使用Python 探索和分析数据:入门的入门
Posted java构架师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用Python 探索和分析数据:入门的入门相关的知识,希望对你有一定的参考价值。
在几十年的开源开发后,Python 通过强大的统计和数值库提供丰富的功能:
- NumPy 和 Pandas 简化了数据分析和操作
- Matplotlib 提供引人注目的数据可视化效果
- Scikit-learn 提供简单有效的预测性数据分析
- TensorFlow 和 PyTorch 提供机器学习和深度学习功能
利用 NumPy 和 Pandas 浏览数据
数据科学家可以使用各种工具和技术来浏览、直观呈现和操作数据。 数据科学家处理数据最常用的方法之一是使用 Python 语言和一些特定的数据处理包。
什么是 NumPy
NumPy 是一个 Python 库,提供与 MATLAB 和 R 等数学工具相当的功能。尽管 NumPy 大大简化了用户体验,但它还提供了全面的数学函数。
什么是 Pandas
Pandas 是一个极其热门的 Python 库,用于数据分析和操作。 Pandas 对于 Python 而言就像 excel,提供适用于数据表的易于使用的功能。
探索 Jupyter 笔记本中的数据
Jupyter Notebook 是使用 Web 浏览器运行基本脚本的一种常用方式。 通常,这些笔记本都是单个网页,分解为在服务器上(而不是本地计算机)上执行的文本部分和代码部分。 这意味着你可以快速开始,而无需安装 Python 或其他工具。
测试假设
数据探索和分析通常是一个迭代过程,数据科学家在其中进行数据采样,并执行以下任务来分析数据和检验假设:
- 清理数据以处理错误、缺失值和其他问题。
- 应用统计技术来更好地理解数据,更好地了解样本如何预期地代表真实世界的总体数据(允许随机变化)。
- 直观呈现数据来确定变量之间的关系,在机器学习项目中,识别可能预测标签的特征。
- 修正假设并重复这个过程。
使用NumPy探索数据数组
让我们先看一些简单的数据。
假设一所大学收集了一门数据科学课程的学生成绩样本。
data = [50,50,47,97,49,3,53,42,26,74,82,62,37,15,70,27,36,35,48,52,63,64]
print(data)
数据已加载到Python列表结构中,这是用于一般数据操作的良好数据类型,但对于数值分析没有进行优化。为此,我们将使用NumPy包,它包括在Python中使用Numbers的特定数据类型和函数。
import numpy as np
grades = np.array(data)
print(grades)

如果您想知道列表和NumPy数组之间的区别,让我们比较一下这些数据类型在表达式中乘以2时的表现。

请注意,将列表乘以2将创建一个长度为原来列表元素序列两倍的新列表。另一方面,将NumPy数组相乘执行的是按元素计算,其中数组的行为类似于vector,因此最终得到一个大小相同的数组,其中每个元素都乘以2。
关键在于NumPy数组是专门为支持数值数据的数学操作而设计的——这使得它们在数据分析中比通用列表更有用。
grades.shape
确认该数组只有一个维度,其中包含22个元素(在原始列表中有22个分数)。您可以通过数组中各个元素的从零开始的序号位置来访问它们。让我们获得第一个元素(位置0的那个)。 好了,现在您已经熟悉了NumPy数组,是时候对成绩数据进行一些分析了。 您可以跨数组中的元素应用聚合,因此让我们找到简单的平均分数 grades.mean() 49.18181818181818 因此他的平均分为49分 让我再添加一组数据 让我们为同样的学生添加第二组数据,这一次记录他们每周用于学习的典型小时数
study_hours = [10.0,11.5,9.0,16.0,9.25,1.0,11.5,9.0,8.5,14.5,15.5,
13.75,9.0,8.0,15.5,8.0,9.0,6.0,10.0,12.0,12.5,12.0]
# Create a 2D array (an array of arrays)
student_data = np.array([study_hours, grades])
# display the array
print(student_data)
展示二维数组
print(student_data.shape) 现在就变成了二维数组 前面是学习时间 后面是成绩 用来分析一下相关信息
获得每个子列的平均值
avg_study = student_data[0].mean()
avg_grade = student_data[1].mean()
print('Average study hours: :.2f\\nAverage grade: :.2f'.format(avg_study, avg_grade))
使用 Pandas 探索表格数据
虽然 NumPy 提供了许多处理数字所需的功能,特别是数值数组;当您开始处理二维数据表时,Pandas包提供了一个更方便的结构 - DataFrame。
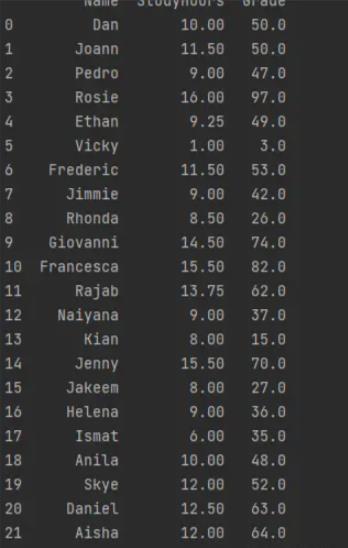
运行以下单元格以导入 Pandas 库并创建一个包含三列的 DataFrame。第一列是学生姓名列表,第二列和第三列是包含学习时间和成绩数据的 NumPy 数组。
import pandas as pd
df_students = pd.DataFrame('Name': ['Dan', 'Joann', 'Pedro', 'Rosie', 'Ethan', 'Vicky', 'Frederic', 'Jimmie',
'Rhonda', 'Giovanni', 'Francesca', 'Rajab', 'Naiyana', 'Kian', 'Jenny',
'Jakeem','Helena','Ismat','Anila','Skye','Daniel','Aisha'],
'StudyHours':student_data[0],
'Grade':student_data[1])
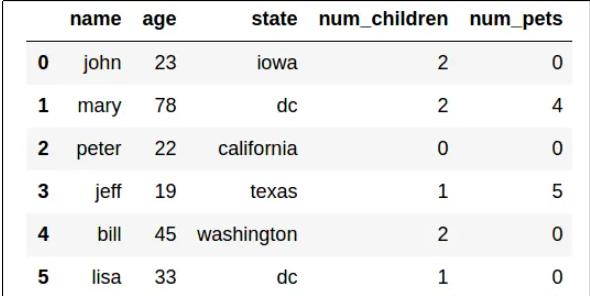
在 DataFrame 中查找和过滤数据
您可以使用 DataFrame 的loc方法来检索特定索引值的数据,如下所示。
得到索引为5的数据
df_students.loc[5]
也有切片操作
df_students.loc[0:5]
除了可以使用loc方法根据索引查找行之外,您还可以使用iloc方法根据行在DataFrame 中的序数位置查找行(与索引无关):
仔细查看iloc[0:5]结果,并将它们与loc[0:5]您之前获得的结果进行比较。您看得出来差别吗?
所述LOC方法返回的行与索引标签中的值从列表0至5,其包括- 0,1,2,3,4,和5(6行)。但是,iloc方法返回范围 0 到 5 中包含的位置中的行,并且由于整数范围不包括上限值,这包括位置0、1、2、3和4(五行) .
iloc通过位置标识DataFrame 中的数据值,位置从行扩展到列。因此,例如,您可以使用它来查找第 0 行中位置 1 和 2 中的列的值,如下所示: df_students.iloc[0,[1,2]]
让我们回到loc方法,看看它是如何处理列的。请记住,loc用于根据索引值而不是位置来定位数据项。在没有显式索引列的情况下,我们数据框中的行被索引为整数值,但列由名称标识: df_students.loc[0,'Grade']
这是另一个有用的技巧。您可以使用loc方法根据过滤表达式查找索引行,该表达式引用索引以外的命名列,如下所示:df_students.loc[df_students['Name']=='Aisha']
为了更好地衡量,您可以使用 DataFrame 的查询方法获得相同的结果,如下所示:df_students[df_students['Name']=='Aisha']
前面的三个例子强调了使用 Pandas 时有时会令人困惑的事实。通常,有多种方法可以实现相同的结果。另一个例子是您引用 DataFrame 列名称的方式。您可以将列名指定为命名索引值(如df_students['Name']我们目前所见的示例),或者您可以将该列用作 DataFrame 的属性,如下所示:df_students[df_students.Name == 'Aisha']
从文件加载 DataFrame
我们从一些现有的数组构建了 DataFrame。但是,在许多实际场景中,数据是从文件等源加载的。让我们用文本文件的内容替换学生成绩 DataFrame。
df_students = pd.read_csv('grades.csv',delimiter=',',header='infer')
df_students.head()
DataFrame 的read_csv方法用于从文本文件加载数据。正如您在示例代码中看到的那样,您可以指定诸如列分隔符和哪一行(如果有)包含列标题(在这种情况下,分隔符是一个逗号,第一行包含列名——这些是默认设置,因此可以省略参数)。
处理缺失值
数据科学家需要处理的最常见问题之一是数据不完整或缺失。那么我们如何知道 DataFrame 包含缺失值呢?您可以使用isnull方法来识别哪些单独的值为 null,如下所示: df_students.isnull() 当然,对于较大的 DataFrame,单独查看所有行和列将是低效的;所以我们可以得到每列缺失值的总和,如下所示:df_students.isnull().sum() 所以现在我们知道缺少一个StudyHours值和两个缺少Grade值。
要在上下文中查看它们,我们可以过滤数据框以仅包含任何列(数据框的轴 1)为空的行。 df_students[df_students.isnull().any(axis=1)] 检索 DataFrame 时,缺失的数值显示为NaN(不是数字)。
那么既然我们已经找到了空值,我们可以对它们做些什么呢?
一种常见的方法是估算替换值。例如,如果缺少学习时数,我们可以假设学生学习了平均时间并将缺失值替换为平均学习时数。为此,我们可以使用fillna方法,如下所示: df_students.StudyHours = df_students.StudyHours.fillna(df_students.StudyHours.mean()) 或者,确保您只使用您知道绝对正确的数据可能很重要;因此您可以使用dropna方法删除包含空值的行或列。在这种情况下,我们将删除任何列包含空值的行(DataFrame 的轴 0)df_students = df_students.dropna(axis=0, how='any')
探索 DataFrame 中的数据
现在我们已经清理了缺失值,我们准备好探索 DataFrame 中的数据。让我们从比较平均学习时间和成绩开始。
mean_study = df_students['StudyHours'].mean()
# Get the mean grade using the column name as a property (just to make the point!)
mean_grade = df_students.Grade.mean()
# Print the mean study hours and mean grade
print('Average weekly study hours: :.2f\\nAverage grade: :.2f'.format(mean_study, mean_grade))
好的,让我们过滤 DataFrame 以仅查找学习时间超过平均时间的学生。
df_students[df_students.StudyHours > mean_study] 请注意,过滤后的结果本身就是一个 DataFrame,因此您可以像处理任何其他 DataFrame 一样处理其列。
例如,让我们找出学习时间超过平均学习时间的学生的平均成绩。 df_students[df_students.StudyHours > mean_study].Grade.mean()
让我们假设课程的及格分数是 60。
我们可以使用该信息向 DataFrame 添加一个新列,指示每个学生是否通过了。
首先,我们将创建一个包含通过/失败指标(True 或 False)的 Pandas系列,然后我们将该系列连接为 DataFrame 中的一个新列(轴 1)。 passes = pd.Series(df_students['Grade'] >= 60) df_students = pd.concat([df_students, passes.rename("Pass")], axis=1) DataFrames 是为表格数据设计的,您可以使用它们来执行您可以在关系数据库中执行的多种数据分析操作;例如对数据表进行分组和聚合。
例如,您可以使用groupby方法根据您之前添加的Pass列将学生数据分组,并计算每组中的姓名数量 - 换句话说,您可以确定有多少学生通过和失败。 print(df_students.groupby(df_students.Pass).Name.count())
您可以使用任何可用的聚合函数聚合一个组中的多个字段。例如,您可以找到通过和未通过课程的学生组的平均学习时间和成绩print(df_students.groupby(df_students.Pass)['StudyHours', 'Grade'].mean())
DataFrame 的用途非常广泛,可以轻松操作数据。许多 DataFrame 操作返回 DataFrame 的新副本;所以如果你想修改一个DataFrame但保留现有的变量,你需要将操作的结果赋值给现有的变量。例如,以下代码将学生数据按 Grade 降序排序,并将排序后的 DataFrame 分配给原始df_students变量。 df_students = df_students.sort_values('Grade', ascending=False)
Numpy 和 DataFrames 是 Python 数据科学的主力军。它们为我们提供了加载、探索和分析表格数据的方法。正如我们将在后续模块中看到的,即使是高级分析方法通常也依赖 Numpy 和 Pandas 来发挥这些重要作用。
以上是关于使用Python 探索和分析数据:入门的入门的主要内容,如果未能解决你的问题,请参考以下文章