InnoDB存储引擎相关问题整理
Posted 默辨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了InnoDB存储引擎相关问题整理相关的知识,希望对你有一定的参考价值。
一、为什么mysql要使用InnoDB做为其存储引擎
1、解释InnoDB存储引擎的底层结构为B+树的特点
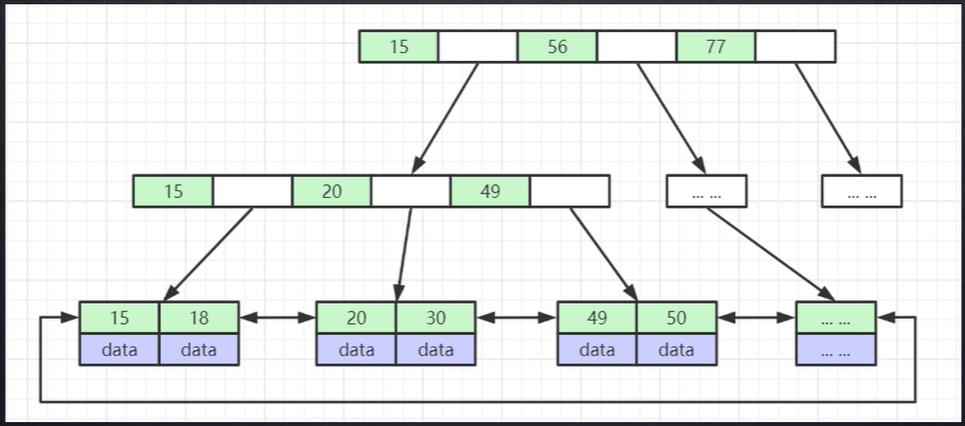
1、B+树的基本数据结构:B+树为有序数组链表+平衡多叉树(解释)
2、B+树的数据结构是怎样:
- 根节点存索引;
- 叶子节点存索引和数据;
- 所有的数据都存放在叶子节点上;
- 子节点一定包含其对应父节点的所有信息;
- 叶子节点之间有一个单向链表进行连接(但是InnoDB底层对B+树进行了改进,使用双向链表进行连接)
- …
2、引出B树,并且分别解释两种数据结构的差异及优缺点
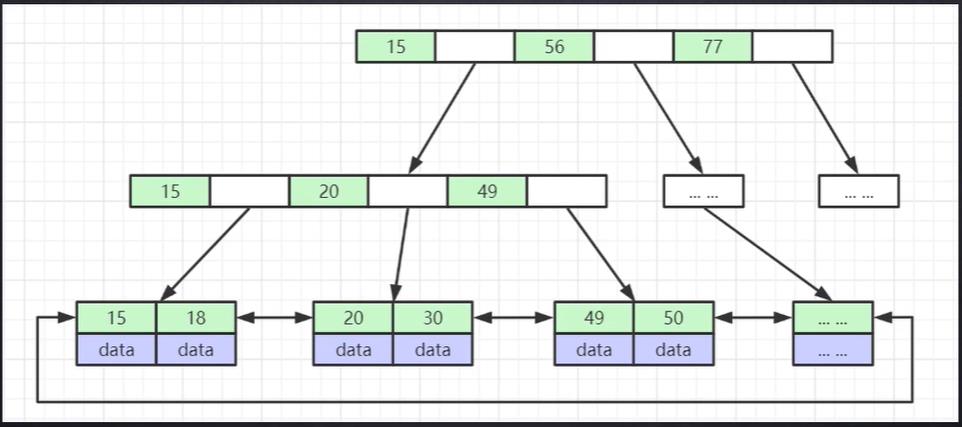
1、B树的基本数据结构:B树为有序数组+平衡多叉树(解释)
2、B树的数据结构:
- 每一层级的节点都分别包含了索引和数据
3、差异:
- B树的叶子节点没有链表
- B树的子节点不含有父节点的所有数据
- B树的父节点含有data数据
- …
4、优缺点
- B+树有链表方便排序,范围查找可以不用进行磁盘IO
- B树父节点同时含有索引和数据,会影响树的高度:磁盘加载是以块为单位进行,每一个节点变大了,那么一块里面的节点就会变少,同样的数据,树的高度就会更高
- B树是可以出现只进行一次磁盘IO就定位到数据的情况,但是B+树一定会进行多次磁盘IO,直至遍历到叶子节点
- …
二、为什么InnoDB表必须要有主键,且建议使用整形的自增主键
1、如果InnoDB表没有主键,但由于其需要通过B+树构建对应的数据结构,所以InnoDB存储引擎会看表是否有主键,如果有就用用户自己定义的主键索引来构建索引树,如果没有那么就会自己去创建一个隐藏列,用来构建对应的B+树索引结构
2、如果主键不自增(hash、uuid),构建的B+树索引结构会随时进行大的变动。因为B+树本质是有序树,无序的id会让树的索引结构发生数据节点转移
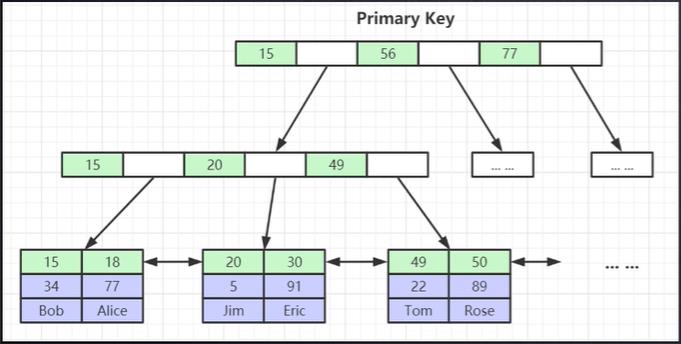
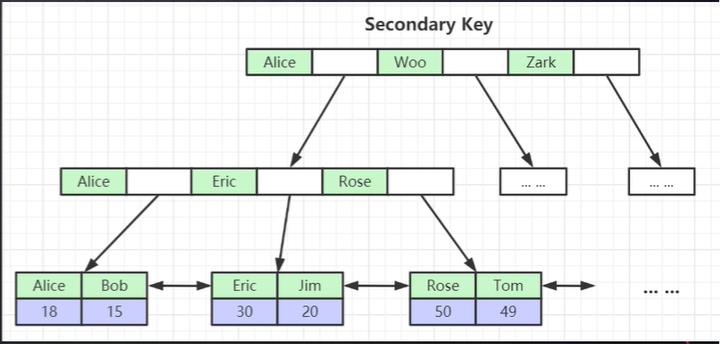
三、聚簇索引和非聚簇索引
1、聚簇索引可以理解为主键索引(Primary Key),即唯一标识一条数据的索引。如果表记录中没有主键,那么数据库会给表的每一个记录添加一个默认的隐藏id,用于构建对应的聚簇索引
2、非聚簇索引可以理解非主键索引。对于非聚簇索引,InnoDB底层也会维护一棵B+树的索引结构。当我们使用非聚簇索引(Secondary Key)列进行数据查找时,它首先会先去非聚簇索引的索引树上查找,最终会定位到非聚簇索引上的叶子节点。非聚簇索引对应的叶子节点存储的数据为对应数据库表维护的聚簇索引(主键id)。然后根据聚簇索引的值在聚簇索引维护的索引树上进行data数据的定位,即回表查。最终得到我们想要的数据。
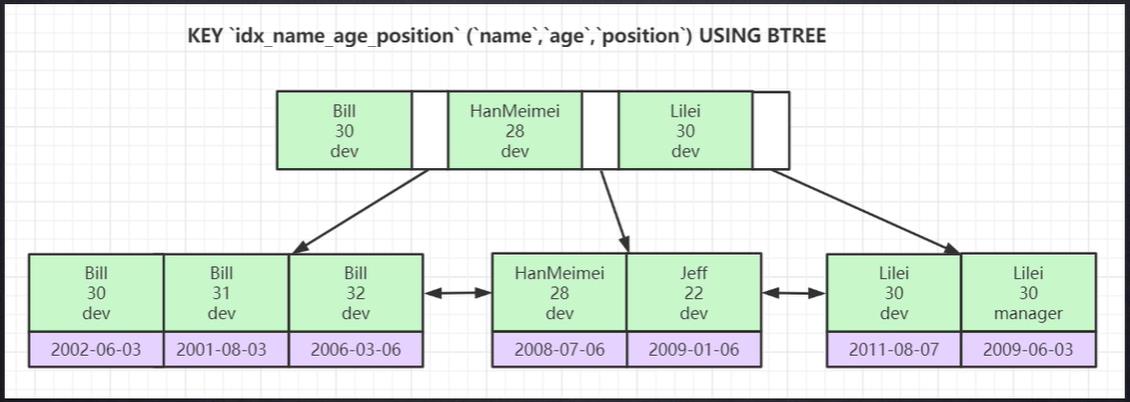
四、联合索引
1、如果联合索引是聚簇索引(主键索引),那么对应的叶子节点就是完整的data数据
2、如果联合索引是非聚簇索引(非主键索引),那么对应的叶子节点就是主键索引值,想要定位到完成的data数据,还需要去聚簇索引维护的索引树上查询数据
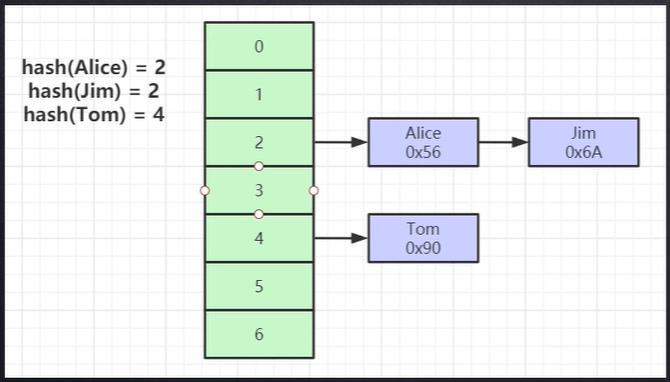
五、Hash索引
构建的索引树类比HashMap的结构进行理解,查询的效率极高,但是无法进行范围比较。不适合做主键索引,适合用作没有范围查找的数据列,即适用于IN、=,不适用于<、>
以上是关于InnoDB存储引擎相关问题整理的主要内容,如果未能解决你的问题,请参考以下文章