机器学习sklearn----支持向量机分类器SVC求解过程可视化
Posted iostreamzl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习sklearn----支持向量机分类器SVC求解过程可视化相关的知识,希望对你有一定的参考价值。
需求及思路
- 需求:画出啊决策边界和两个超平面
- 实现思路:从坐标轴上去出大量的点,将点的坐标值当作两个特征放入SVC模型中,预测每个点对应的类别。利用matplotlib中contour函数画出等高线(到决策边界距离相同的点具有相同的高度),保留[-1, 0, 1]三条。0对应决策边界,其他的两条就是两个超平面
本文代码使用到的第三方库如下
from sklearn.datasets import make_blobs, make_circles
from sklearn.svm import SVC
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
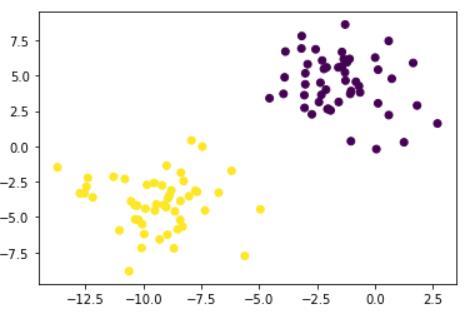
文中的使用数据集只有两个特征,一个标签,将两个特征作为横纵坐标,标签作为颜色就能画出数据的分布图了,画出分布情况的代码如下:
X, y = make_blobs(n_samples=100, n_features=2, centers=2, random_state=1, cluster_std=2)
# cluster_std 每个簇内部之间的标准差,用于控制每个簇的离散程度
# 第一个特征是横坐标,第二个特征是纵坐标
plt.scatter(X[:, 0], X[:, 1], c=y)
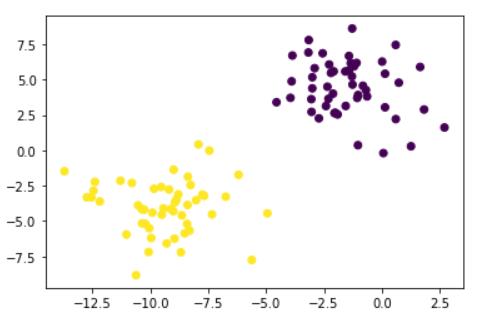
对于SVC的求解过程可以分为两种情况
-
线性数据:可以直观的找到一条直线或一个平面,将数据分开,例如下面的数据就是线性可分的
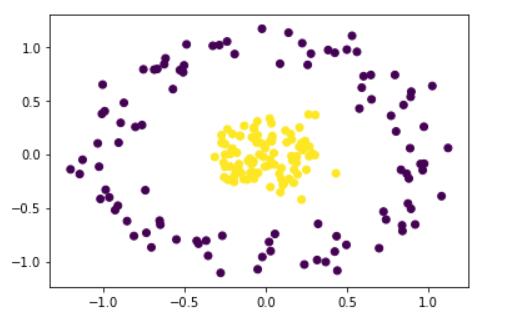
-
非线性数据:不能通过简单的直线或平面将数据分开,下面的数据就是非线性的
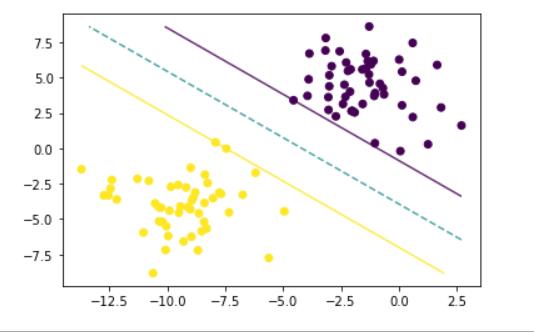
线性可分数据的SVC求解可视化
# 创建数据集
X, y = make_blobs(n_samples=100, n_features=2, centers=2, random_state=1, cluster_std=2)
# cluster_std 每个簇内部之间的标准差,用于控制每个簇的离散程度
# 训练模型
svc = SVC(kernel='linear').fit(X, y)
# SCV求解可视化函数
def decision_boundary(X, y, model) :
# 取出两个坐标轴的上下限
xmin, xmax, ymin, ymax = X[:, 0].min(), X[:, 0].max(), X[:, 1].min(), X[:, 1].max()
# 坐标轴等分为50份,共可创建50x50=2500个点
xloc = np.linspace(xmin, xmax, 50)
yloc = np.linspace(ymin, ymax, 50)
# 相当于一个数据复制的作用,将shape=(n,)的数据变为shape=(n,n)
xloc, yloc = np.meshgrid(xloc, yloc)
# 组合坐标点coordinate, 将(n, n)的数据展开成(n*n, )的数据在组合为坐标
coo = np.vstack([xloc.ravel(), yloc.ravel()]).T
# 通过decision_function函数计算出每个点到决策边界的距离
dis = model.decision_function(coo)
# contour要求X,Y,Z具有相同的维度,所以需要将预测结果reshape
dis = dis.reshape(xloc.shape)
# 画出原始数据的散点图
plt.scatter(X[:, 0], X[:, 1], c=y)
# 添加决策边界和两个超平面
plt.contour(xloc, yloc, dis, alpha=.8, linestyles=['-', '--', '-'], levels=[-1, 0, 1])
plt.show()
pass
decision_boundary(X, y, svc)
非线性数据的SVC求解可视化
原始数据
X, y = make_circles(n_samples=200, factor=0.2, noise=0.1)
# factor控制连个圆的大小比例
# noise控制噪声比例
plt.scatter(X[:, 0], X[:, 1], c=y)
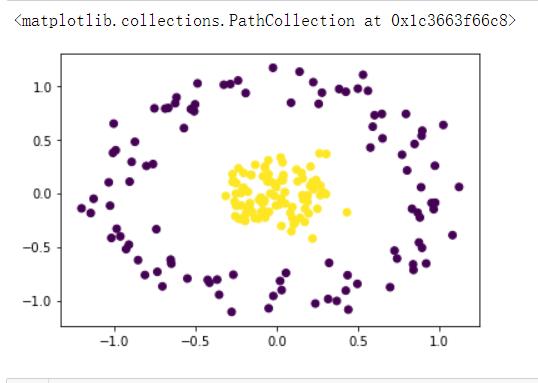
对于线性不可分的数据如果使用上面的SVC模型是画不出想要的结果的
# 对于上面的数据没有一个平面可以直接分开两类数据,这就是非线性的数据
# 调用前面的模型来看一下分类效果
svc = SVC(kernel='linear').fit(X, y)
decision_boundary(X, y, svc)
# 很明显这样的分法是不合理的
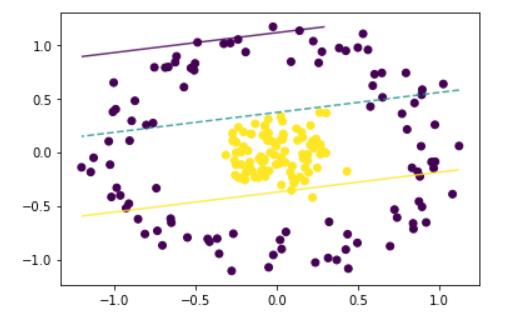
linear采用的线性的方式求解,会将决策边界想象为一条直线,然而这里的决策边界实际上是一个圆环,我们将数据投影到三维会发现决策边界是一个平面,所以在非线性的数据上表现很糟
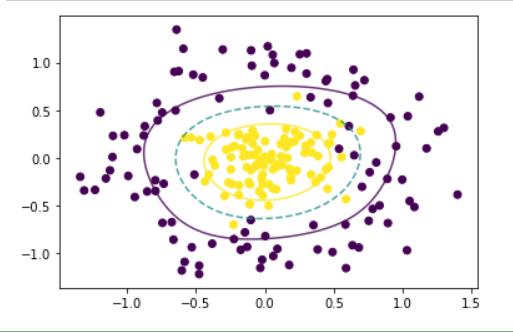
我们只需要将kernel参数的值换为非线性rbf就好了
svc_rbf = SVC(kernel='rbf').fit(X, y)
decision_boundary(X, y, svc_rbf)
利用matplotlib画出三维空间数据分布
# t通过X计算出第三个维度的数据,随便的一个计算公式即可
z = -(X**2 + 1).sum(axis=1)
def plot_3D(X, y, z, elev=30, azim=30) :
# X,y,z:原始数据
# elev: z轴的旋转角度
# azim: x轴的旋转角度
# 导入画三维图必须的依赖包
from mpl_toolkits import mplot3d
# 创建一个3d图片的画布。这里必须导入了mplot3d这个包才能创建否则会报错
ax = plt.axes(projection='3d')
# 画散点图
ax.scatter3D(X[:, 0], X[:, 1], z, c=y, s=20)
# 初始化图的展示设置
ax.view_init(elev=elev, azim=azim)
ax.set_xlabel("x")
ax.set_ylabel("y")
ax.set_zlabel('z')
plt.show()
plot_3D(X, y, z)
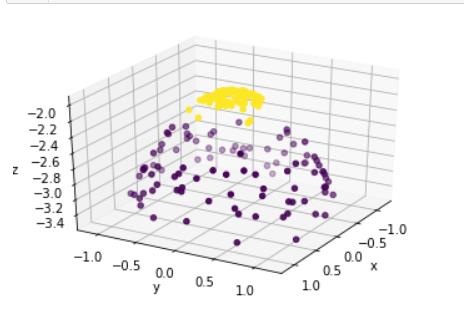
很明显决策边界是一个平面,投影到平面上就是一个圆环
以上是关于机器学习sklearn----支持向量机分类器SVC求解过程可视化的主要内容,如果未能解决你的问题,请参考以下文章