DVCon2020加速图像IP功耗分析的方法
Posted MangoPapa
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DVCon2020加速图像IP功耗分析的方法相关的知识,希望对你有一定的参考价值。
📢 声明:
- 🥭 作者主页:【MangoPapa的CSDN主页】。
- ⚠️ 本文首发于CSDN,转载或引用请注明出处【点击查看原文】。
- ⚠️ 本专栏目的为 学术论文分享,本文为非盈利性质,仅用于 个人学习记录 及 知识分享。
- ⚠️ 若本文所采用图片或相关引用侵犯了您的合法权益,请联系我进行删除。
- 😄 欢迎大家指出文章错误,欢迎同行与我交流 ~
- 📧 邮箱:mangopapa@yeah.net
论文题目
Efficient Methods for Display Power Estimation and Visualization
这是Intel工程师发表在DVCon2020上的论文,讨论了图形IP功耗分析的加速问题。
研究目的
功耗在图形领域变得越来越重要,在硅前完成准确的平均功耗和峰值功耗尤为重要。在Intel内部,常用的功耗估计办法是跑仿真、根据RTL toggle计算功耗。
常规的图像IP功耗估算流程如下:
- 根据产品性能要求确认IP的工作负载,比如图像分辨率、视频帧率;
- 用第1步的参数配置RTL,然后跑仿真,dump fsdb波形及saif文件;(👈这里卡脖子了)
- 跑完后,功耗分析工具(PrimeTime PX等)吃fsdb/saif,吐出功耗分析报告。
对于单帧图像而言,仿真时间几十个小时,采用这种功耗计算方法尚可接受。但对于UHD超高清或8K视频而言及多帧图像的情况,这种估算方法所需的仿真时间动辄十几天甚至几个月,工程师们分析完功耗后做些优化,重新分析又需要重新来一遍,这对项目schedule是很不友好的,是难以接受的。
得想办法加速仿真。
新方法
方法1 Emulation 跑仿真
找个palladium或zebu等emulation平台来加速仿真,这个方法似乎并不新奇,大多公司都这么干的吧。下图是simulation和emulation跑仿真的flow。
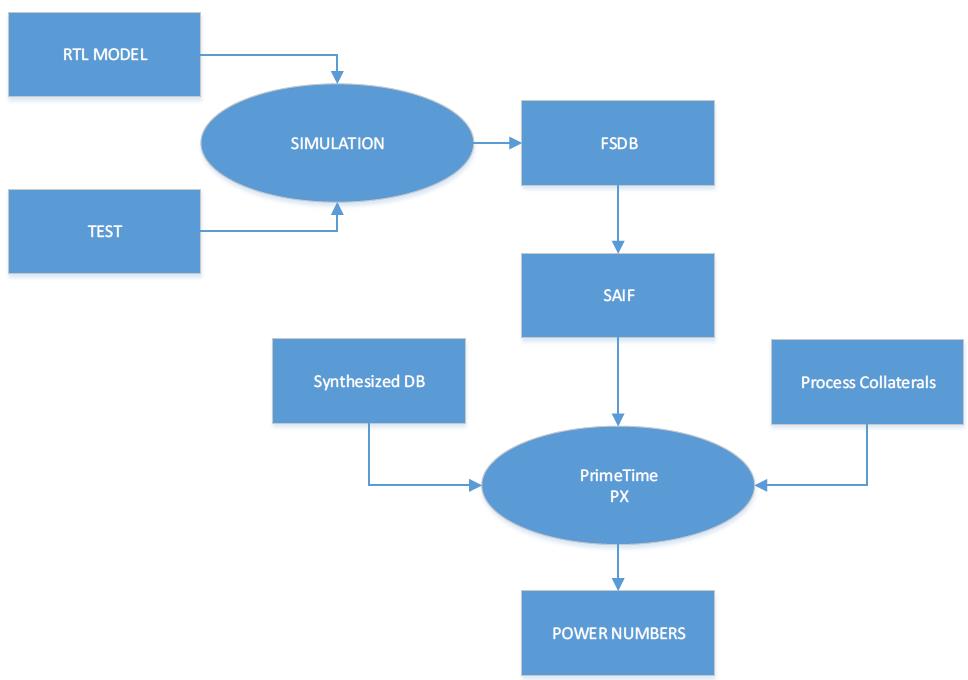
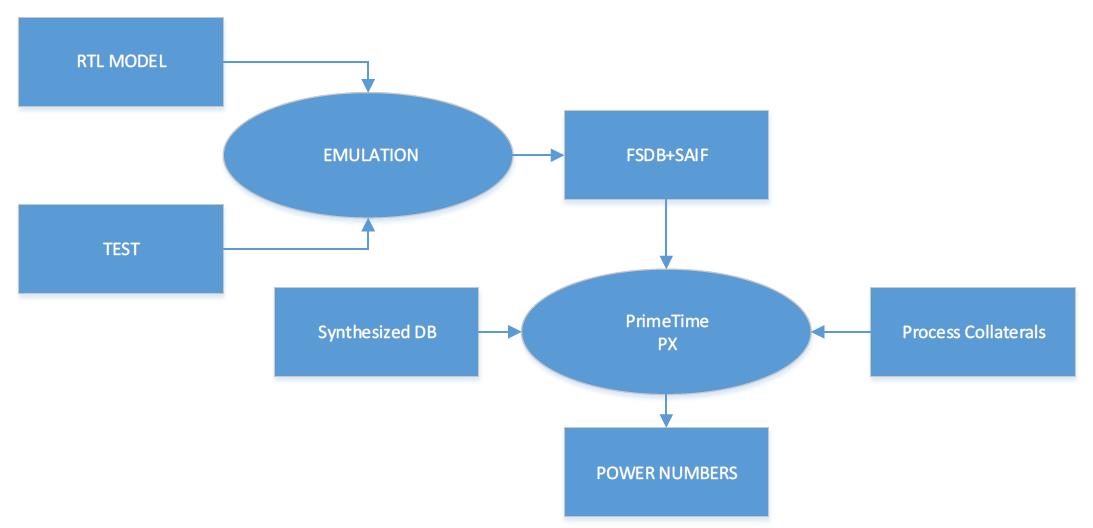
方法2 SPLIT方法
这个方法说来也简单,拿server资源换速度。原来跑一次仿真dump一个波形,现在是并行跑多个仿真,dump多个更小的波形,每个小波形开始dump的起始时间前后衔接,最后把多个波形合并到一块。图3、图4是本文提到的SPLIT方法及仿真过程。这个例子中以16ms分4份为例,每个波形dump 4ms,具体操作过程中可以拆分为更多更小的波形。
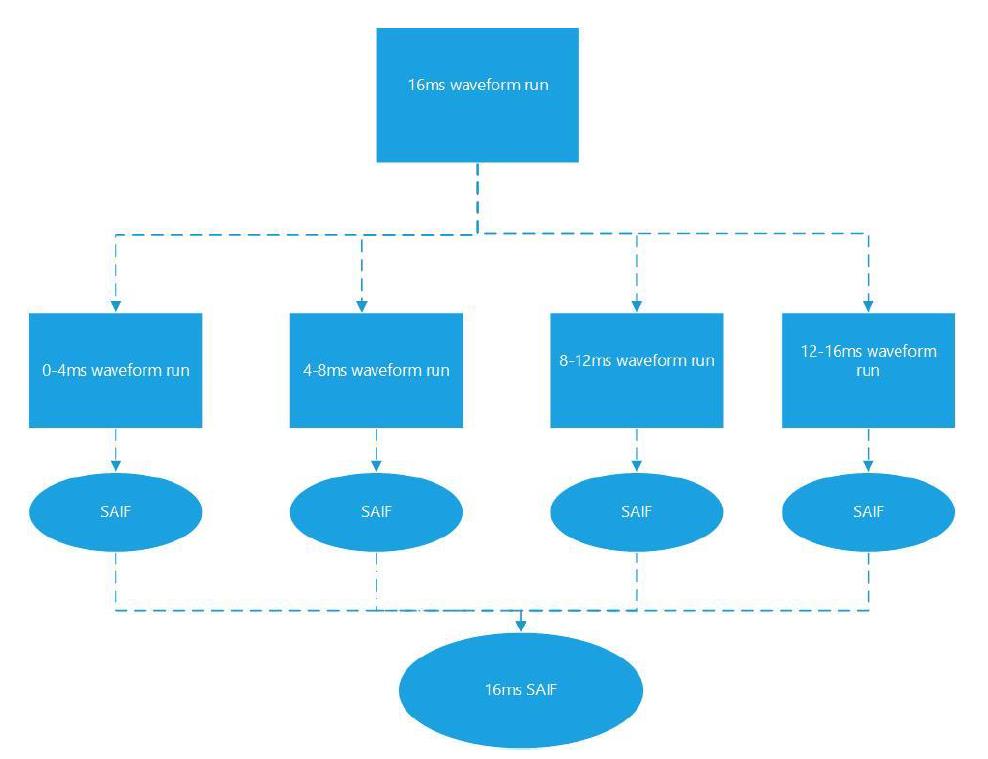
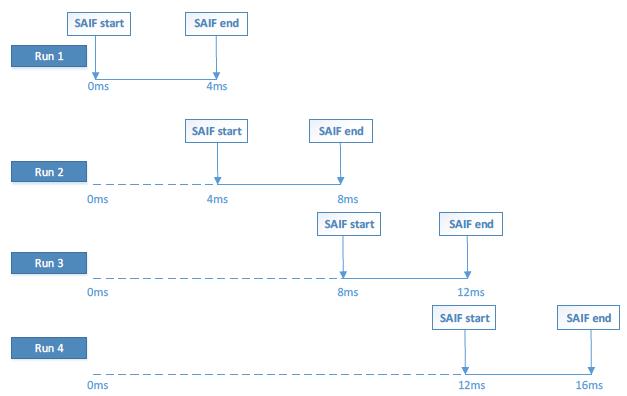
讨论
emulation加速仿真的方法没得说,挺好。
这个SPLIT的方法,不能用于随机仿真。非要随机的话,这些并行跑的case必须用相同的seed,生成完全一样的随机配置参数,跑相同的图。问题是,我以为的随机相同,真的相同吗?如非必要,不推荐采用这种方法。
完
⬆️ 返回顶部 ⬆️
以上是关于DVCon2020加速图像IP功耗分析的方法的主要内容,如果未能解决你的问题,请参考以下文章