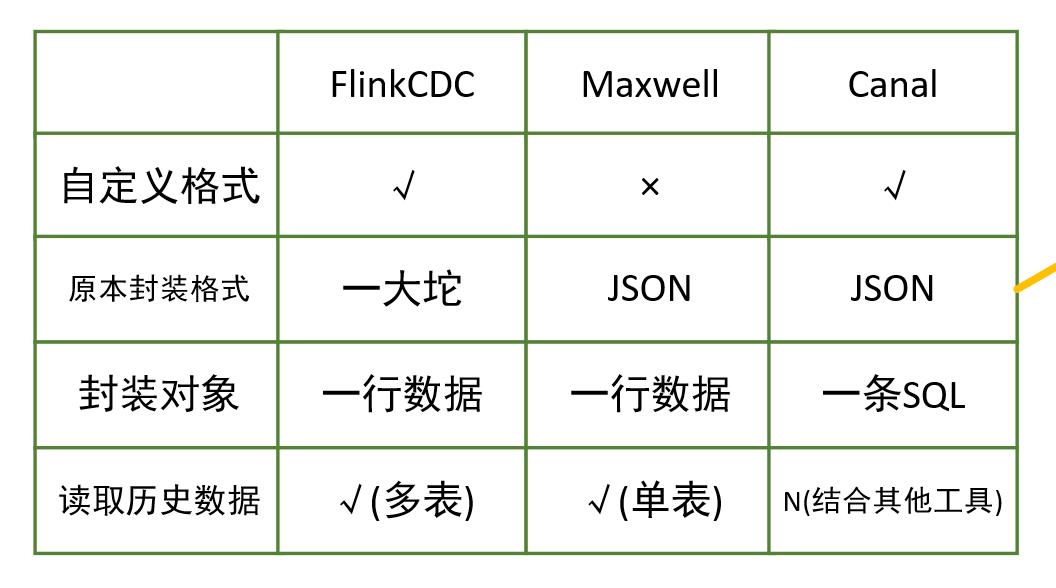
我:你这一套我都听烂了,有没有其他新鲜点的?
老程序员: 在FlinkCDC1.0中初始化过程中会锁表,并且是单线程的,所以没人用,直到2.0版本之后,我才开始在构建时把它考虑进去

我:我们公司在离线架构上对于hive表多半都是Parquet存储,唯独Ads层没有指定Parquet.你知道是为什么吗?
老程序员:可能是贵司用的是Hive On Spark吧,Spark对Parquet是有优化的,对于Ads层的数据可能要导出到Mysql,所以没有使用列存
我:最后一个问题吧,谈谈你了解的Kafka
老程序员:Kafka是一个高吞吐的分布式消息队列(省略2000字架构介绍),常常是用来做实时数仓的分层和起到一个聚合的作用,在19年的时候,有个叫Pulsar的玩意顶替Kafka成为了Apache的顶级项目,但是好像也没有什么后文了.
我:不错,你有什么问题要问我的吗.
老程序员:明天你和我一起去面新人.你负责提问题,记得多出几个啊.

以上是关于数仓开发那些事的主要内容,如果未能解决你的问题,请参考以下文章