这可能是最全的总结了,详解 20 个 pandas 读与写函数
Posted Python学习与数据挖掘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了这可能是最全的总结了,详解 20 个 pandas 读与写函数相关的知识,希望对你有一定的参考价值。
大家好,今天来为大家介绍几个Pandas读取数据以及保存数据的方法,毕竟我们很多时候需要读取各种形式的数据,以及将我们需要将所做的统计分析保存成特定的格式。
注:应很多朋友的要求,文末创建了技术交流群,欢迎加入
我们大致会说到的方法有:
-
read_sql() -
to_sql() -
read_clipboard() -
from_dict() -
to_dict() -
to_clipboard() -
read_json() -
to_json() -
read_html() -
to_html() -
read_table() -
read_csv() -
to_csv() -
read_excel() -
to_excel() -
read_xml() -
to_xml() -
read_pickle() -
to_pickle()
read_sql()与to_sql()
我们一般读取数据都是从数据库中来读取的,因此可以在read_sql()方法中填入对应的sql语句然后来读取我们想要的数据,
pd.read_sql(sql, con, index_col=None,
coerce_float=True, params=None,
parse_dates=None,
columns=None, chunksize=None)
参数详解如下:
-
sql: SQL命令字符串
-
con: 连接SQL数据库的Engine,一般用SQLAlchemy或者是Pymysql之类的模块来建立
-
index_col:选择某一列作为Index
-
coerce_float:将数字形式的字符串直接以float型读入
-
parse_dates: 将某一列日期型字符串传唤为datatime型数据,可以直接提供需要转换的列名以默认的日期形式转换,或者也可以提供字典形式的列名和转换日期的格式,
我们用PyMysql这个模块来连接数据库,并且读取数据库当中的数据,首先我们导入所需要的模块,并且建立起与数据库的连接
import pandas as pd
from pymysql import *
conn = connect(host='localhost', port=3306, database='database_name',
user='', password='', charset='utf8')
我们简单地写一条SQL命令来读取数据库当中的数据,并且用read_sql()方法来读取数据
sql_cmd = "SELECT * FROM table_name"
df = pd.read_sql(sql_cmd, conn)
df.head()
上面提到read_sql()方法当中parse_dates参数可以对日期格式的数据进行处理,那我们来试一下其作用
sql_cmd_2 = "SELECT * FROM test_date"
df_1 = pd.read_sql(sql_cmd_2, conn)
df_1.head()
output
number date_columns
0 1 2021-11-11
1 2 2021-10-01
2 3 2021-11-10
我们来看一个各个列的数据类型
df_1.info()
output
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3 entries, 0 to 2
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 number 3 non-null int64
1 date_columns 3 non-null object
dtypes: int64(1), object(1)
memory usage: 176.0+ bytes
正常默认情况下,date_columns这一列也是被当做是String类型的数据,要是我们通过parse_dates参数将日期解析应用与该列
df_2 = pd.read_sql(sql_cmd_2, conn, parse_dates="date_columns")
df_2.info()
output
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3 entries, 0 to 2
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 number 3 non-null int64
1 date_columns 3 non-null datetime64[ns]
dtypes: datetime64[ns](1), int64(1)
memory usage: 176.0 bytes
就转换成了相对应的日期格式,当然我们还可以采用上面提到的另外一种格式
parse_dates="date_column": "format": "%d/%m/%y")
to_sql()方法
我们来看一下to_sql()方法,作用是将DataFrame当中的数据存放到数据库当中,请看下面的示例代码,我们创建一个基于内存的SQLite数据库
from sqlalchemy import create_engine
engine = create_engine('sqlite://', echo=False)
然后我们创建一个用于测试的数据集,并且存放到该数据库当中,
df = pd.DataFrame('num': [1, 3, 5])
df.to_sql('nums', con=engine)
查看一下是否存取成功了
engine.execute("SELECT * FROM nums").fetchall()
output
[(0, 1), (1, 3), (2, 5)]
我们可以尝试着往里面添加数据
df2 = pd.DataFrame('num': [7, 9, 11])
df2.to_sql('nums', con=engine, if_exists='append')
engine.execute("SELECT * FROM nums").fetchall()
output
[(0, 1), (1, 3), (2, 5), (0, 7), (1, 9), (2, 11)]
注意到上面的if_exists参数上面填的是append,意味着添加新数据进去,当然我们也可以将原有的数据替换掉,将append替换成replace
df2.to_sql('nums', con=engine, if_exists='replace')
engine.execute("SELECT * FROM nums").fetchall()
output
[(0, 7), (1, 9), (2, 11)]
from_dict()方法和to_dict()方法
有时候我们的数据是以字典的形式存储的,有对应的键值对,我们如何根据字典当中的数据来创立DataFrame,假设
a_dict =
'学校': '清华大学',
'地理位置': '北京',
'排名': 1
一种方法是调用json_normalize()方法,代码如下
df = pd.json_normalize(a_dict)
output
学校 地理位置 排名
0 清华大学 北京 1
当然我们直接调用pd.DataFrame()方法也是可以的
df = pd.DataFrame(json_list, index = [0])
output
学校 地理位置 排名
0 清华大学 北京 1
当然我们还可以用from_dict()方法,代码如下
df = pd.DataFrame.from_dict(a_dict,orient='index').T
output
学校 地理位置 排名
0 清华大学 北京 1
这里最值得注意的是orient参数,用来指定字典当中的键是用来做行索引还是列索引,请看下面两个例子
data = 'col_1': [1, 2, 3, 4],
'col_2': ['A', 'B', 'C', 'D']
我们将orient参数设置为columns,将当中的键当做是列名
df = pd.DataFrame.from_dict(data, orient='columns')
output
col_1 col_2
0 1 A
1 2 B
2 3 C
3 4 D
当然我们也可以将其作为是行索引,将orient设置为是index
df = pd.DataFrame.from_dict(data, orient='index')
output
0 1 2 3
col_1 1 2 3 4
col_2 A B C D
to_dict()方法
语法如下:
df.to_dict(orient='dict')
针对orient参数,一般可以填这几种形式
一种是默认的dict,代码如下
df = pd.DataFrame('shape': ['square', 'circle', 'triangle'],
'degrees': [360, 360, 180],
'sides': [4, 5, 3])
df.to_dict(orient='dict')
output
'shape': 0: 'square', 1: 'circle', 2: 'triangle', 'degrees': 0: 360, 1: 360, 2: 180, 'sides': 0: 4, 1: 5, 2: 3
也可以是list,代码如下
df.to_dict(orient='list')
output
'shape': ['square', 'circle', 'triangle'], 'degrees': [360, 360, 180], 'sides': [4, 5, 3]
除此之外,还有split,代码如下
df.to_dict(orient='split')
output
'index': [0, 1, 2], 'columns': ['shape', 'degrees', 'sides'], 'data': [['square', 360, 4], ['circle', 360, 5], ['triangle', 180, 3]]
还有records,代码如下
df.to_dict(orient='records')
output
['shape': 'square', 'degrees': 360, 'sides': 4, 'shape': 'circle', 'degrees': 360, 'sides': 5, 'shape': 'triangle', 'degrees': 180, 'sides': 3]
最后一种是index,代码如下
df.to_dict(orient='index')
output
0: 'shape': 'square', 'degrees': 360, 'sides': 4, 1: 'shape': 'circle', 'degrees': 360, 'sides': 5, 2: 'shape': 'triangle', 'degrees': 180, 'sides': 3
read_json()方法和to_json()方法
我们经常也会在实际工作与学习当中遇到需要去处理JSON格式数据的情况,我们用Pandas模块当中的read_json()方法来进行处理,我们来看一下该方法中常用到的参数
orient:对应JSON字符串的格式主要有
split: 格式类似于:index: [index], columns: [columns], data: [values]
例如我们的JSON字符串长这样
a = '"index":[1,2,3],"columns":["a","b"],"data":[[1,3],[2,8],[3,9]]'
df = pd.read_json(a, orient='split')
output
a b
1 1 3
2 2 8
3 3 9
records: 格式类似于:[column: value, ... , column: value]
例如我们的JSON字符串长这样
a = '["name":"Tom","age":"18","name":"Amy","age":"20","name":"John","age":"17"]'
df_1 = pd.read_json(a, orient='records')
output
name age
0 Tom 18
1 Amy 20
2 John 17
index: 格式类似于:index: column: value
例如我们的JSON字符串长这样
a = '"index_1":"name":"John","age":20,"index_2":"name":"Tom","age":30,"index_3":"name":"Jason","age":50'
df_1 = pd.read_json(a, orient='index')
output
name age
index_1 John 20
index_2 Tom 30
index_3 Jason 50
columns: 格式类似于:column: index: value
我们要是将上面的index变成columns,就变成
df_1 = pd.read_json(a, orient='columns')
output
index_1 index_2 index_3
name John Tom Jason
age 20 30 50
values: 数组
例如我们的JSON字符串长这样
v='[["a",1],["b",2],["c", 3]]'
df_1 = pd.read_json(v, orient="values")
output
0 1
0 a 1
1 b 2
2 c 3
to_json()方法
将DataFrame数据对象输出成JSON字符串,可以使用to_json()方法来实现,其中orient参数可以输出不同格式的字符串,用法和上面的大致相同,这里就不做过多的赘述
read_html()方法和to_html()方法
有时候我们需要抓取网页上面的一个表格信息,相比较使用Xpath或者是Beautifulsoup,我们可以使用pandas当中已经封装好的函数read_html来快速地进行获取,例如我们通过它来抓取菜鸟教程Python网站上面的一部分内容
url = "https://www.runoob.com/python/python-exceptions.html"
dfs = pd.read_html(url, header=None, encoding='utf-8')
返回的是一个list的DataFrame对象
df = dfs[0]
df.head()
output
异常名称 描述
0 NaN NaN
1 BaseException 所有异常的基类
2 SystemExit 解释器请求退出
3 KeyboardInterrupt 用户中断执行(通常是输入^C)
4 Exception 常规错误的基类
当然read_html()方法也支持读取HTML形式的表格,我们先来生成一个类似这样的表格,通过to_html()方法
df = pd.DataFrame(np.random.randn(3, 3))
df.to_html("test_1.html")
当然这个HTML形式的表格长这个样子
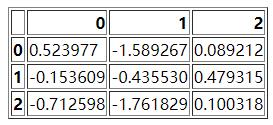
然后我们再通过read_html方法读取该文件,
dfs = pd.read_html("test_1.html")
dfs[0]
read_csv()方法和to_csv()方法
read_csv()方法
read_csv()方法是最常被用到的pandas读取数据的方法之一,其中我们经常用到的参数有
- filepath_or_buffer: 数据输入的路径,可以是文件的路径的形式,例如
pd.read_csv('data.csv')
output
num1 num2 num3 num4
0 1 2 3 4
1 6 12 7 9
2 11 13 15 18
3 12 10 16 18
也可以是URL,如果访问该URL会返回一个文件的话
pd.read_csv("http://...../..../data.csv")
- sep: 读取
csv文件时指定的分隔符,默认为逗号,需要注意的是:“csv文件的分隔符”要和“我们读取csv文件时指定的分隔符”保持一致
假设我们的数据集,csv文件当中的分隔符从逗号改成了"\\t",需要将sep参数也做相应的设定
pd.read_csv('data.csv', sep='\\t')
- index_col: 我们在读取文件之后,可以指定某一列作为
DataFrame的索引
pd.read_csv('data.csv', index_col="num1")
output
num2 num3 num4
num1
1 2 3 4
6 12 7 9
11 13 15 18
12 10 16 18
除了指定单个列,我们还可以指定多个列,例如
df = pd.read_csv("data.csv", index_col=["num1", "num2"])
output
num3 num4
num1 num2
1 2 3 4
6 12 7 9
11 13 15 18
12 10 16 18
- usecols:如果数据集当中的列很多,而我们并不想要全部的列、而是只要指定的列就可以,就可以使用这个参数
pd.read_csv('data.csv', usecols=["列名1", "列名2", ....])
output
num1 num2
0 1 2
1 6 12
2 11 13
3 12 10
除了指定列名之外,也可以通过索引来选择想要的列,示例代码如下
df = pd.read_csv("data.csv", usecols = [0, 1, 2])
output
num1 num2 num3
0 1 2 3
1 6 12 7
2 11 13 15
3 12 10 16
另外usecols参数还有一个比较好玩的地方在于它能够接收一个函数,将列名作为参数传递到该函数中调用,要是满足条件的,就选中该列,反之则不选择该列
# 选择列名的长度大于 4 的列
pd.read_csv('girl.csv', usecols=lambda x: len(x) > 4)
- prefix: 当导入的数据没有header的时候,可以用来给列名添加前缀
df = pd.read_csv("data.csv", header = None)
output
0 1 2 3
0 num1 num2 num3 num4
1 1 2 3 4
2 6 12 7 9
3 11 13 15 18
4 12 10 16 18
如果我们将header设为None,pandas则会自动生成表头0, 1, 2, 3…, 然后我们设置prefix参数为表头添加前缀
df = pd.read_csv("data.csv", prefix="test_", header = None)
output
test_0 test_1 test_2 test_3
0 num1 num2 num3 num4
1 1 2 3 4
2 6 12 7 9
3 11 13 15 18
4 12 10 16 18
- skiprows: 过滤掉哪些行,参数当中填行的索引
代码如下:
df = pd.read_csv("data.csv", skiprows=[0, 1])
output
6 12 7 9
0 11 13 15 18
1 12 10 16 18
上面的代码过滤掉了前两行的数据,直接将第三行与第四行的数据输出,当然我们也可以看到第二行的数据被当成是了表头
- nrows: 该参数设置一次性读入的文件行数,对于读取大文件时非常有用,比如 16G 内存的PC无法容纳几百G的大文件
代码如下:
df = pd.read_csv(&#以上是关于这可能是最全的总结了,详解 20 个 pandas 读与写函数的主要内容,如果未能解决你的问题,请参考以下文章