大数据计算 Storm的安装和基础编程
Posted 小生凡一
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据计算 Storm的安装和基础编程相关的知识,希望对你有一定的参考价值。
1. 安装zookeeper
- 下载

- 解压并重命名
tar -zxvf apache-zookeeper-3.7.0-bin.tar.gz
sudo mv apache-zookeeper-3.7.0-bin zookeeper

- 配置文件
进入conf文件
cd conf

cp zoo_sample.cfg zoo.cfg
填入一下配置信息
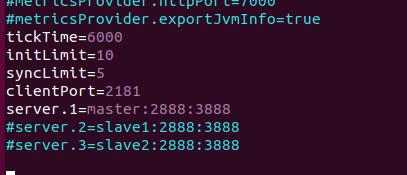
注意该文件夹下的datadir这个路径

记住这个datadir路径,保存退出
然后我们打开这个 /tmp/zookeeper 路径,我们要在这个目录下创建myid文件

保存退出即可
- 修改权限
修改tmp

修改zookeeper

启动集群
bin/zkServer.sh start
- 连接测试
bin/zkCli.sh -server 127.0.0.1:2181

这样即可
2. 安装storm
2.1 安装libzmq3
- 安装
libzmq3-dev

2.2 安装jzmq包
- 解压jzmq包

unzip jzmq-master.zip
- 进入配置文件的文件夹中

下面下载的东西如果缺什么就安装什么即可!
./autogen.sh
./configure
make
sudo make install
比如

就

可能会遇到安装python的情况,直接
sudo apt-get install python
这里是会安装2.7版本的,就用这个就行了
2.3 安装storm集群
- 下载

- 解压
tar -zxvf apache-storm-2.3.0.tar.gz

- 配置storm.yaml文件

- 配置如下
注意192.168.168.129换成你自己的ip地址。可以ifconfig查看自己的ip地址

- 用户权限分配

- 启动storm集群
启动nimbus
./bin/storm nimbus &

启动supervise
./bin/storm supervise &
启动ui
./bin/storm ui

- 打开网址

看到这个即可!
以上是关于大数据计算 Storm的安装和基础编程的主要内容,如果未能解决你的问题,请参考以下文章