2021年大数据ELK(二十):FileBeat是如何工作的
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2021年大数据ELK(二十):FileBeat是如何工作的相关的知识,希望对你有一定的参考价值。
全网最详细的大数据ELK文章系列,强烈建议收藏加关注!
新文章都已经列出历史文章目录,帮助大家回顾前面的知识重点。
目录
FileBeat是如何工作的
FileBeat主要由input和harvesters(收割机)组成。这两个组件协同工作,并将数据发送到指定的输出。
一、input和harvester
1、inputs(输入)
input是负责管理Harvesters和查找所有要读取的文件的组件。如果输入类型是 log,input组件会查找磁盘上与路径描述的所有文件,并为每个文件启动一个Harvester,每个输入都独立地运行。
2、Harvesters(收割机)
Harvesters负责读取单个文件的内容,它负责打开/关闭文件,并逐行读取每个文件的内容,并将读取到的内容发送给输出,每个文件都会启动一个Harvester。但Harvester运行时,文件将处于打开状态。如果文件在读取时,被移除或者重命名,FileBeat将继续读取该文件。
二、FileBeats如何保持文件状态
FileBeat保存每个文件的状态,并定时将状态信息保存在磁盘的「注册表」文件中,该状态记录Harvester读取的最后一次偏移量,并确保发送所有的日志数据。如果输出(Elasticsearch或者Logstash)无法访问,FileBeat会记录成功发送的最后一行,并在输出(Elasticsearch或者Logstash)可用时,继续读取文件发送数据。在运行FileBeat时,每个input的状态信息也会保存在内存中,重新启动FileBeat时,会从「注册表」文件中读取数据来重新构建状态。
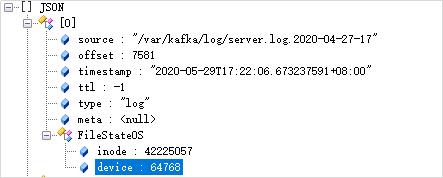
在/export/server/es/filebeat-7.6.1-linux-x86_64/data目录中有一个Registry文件夹,里面有一个data.json,该文件中记录了Harvester读取日志的offset。
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢大数据系列文章会每天更新,停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
以上是关于2021年大数据ELK(二十):FileBeat是如何工作的的主要内容,如果未能解决你的问题,请参考以下文章
2021年大数据ELK(二十二):采集Apache Web服务器日志
2021年大数据ELK(十八):Beats 简单介绍和FileBeat工作原理
2021年大数据ELK(十九):使用FileBeat采集Kafka日志到Elasticsearch