特征点检测目标检测交并比非最大值抑制锚框YOLO算法候选区域
Posted 劳埃德·福杰
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了特征点检测目标检测交并比非最大值抑制锚框YOLO算法候选区域相关的知识,希望对你有一定的参考价值。
1.特征点检测(Landmark detection)
如果要做一个人脸识别的基本构造模块。

首先需要选择一些特征点,帮助定义脸部轮廓、眼睛位置等脸部特征,假设选定64个特征点。
然后将人脸图片送进卷积网络中训练,网络输出为:这64个特征点的位置+是否有人脸标记(0或1)。
2.目标检测(object detection)
目标检测包括定位和分类两步。
比如下图想检测汽车,假设最后一层输出四个类别的概率,pedestrian、car、motorcycle、background。
为该监督学习任务定义目标标签(target label):y=[








:是否有任何物体(取值为0或1),、、分别表示各个类别的概率。
如何通过卷积网络进行对象检测?
采用基于滑动窗口的目标检测算法。
首先,将识别汽车的卷积网络训练好。

然后,选定某一个大小的窗口,以固定步幅滑动窗口,遍历图像的每个区域。将遍历过程中剪切的小图像输入上面训练好的卷积网络,分别按照0或1进行分类。
如果检测不到,就不断扩大滑动的窗口,重复上述步骤,总能检测到目标对象(如果确实有的话)。

如果你把滑动窗口截取的图像一个个送进网络,计算成本太高。
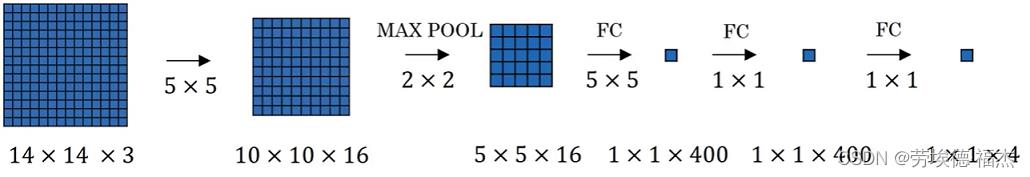
把整张图片输入给卷积网络进行计算,可以减少计算成本,因为有太多重复的计算。不需要把输入图片分割成4个子集,分别执行向前传播。
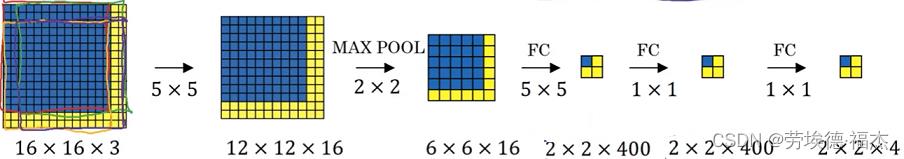
3.更精准的边界框(more accurate bounding boxes)
有时候用滑动窗口无法精确定位目标。那么,如何得到更精准的边界框 ?
yolo算法将输入图像用网格进行分割,每一个格子的图片在训练的时候对应一个标签y。
目标对象的中点在哪个格子,就属于哪个格子。

4.交并比(IoU,intersection over union)
交并比:预测边界框和实际边界框的交集和并集之比,用于衡量定位精度的。一般IoU>=0.5,预测边界框就算正确。

5.非最大值抑制(non-max suppression)
非最大值抑制:保证算法对每个目标对象只检测输出一次。
举例解释:如果想要检测车的位置。如下图,将图片分割成19x19的格子,这361个格子都会执行图像检测的算法。显然,车会覆盖很多格子,最后可能输出多个检测的边界框。如右图。
为了使只有一个边界框作出有车的预测,计算每个边界框的IoU,IoU最大的边界框作出有车的预测,其它IoU较小的就被"抑制"了,被清理掉。

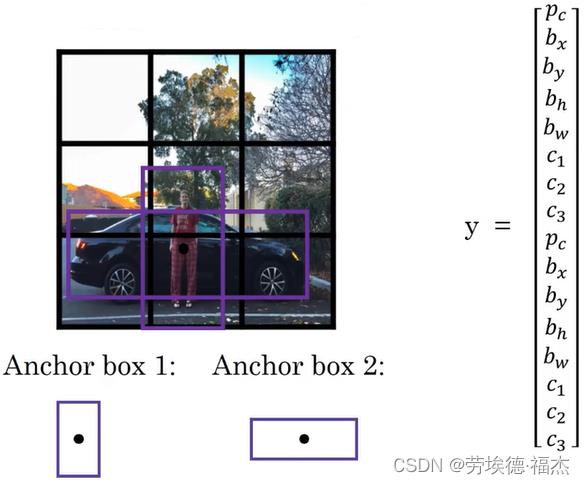
6.锚框(Anchor boxes)
如何让一个格子检测出多个目标对象?
如下图,人和车的中点都落在一个格子里。预先定义两个不同形状的Anchor box,定义标签y。
分别计算预测目标的边界框和这两个Anchor box的IoU,选择最大的那个,即给目标对象既分配一个格子,也分配一个Anchor box。
7.YOLO算法(you only look once)
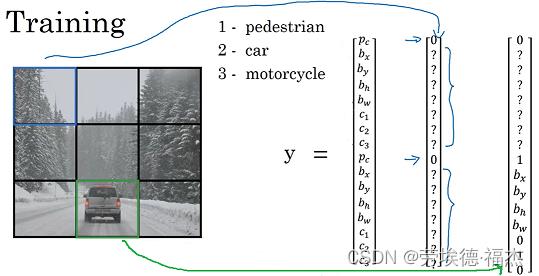
训练
假设使用3x3的网格。识别3个物体(行人、汽车、摩托车)。两个anchor box,分别对应行人和汽车。单个格子的图片对应的标签y有16位(c1,c2,c3表示识别为这3个类别的概率,两个分别表示是不是行人、是不是汽车)。整个图片送进卷积网络,输出尺寸为3x3x16。
8.候选区域(Region proposals)
R-CNN:带区域的CNN,仅选择图像上的某些区域,运行卷积网络分类器。毕竟有些区域只有背景不含目标对象,没必要也把它送进网络中去预测。
我们利用图像分割算法(segmentation algorithm)去找出可能存在对象的区域。

在此基础上的改进算法:Fast R-CNN、Faster R-CNN
以上是关于特征点检测目标检测交并比非最大值抑制锚框YOLO算法候选区域的主要内容,如果未能解决你的问题,请参考以下文章