DBMS 数据库管理系统的三级模式架构《ClickHouse 实战:企业级大数据分析引擎》...
Posted 东海陈光剑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DBMS 数据库管理系统的三级模式架构《ClickHouse 实战:企业级大数据分析引擎》...相关的知识,希望对你有一定的参考价值。
引文
计算机科学领域的所有问题,都可以通过添加一层中间层来解决。通过在用户和计算机中间添加一层逻辑层(概念模型层),于是就有了“数据库的三级模式”:数据库在三个级别 (层次)上进行抽象,使用户能够逻辑地、抽象地处理数据,而不必关心数据在计算机中的物理表示和存储。 光剑,2021.

数据库简介
当今世界是一个充满着数据的互联网世界,充斥着大量的数据。即这个互联网世界就是数据世界。数据的来源有很多,比如出行记录、消费记录、浏览的网页、发送的消息等等。除了文本类型的数据,图像、音乐、声音都是数据。
数据库是一个按数据结构来存储和管理数据的计算机软件系统。数据库的概念实际包括两层意思:
(1)数据库是一个实体,它是能够合理保管数据的“仓库”,用户在该“仓库”中存放要管理的事务数据,“数据”和“库”两个概念结合成为数据库。
(2)数据库是数据管理的新方法和技术,它能更合适的组织数据、更方便的维护数据、更严密的控制数据和更有效的利用数据。
数据库是“按照数据结构来组织、存储和管理数据的仓库”。是一个长期存储在计算机内的、有组织的、可共享的、统一管理的大量数据的集合。
数据库是存放数据的仓库。它的存储空间很大,可以存放百万条、千万条、上亿条数据。但是数据库并不是随意地将数据进行存放,是有一定的规则的,否则查询的效率会很低。
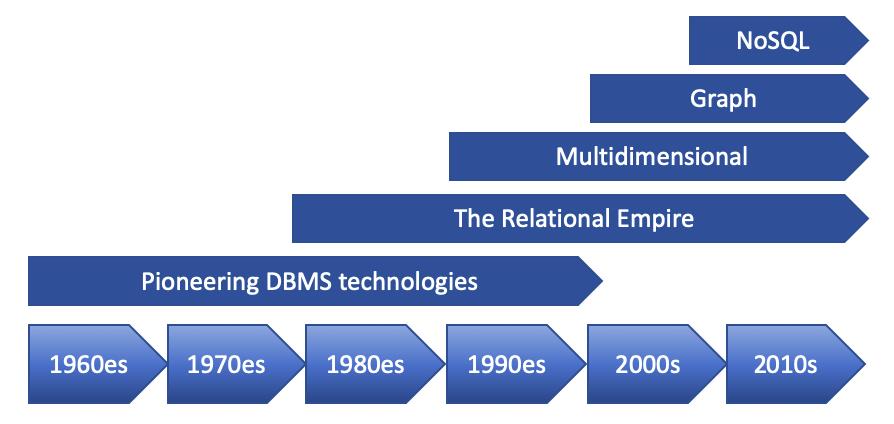
数据库发展历史
数据库的演变
数据建模和数据库一起发展,它们的历史可以追溯到 1960 年代。
数据库演变发生在五个“浪潮”中:
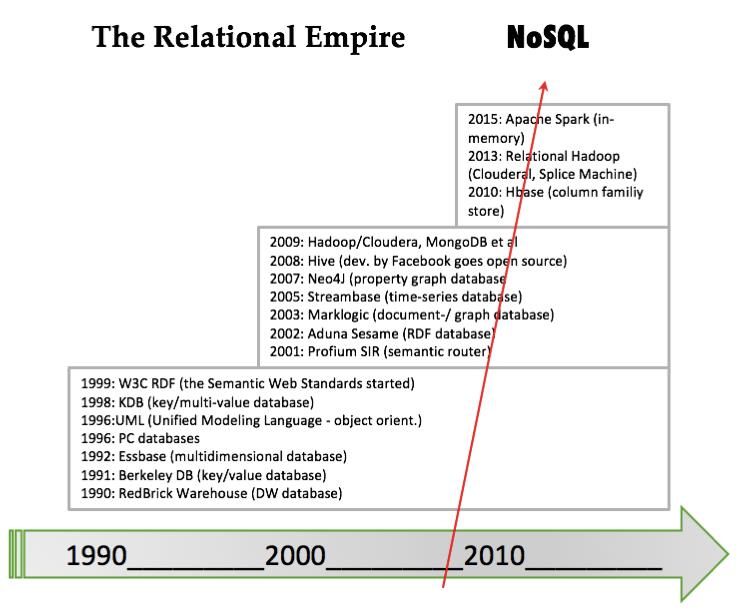
1.第一波由网络、分层、倒排列表和(在 1990 年代)面向对象的 DBMS 组成;它大约发生在 1960 年至 1999 年之间。
2.关系浪潮在 1990 年左右推出了所有 SQL 产品(以及一些非 SQL),并在 2008 年左右开始失去用户。
3.决策支持浪潮在 1990 年左右引入了在线分析处理 (OLAP) 和专门的 DBMS,并且今天仍然有效。
4.图浪潮始于 1999 年万维网联盟的语义网络堆栈,2008 年左右出现了属性图
5.NoSQL 浪潮包括大数据等等;它始于2008年。
1973 年:查尔斯·巴赫曼 (Charles Bachman) 的“作为导航员的程序员”
1981 年:E.F. (Ted) Codd : “关系数据库:生产力的实用基础”
2001 年:Ole-Johan Dahl 和 Kristen Nygaard 提出了面向对象编程出现的基本思想
2014 年:Michael Stonebraker 的 “The Land Sharkx are on the Squawk Box”。
1973: Charles Bachman with “The Programmer as Navigator”
1981: E. F. (Ted) Codd with “Relational Database: A Practical Foundation for Productivity”
2001: Ole-Johan Dahl and Kristen Nygaard for ideas fundamental to the emergence of object-oriented programming
2014: Michael Stonebraker with “The Land Sharkx are on the Squawk Box.”
在数据库的发展历史上,数据库先后经历了:
1.层次数据库
2.网状数据库
3.关系数据库
等阶段。随着云计算的发展和大数据时代的到来,关系型数据库越来越无法满足需要,这主要是由于,越来越多的半关系型和非关系型数据,需要用数据库进行存储管理。以此同时,分布式技术等新技术的出现也对数据库的技术提出了新的要求。

于是越来越多的非关系型数据库就开始出现,这类数据库与传统的关系型数据库在设计和数据结构有了很大的不同, 它们更强调数据库数据的高并发读写和存储大数据,这类数据库一般被称为NoSQL(Not only SQL)数据库。 而传统的关系型数据库在一些传统领域依然保持了强大的生命力。
关系数据库
关系型数据库,存储的格式可以直观地反映实体间的关系。关系型数据库和常见的表格比较相似,关系型数据库中表与表之间是有很多复杂的关联关系的。 常见的关系型数据库有Mysql,SqlServer等。在轻量或者小型的应用中,使用不同的关系型数据库对系统的性能影响不大,但是在构建大型应用时,则需要根据应用的业务需求和性能需求,选择合适的关系型数据库。
标准SQL语句
虽然关系型数据库有很多,但是大多数都遵循SQL(结构化查询语言,Structured Query Language)标准。 常见的操作有查询,新增,更新,删除,求和,排序等。
查询语句:SELECT param FROM table WHERE condition 该语句可以理解为从 table 中查询出满足 condition 条件的字段 param。
新增语句:INSERT INTO table (param1,param2,param3) VALUES (value1,value2,value3) 该语句可以理解为向table中的param1,param2,param3字段中分别插入value1,value2,value3。
更新语句:UPDATE table SET param=new_value WHERE condition 该语句可以理解为将满足condition条件的字段param更新为 new_value 值。
删除语句:DELETE FROM table WHERE condition 该语句可以理解为将满足condition条件的数据全部删除。
去重查询:SELECT DISTINCT param FROM table WHERE condition 该语句可以理解为从表table中查询出满足条件condition的字段param,但是param中重复的值只能出现一次。
排序查询:SELECT param FROM table WHERE condition ORDER BY param1该语句可以理解为从表table 中查询出满足condition条件的param,并且要按照param1升序的顺序进行排序。
总体来说, 数据库的SELECT,INSERT,UPDATE,DELETE对应了我们常用的增删改查四种操作。
关系型数据库对于结构化数据的处理更合适,如学生成绩、地址等,这样的数据一般情况下需要使用结构化的查询,例如join,这样的情况下,关系型数据库就会比NoSQL数据库性能更优,而且精确度更高。由于结构化数据的规模不算太大,数据规模的增长通常也是可预期的,所以针对结构化数据使用关系型数据库更好。关系型数据库十分注意数据操作的事务性、一致性,如果对这方面的要求关系型数据库无疑可以很好的满足。
非关系型数据库(NoSQL)
随着近些年技术方向的不断拓展,大量的NoSql数据库如MongoDB、Redis、Memcache出于简化数据库结构、避免冗余、影响性能的表连接、摒弃复杂分布式的目的被设计。
NoSQL 指分布式的、非关系型的、不保证遵循ACID原则的数据存储系统。
NoSQL数据库技术与CAP理论、一致性哈希算法有密切关系。
所谓CAP理论,简单来说就是一个分布式系统不可能满足可用性、一致性与分区容错性这三个要求,一次性满足两种要求是该系统的上限。
而一致性哈希算法则指的是NoSQL数据库在应用过程中,为满足工作需求而在通常情况下产生的一种数据算法,该算法能有效解决工作方面的诸多问题但也存在弊端,即工作完成质量会随着节点的变化而产生波动,当节点过多时,相关工作结果就无法那么准确。这一问题使整个系统的工作效率受到影响,导致整个数据库系统的数据乱码与出错率大大提高,甚至会出现数据节点的内容迁移,产生错误的代码信息。
但尽管如此,NoSQL数据库技术还是具有非常明显的应用优势,如数据库结构相对简单,在大数据量下的读写性能好;能满足随时存储自定义数据格式需求,非常适用于大数据处理工作。
NoSQL数据库适合追求速度和可扩展性、业务多变的应用场景。
对于非结构化数据的处理更合适,如文章、评论。这些数据通常只用于模糊处理(全文搜索、机器学习),并不需要像结构化数据一样,进行精确查询。而且这类数据的数据规模往往是海量的,数据规模的增长往往也是不可能预期的 —— 而NoSQL数据库的扩展能力几乎也是无限的,所以NoSQL数据库可以很好的满足这一类数据的存储。NoSQL数据库利用key-value可以大量的获取大量的非结构化数据,并且数据的获取效率很高,但用它查询结构化数据效果就比较差。
目前NoSQL数据库仍然没有一个统一的标准,它现在有四种大的分类:
(1)键值对存储(key-value):代表软件Redis,它的优点能够进行数据的快速查询,而缺点是需要存储数据之间的关系。
(2)列存储:代表软件Hbase,它的优点是对数据能快速查询,数据存储的扩展性强。而缺点是数据库的功能有局限性。ClickHouse 也是列存储。
(3)文档数据库存储:代表软件MongoDB,它的优点是对数据结构要求不特别的严格。而缺点是查询性的性能不好,同时缺少一种统一查询语言。
(4)图形数据库存储:代表软件InfoGrid,它的优点可以方便的利用图结构相关算法进行计算。而缺点是要想得到结果必须进行整个图的计算,而且遇到不适合的数据模型时,图形数据库很难使用。
数据库管理系统:Database Management System
数据库管理系统(DBMS,Database Management System)是操纵和管理数据库的大型软件,用于建立、使用和维护数据库,简称DBMS。它对数据库进行统一的管理和控制,以保证数据库的安全性和完整性。大部分DBMS提供数据定义语言DDL(Data Definition Language)和数据操作语言DML(Data Manipulation Language),供用户定义数据库的模式结构与权限约束,实现对数据的追加、删除等操作。
SQL 数据库管理软件
MySQL:最流行的开源数据库,它是基于 Web 的应用程序的领先解决方案,因为它支持 SQL 作为其数据库语言并包含与 SQL 查询相关的视图,从而可以查看数据库的特定部分.
Oracle RDBMS:领先的全球关系数据库管理系统,它实现了面向对象的特性,例如用户定义的类型、继承和多态。
PostgreSQL:对象关系数据库系统,可在所有主要操作系统上运行,并允许需要关系数据库的内部或商业 Web 开发。它包括一个关系系统目录,该目录支持每个数据库的多个模式。
MS SQL:Microsoft 开发的关系数据库管理系统,可根据其他软件应用程序的要求存储和检索数据。
MariaDB:由原始 mysql 开发人员制作的流行数据库服务器,可将数据转换为各种应用程序中的结构化信息。MariaDB 具有快速、可扩展和强大的存储引擎、插件和其他工具组合,旨在提供 SQL 接口来访问数据。
SQLite:广泛使用的 C 语言库,它实现了 SQL 数据库引擎,内置于所有手机和大多数计算机中。
DATAPINE:帮助用户探索、可视化和共享数据的商业智能软件。它有助于从多个现有数据库、外部应用程序和 Excel 数据创建数据库。
DbVisualizer:适用于所有主要数据库的数据库管理和分析工具。借助拖放功能,它可以促进数据库的开发、分析和管理。
RazorSQL:适用于 Windows macOS、Mac OS X、Linux 和 Solaris 的 SQL 编辑器、SQL 查询工具、数据库查询工具和数据库管理工具,使用户能够浏览数据库对象并管理数据库。
NoSQL 数据库管理软件
Redis:开源的内存数据结构存储,用作数据库、缓存和消息代理,支持字符串、哈希、列表、集合、位图、地理空间索引、流等数据结构。
MongoDB:文档数据库,将数据存储在灵活的类似 JSON 的文档中,以映射对象并简化数据管理。它的核心是一个具有高可用性、水平扩展和地理分布的分布式数据库。
GraphQL:用于 API 的开源查询和操作语言,还可用作运行时以使用现有数据填充查询。
Apache CouchDB:开源数据库软件,侧重于面向文档的 NoSQL 的易用性和可扩展架构。它使用 JSON 存储数据,使用 javascript 作为查询语言,使用 HTTP 作为 API。
Neo4j:用于任务关键型企业应用程序的图形数据库管理平台。它被认为是最流行的图形事务数据库之一,具有本机存储和处理功能。
内存数据库管理系统
Apache Ignite:开源分布式数据库、缓存和处理平台,可跨节点集群存储和计算大量数据。
Memcached:分布式内存缓存系统,用于加速动态数据库驱动的网站,将数据和对象缓存在 RAM 中。
基于云的数据管理系统
Amazon Relational Database:使用户能够在云中设置、操作和扩展关系数据库的 Web 服务。
Microsoft Azure SQL 数据库:支持关系数据、JSON、空间和 XML 等结构的关系数据库即服务。
Rackspace 云:云计算产品和服务的集合,例如 Web 应用程序托管、平台即服务、云存储、虚拟专用服务器、负载平衡器、数据库、备份、监控等。
SAP Cloud 平台:开放式平台即服务,提供独特的内存数据库和业务应用程序服务,为数字企业提供支持。
数据库管理的挑战
数据库管理中一些最显着的挑战是:
维护 DBMS 解决方案的硬件和软件的高成本。
DBMS 很复杂,因此需要培训和专门的内部经验资源。
由于数据库管理系统提供集中式解决方案,任何故障或数据损坏都可能影响整个数据库。
如果多个用户同时访问同一个程序,则存在数据丢失的风险。
在 DBMS 故障期间,可能会因忽视维护系统的最佳功能而招致重大损失。
如果数据库存储大量数据,性能可能会受到影响。
小结:数据不会消失。在数据驱动的世界中,企业需要有效处理和管理数据:能够从数据存储、数据组织、数据检索、数据分析等全方位管理数据。DBMS 使企业能够对数据进行排序、过滤、发现、定位、学习和更新,以从客户那里获取关键信息,并分析其他关键业务活动并在决策中实施这些知识。
DBMS系统的7大功能
1.数据定义:DBMS提供数据定义语言DDL(Data Definition Language),供用户定义数据库的三级模式结构、两级映像以及完整性约束和保密限制等约束。DDL主要用于建立、修改数据库的库结构。DDL所描述的库结构仅仅给出了数据库的框架,数据库的框架信息被存放在数据字典(Data Dictionary)中。
2.数据操作:DBMS提供数据操作语言DML(Data Manipulation Language),供用户实现对数据的追加、删除、更新、查询等操作。
3.数据库的运行管理:数据库的运行管理功能是DBMS的运行控制、管理功能,包括多用户环境下的并发控制、安全性检查和存取限制控制、完整性检查和执行、运行日志的组织管理、事务的管理和自动恢复,即保证事务的原子性。这些功能保证了数据库系统的正常运行。
4.数据组织、存储与管理:DBMS要分类组织、存储和管理各种数据,包括数据字典、用户数据、存取路径等,需确定以何种文件结构和存取方式在存储级上组织这些数据,如何实现数据之间的联系。数据组织和存储的基本目标是提高存储空间利用率,选择合适的存取方法提高存取效率。
5.数据库的保护:数据库中的数据是信息社会的战略资源,所以数据的保护至关重要。DBMS对数据库的保护通过4个方面来实现:数据库的恢复、数据库的并发控制、数据库的完整性控制、数据库安全性控制。DBMS的其他保护功能还有系统缓冲区的管理以及数据存储的某些自适应调节机制等。
6.数据库的维护:这一部分包括数据库的数据载入、转换、转储、数据库的重组合重构以及性能监控等功能,这些功能分别由各个使用程序来完成。
7.通信:DBMS具有与操作系统的联机处理、分时系统及远程作业输入的相关接口,负责处理数据的传送。对网络环境下的数据库系统,还应该包括DBMS与网络中其他软件系统的通信功能以及数据库之间的互操作功能。
数据库管理系统的三层模式架构:Three Level Architecture of DBMS
计算机科学领域的所有问题,都可以通过添加一层中间层来解决。通过在用户和计算机中间添加一层逻辑层(概念模型层),于是就有了“数据库的三级模式”:数据库在三个级别 (层次)上进行抽象,使用户能够逻辑地、抽象地处理数据,而不必关心数据在计算机中的物理表示和存储。
BY 光剑,2021.
例如,操作系统就是在用户跟计算机硬件之间的抽象层。
操作系统(operating system,简称OS)是管理计算机硬件与软件资源的计算机程序。操作系统需要处理如管理与配置内存、决定系统资源供需的优先次序、控制输入设备与输出设备、操作网络与管理文件系统等基本事务。操作系统也提供一个让用户与系统交互的操作界面。
对于理想的层次式计算机系统体系结构来说,其之间的联系不仅仅是单向依赖性的,同时各个层级之间也要具备相互的独立性,且只能对低层次的模块和功能进行调用
数据实际上以位、数字和字符串的形式存储,但是在这个级别处理数据的多样性和复杂性是极其困难的。
Data are actually stored as bits, or numbers and strings, but it is extremely difficult to work with the variety and complexity of data at this level.
名词说明 :Schema
This is the term for a description of the data organization at some level. Each level has its own schema.
这是在某种程度上描述数据组织的术语。每个级别都有自己的模式。
We will be concerned with three forms of schemas:
1.external or user view
2.conceptual or logical
3.internal or physical
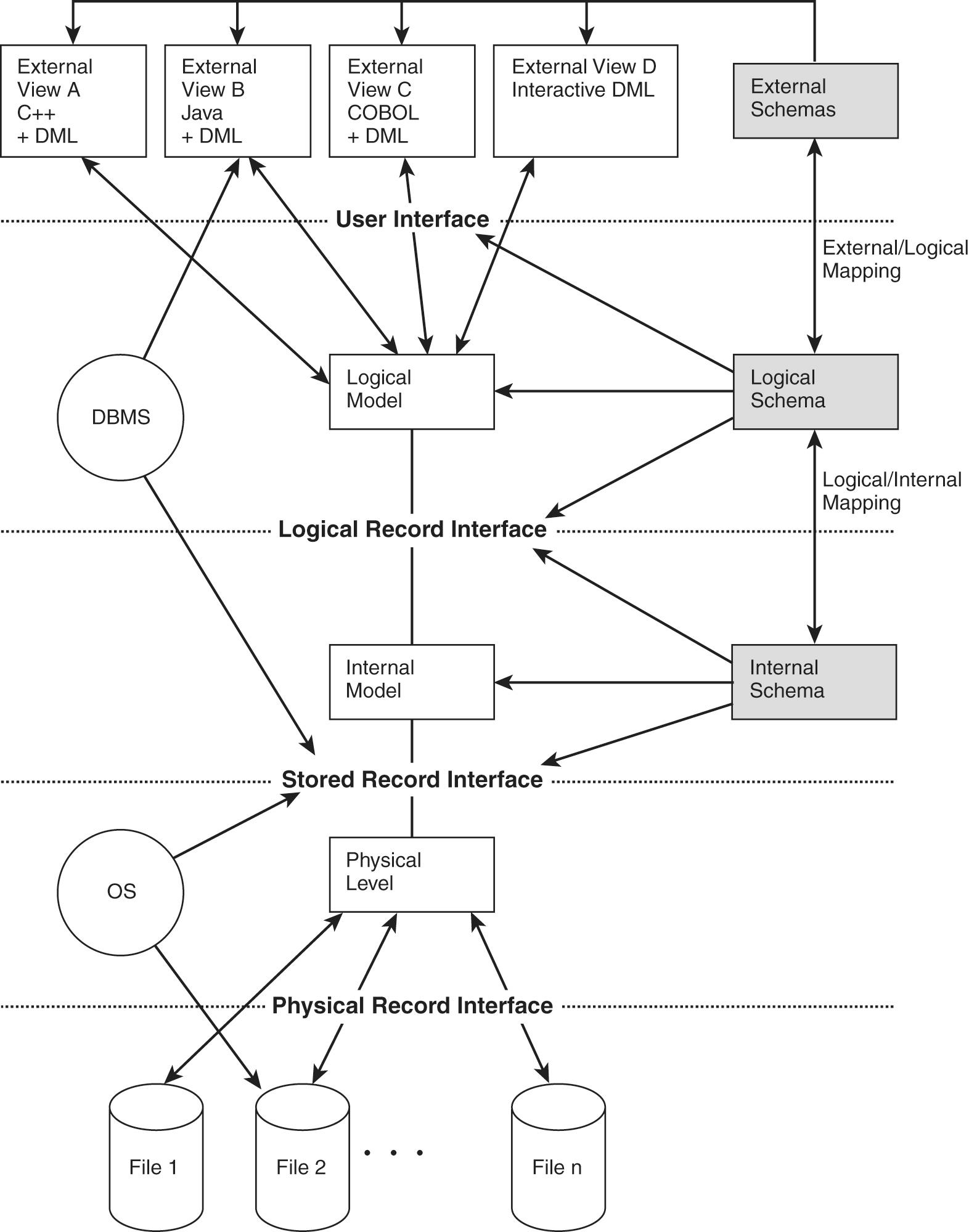
1. 外部数据层
外部模式,根据概念级别,指定数据视图。为特定用户需求量身定制。某些用户不应看到部分存储数据,权限&安全性控制。
External Data Level
An external schema specifies aviewof the data in terms of the conceptual level. It is tailored to the needs of a particular category of users. Portions of stored data should not be seen by some users and begins to implement a level of security and simplifies the view for these users.
在关系模型中,外部模式也将数据表示为一组关系。例子:
In the relational model, theexternal schemaalso presents data as a set of relations.
Examples:
学生不应该看到教职员工的工资。
教职员工不应看到帐单或付款数据。
可以从存储的数据中导出的信息可能被视为以这种方式存储。
GPA 不存储,需要时计算。
Students should not see faculty salaries.
Faculty should not see billing or payment data.
Information that can be derived from stored data might be viewed as if it were stored in that manner.
GPA not stored, calculated when needed.
应用程序是根据外部模式编写的。访问时计算外部视图。它不被存储。可以向不同类别的用户提供不同的外部模式。DBMS 在运行时,自动完成从外部级别到概念级别的转换。可以在不更改应用程序的情况下更改概念模式(改变从外部到概念的映射)——称之为“概念数据独立性”。
Applications are written in terms of an external schema. The external view is computed when accessed. It is not stored. Different external schemas can be provided to different categories of users. Translation from external level to conceptual level is done automatically by DBMS at run time. The conceptual schema can be changed without changing application:Mapping from external to conceptual must be changed. Referred to as conceptual data independence.
This is a first level of security that can be imposed on the various users of the system.
这是系统第一级安全性。
2. 概念数据层
当概念级别实现到特定数据库架构时,也称为逻辑级别。
隐藏内部/物理层的存储细节。
在关系模型中,概念模式将数据表示为一组表。
DBMS 自动将逻辑模式之间的数据访问映射到内部/物理模式。
无需更改应用程序即可更改物理/内部架构:例如,我们可以添加或删除索引,DBMS 必须将映射从概念变为物理。简称物理数据独立。
我们将使用实体关系建模将逻辑视图抽象为概念视图,实体关系建模与数据库架构无关。
Conceptual Data Level
Also referred to as the Logical level when the conceptual level is implemented to a particular database architecture.
Hides storage details of the internal/physical level.
In the relational model, the conceptual schema presents data as a set of tables.
The DBMS automatically maps data access between the logical to internal/physical schemas .
Physical/internal schema can be changed without changing application: e.g. we may add or remove an index,DBMS must change mapping from conceptual to physical.
Referred to as physical data independence.
We will abstract the logical view as a conceptual view using Entity-Relationship Modeling, which is database architecture independent.
3.内部数据层
内部层的物理模式描述了数据如何存储的细节:随机存取磁盘系统上的文件、索引等。它还通常描述文件的记录布局和文件类型(散列、b 树、平面等)。
早期的应用程序(1960 年代)仅在此级别工作 - 明确处理这些内部细节。例如,最小化相关数据之间的物理距离并组织文件内的数据结构(块记录、块链表等)
问题:
1.为了处理物理数据,程序被硬编码。
2.对数据结构的更改很难进行。
3.应用程序代码变得复杂,因为它必须处理细节。
4.新功能的快速实施非常困难。
Internal Data Level
The physical schema of the internal level describes details of how data is stored: files, indices, etc. on the random access disk system. It also typically describes the record layout of files and type of files (hash, b-tree, flat).
Early applications (1960's) only worked at this level - explicitly dealt with these internal details. E.g., minimizing physical distances between related data and organizing the data structures within the file (blocked records, linked lists of blocks, etc.)
Problem:
1.Routines are hardcoded to deal with physical representation.
2.Changes to data structures are difficult to make.
3.Application code becomes complex since it must deal with details.
4.Rapid implementation of new features very difficult.
数据建模
Schema : 某种级别的数据描述(例如,表、属性、约束、域)
模型:用于描述的工具和语言:
由数据定义语言 (DDL) 描述的概念/逻辑和外部模式
完整性约束,DDL 描述的域
数据操作语言 (DML) 描述的数据操作
影响物理模式(影响性能,而不是语义)的指令由存储定义语言 (SDL) 描述
Data Modeling
Schema: description of data at some level (e.g., tables, attributes, constraints, domains)
Model: tools and languages for describing:
Conceptual/logical and external schema described by the data definition language (DDL)
Integrity constraints, domains described by DDL
Operations on data described by the data manipulation language (DML)
Directives that influence the physical schema (affects performance, not semantics) are described by the storage definition language (SDL)
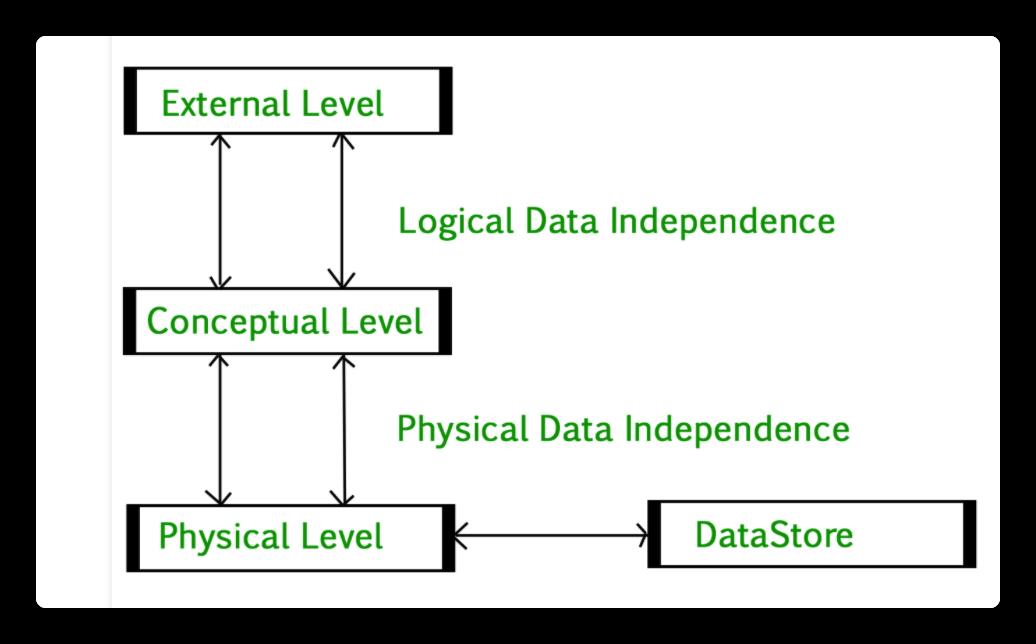
数据独立
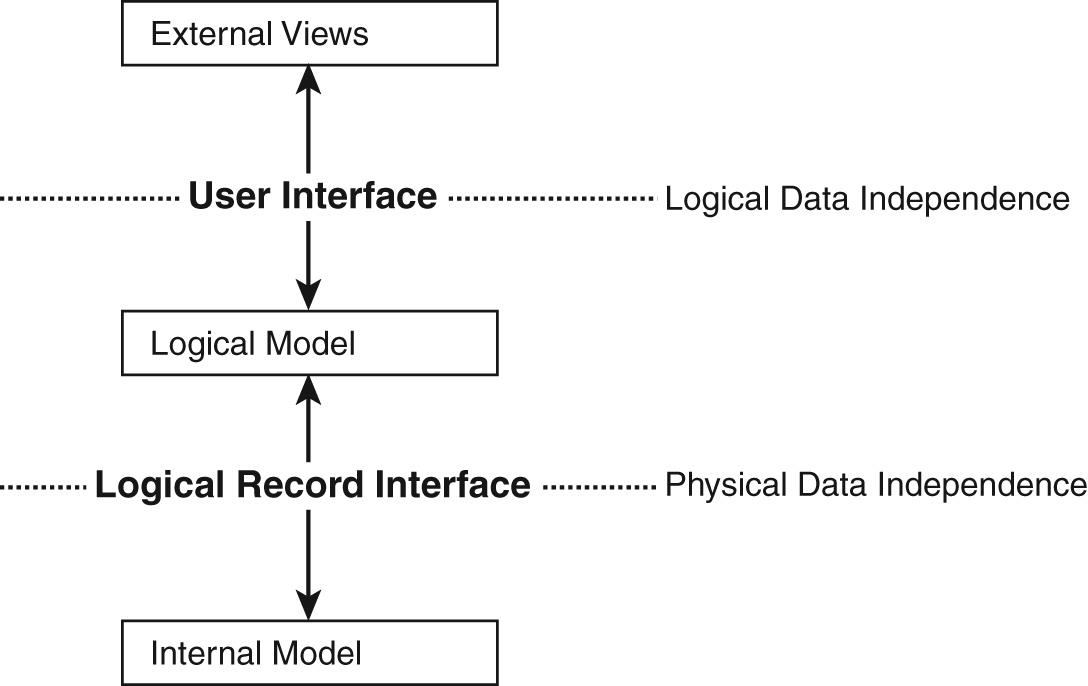
逻辑数据独立
外部模型对逻辑模型变化的免疫力
发生在用户界面级别
物理数据独立性
逻辑模型对内部模型变化的免疫力
发生在逻辑接口级别
Logical data independence
Immunity of external models to changes in the logical model
Occurs at user interface level
Physical data independence
Immunity of logical model to changes in internal model
Occurs at logical interface level
实体关系模型
语义模型捕获含义和意图
ER 建模是概念级模型
1970年代由PP Chen提出
实体是我们收集数据的现实世界对象
属性进一步描述具有特定值的实体
关系是实体之间的关联
实体集——相同类型的实体集
关系集——一组相同类型的关系
关系集也可能具有描述性属性
用ER图表示
Entity-Relationship Model
A semantic model (语义模型)captures meanings and intents
E-R modeling is a conceptual level model
Proposed by P.P. Chen in 1970s
Entities are real-world objects about which we collect data
Attributes further describe the entities with particular values
Relationships are associations among entities
Entity set – set of entities of the same type
Relationship set – set of relationships of same type
Relationships sets may also have descriptive attributes
Represented by E-R diagrams
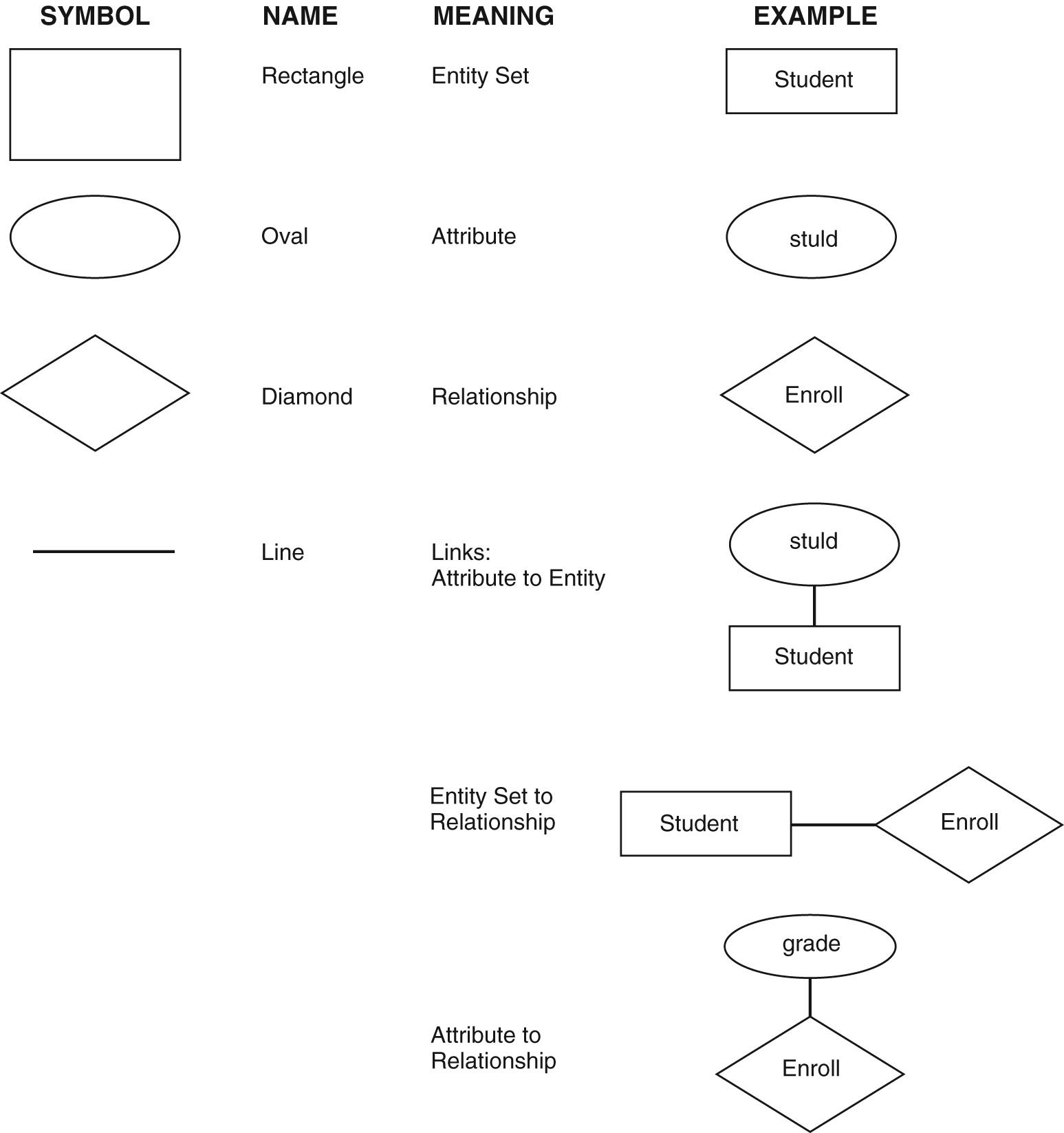
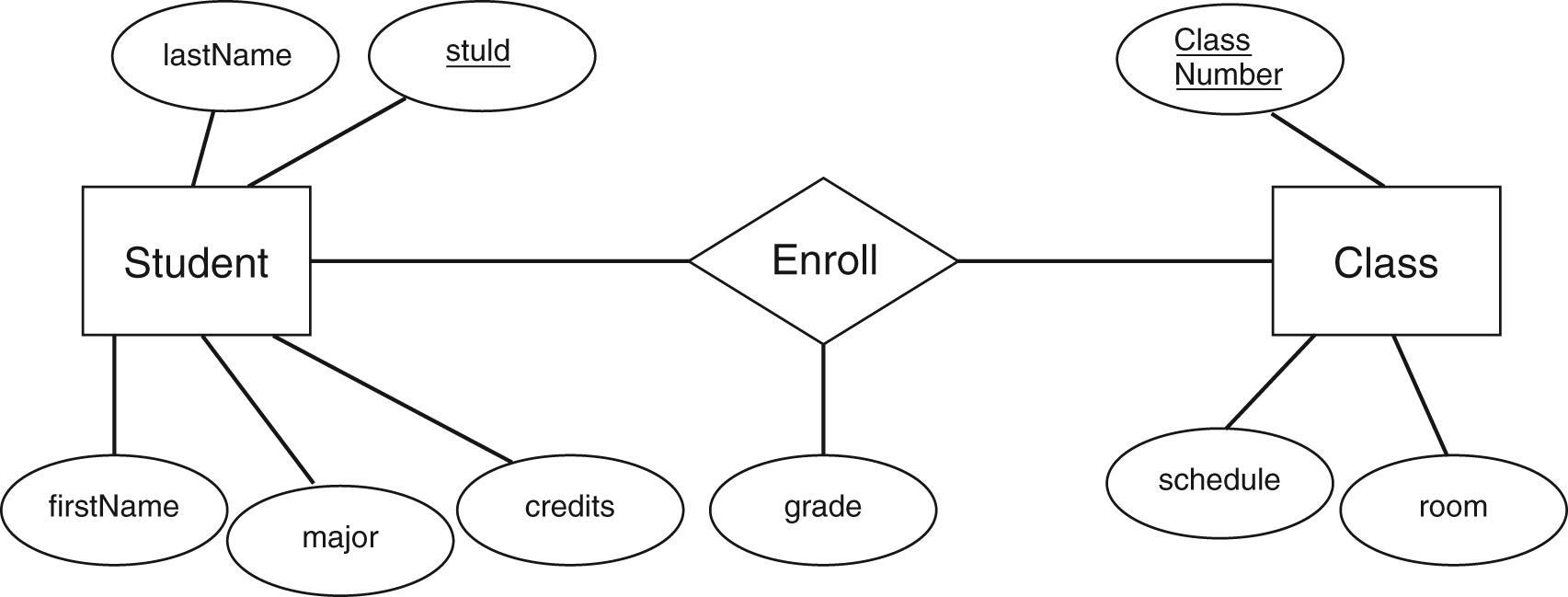
关系模型
基于记录和表的模型
关系数据库建模是一种逻辑级模型
由 EF Codd 提出
基于数学关系
使用关系,表示为表格
表格的列代表属性
表代表关系和实体
早期基于记录的模型的继承者——网络和分层
Relational Model
Record and Table based model
Relational database modeling is a logical-level model
Proposed by E.F. Codd
Based on mathematical relations(关系代数)
Uses relations, represented as tables
Columns of tables represent attributes
Tables represent relationships as well as entities
Successor to earlier record-based models—network and hierarchical
面向对象模型
使用 ER 建模作为基础,但扩展到包括封装、继承。
对象既有状态又有行为。
状态由属性定义
行为由方法(函数或过程)定义
设计器定义具有属性、方法和关系的类
类构造方法创建对象实例
每个对象都有一个唯一的对象 ID
类层次结构相关的类
数据库对象具有持久性
两个概念上的级和逻辑级模型
Object-oriented Model
Uses the E-R modeling as a basis but extended to include encapsulation, inheritance.
Objects have both state and behavior
State is defined by attributes
Behavior is defined by methods (functions or procedures)
Designer defines classes with attributes, methods, and relationships
Class constructor method creates object instances
Each object has a unique object ID
Classes related by class hierarchies
Database objects have persistence
Both conceptual-level and logical-level model
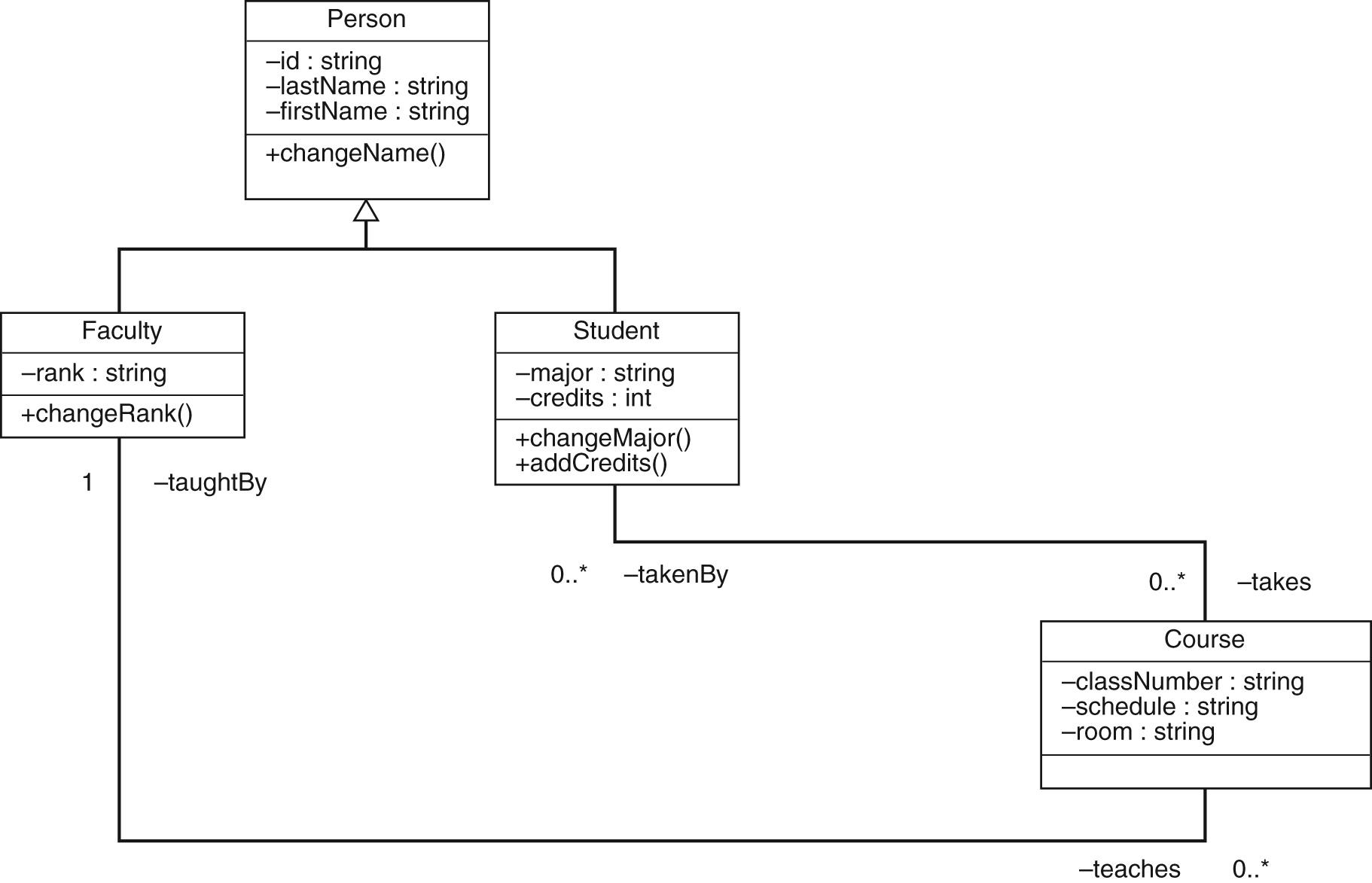
对象关系模型
向关系模型添加新的复杂数据类型
添加具有属性和方法的对象
添加继承
SQL 扩展到处理 SQL:1999 中的对象
Object-relational model
Adds new complex datatypes to relational model
Adds objects with attributes and methods
Adds inheritance
SQL extended to handle objects in SQL:1999
半结构化模型
节点的集合,每个节点都有数据和不同的模式
每个节点都包含对其自身内容的描述
可用于集成现有数据库
添加到文档的 XML 标签来描述结构
XML 标签标识文档中的元素、子元素、属性
用于定义结构的 XML DTD(文档类型定义)或 XML Schem
Semi-structured Model
Collection of nodes, each with data, and with different schemas
Each node contains a description of its own contents
Can be used for integrating existing databases
XML tags added to documents to describe structure
XML tags identify elements, sub-elements, attributes in documents
XML DTD (Document Type Definition) or XML Schema used to define structure
(Discussed later in the course in greater detail)
Phases of database design
Database designing for a real-world application starts from capturing the requirements to physical implementation using DBMS software which consists of following steps shown below:
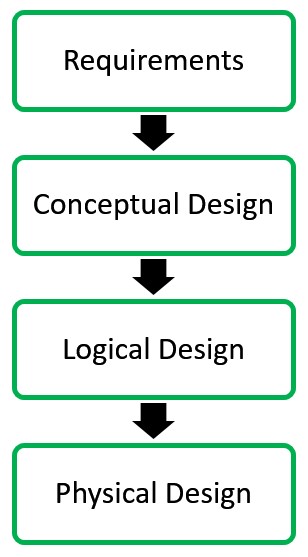
Conceptual Design: The requirements of database are captured using high level conceptual data model. For Example, the ER model is used for the conceptual design of the database.
Logical Design: Logical Design represents data in the form of relational model. ER diagram produced in the conceptual design phase is used to convert the data into the Relational Model.
Physical Design: In physical design, data in relational model is implemented using commercial DBMS like Oracle, DB2.
Advantages of DBMS
DBMS helps in efficient organization of data in database which has following advantages over typical file system:
Minimized redundancy and data inconsistency: Data is normalized in DBMS to minimize the redundancy which helps in keeping data consistent. For Example, student information can be kept at one place in DBMS and accessed by different users.This minimized redundancy is due to primary key and foreign keys
Simplified Data Access: A user need only name of the relation not exact location to access data, so the process is very simple.
Multiple data views: Different views of same data can be created to cater the needs of different users. For Example, faculty salary information can be hidden from student view of data but shown in admin view.
Data Security: Only authorized users are allowed to access the data in DBMS. Also, data can be encrypted by DBMS which makes it secure.
Concurrent access to data: Data can be accessed concurrently by different users at same time in DBMS.
Backup and Recovery mechanism: DBMS backup and recovery mechanism helps to avoid data loss and data inconsistency in case of catastrophic failures.
关系代数
关系代数是一种抽象的查询语言,用对关系的运算来表达查询,作为研究关系数据语言的数学工具。
关系代数的运算对象是关系,运算结果亦为关系。
关系代数用到的运算符包括四类:
1.集合运算符
2.关系运算符
3.算术比较符
4.逻辑运算符
比较运算符和逻辑运算符,是用来辅助专门的关系运算符进行操作的。
所以按照运算符的不同,主要将关系代数分为传统的集合运算和专门的关系运算两类。
集合运算
传统的集合运算是二目运算,包括并、交、差、广义笛卡尔积四种运算。
⒈ 并(Union)
设关系R和关系S具有相同的目n(即两个关系都有n个属性),且相应的属性取自同一个域,则关系R与关系S的并由属于R且属于S的元组组成。其结果关系仍为n目关系。记作:
R∪S=t|t∈R∨t∈S
⒉ 差(Difference)
设关系R和关系S具有相同的目n,且相应的属性取自同一个域,则关系R与关系S的差由属于R而不属于S的所有元组组成。其结果关系仍为n目关系。记作:
R - S=t|t∈R∧t∉S
⒊ 交(Intersection Referential integrity)
设关系R和关系S具有相同的目n,且相应的属性取自同一个域,则关系R与关系S的交由既属于R又属于S的元组组成。其结果关系仍为n目关系。记作:
R∩S=t|t∈R∧t∈S
⒋ 广义笛卡尔积(Extended cartesian product)
这里的笛卡尔积严格地讲是广义笛卡尔积(Extended Cartesian Product)。在不会出现混淆的情况下广义笛卡尔积也称为笛卡尔积。
两个分别为n目和m目的关系R和S的广义笛卡尔积是一个(n+m)列的元组的集合。元组的前n列是关系R的一个元组,后m列是关系S的一个元组。若R有k1个元组,S有k2个元组,则关系R和关系S的广义笛卡尔积有k1×k2个元组。
记作:
R×S=(t_r, t_s ) |t_r∈R,t_s∈S
专门的关系运算
专门的关系运算(Specific relation operations)包括:选择、投影、连接、除等。
为了叙述上的方便,我们先引入几个记号。
1. 设关系模式为 R(A1, A2, …, An)。它的一个关系设为R。t∈R表示t是R的一个元组。t[Ai]则表示元组t中相应于属性Ai的一个分量 。
2. 若A=Ai1, Ai2, …, Aik,其中Ai1, Ai2, …, Aik是A1, A2, …, An中的一部分,则A称为属性列或域列。フA则表示A1, A2, …, An中去掉Ai1, Ai2, …, Aik后剩余的属性组。t[A]=(t[Ai1], t[Ai2], …, t[Aik])表示元组t在属性列A上诸分量的集合。
3. R为n目关系,S为m目关系。设tr∈R(r为下标),ts∈S(s为下标),则trts(整个式子上方加一个半弧,r和s为下标) 称为元组的连接(Concatenation)。它是一个(n+m)列的元组,前n个分量为R中的一个n元组,后m个分量为S中的一个m元组。
4. 给定一个关系R(X,Z),X和Z为属性组。我们定义,当t[X]=x时,x在R中的象集(Images Set)为:
Zx=t[Z]|t∈R, t[X]=x
x在R中的像集为R中Z属性对应分量的集合,而这些分量所对应的元组中的属性组X上的值为x。
例如,x_1在R中的像集Z_(x_1 )=Z_1,Z_2,Z_3,Z_4, x_2在R中的像集Z_(x_2 )=Z_2,Z_3,x_3在R中的像集Z_(x_3 )=Z_1,Z_3。
X1Z1
X1Z2
X1Z3
X1Z4
X2Z2
X2Z3
X3Z1
X3Z3
1. 选择(Selection)
选择又称为限制(Restriction)。它是在关系R中选择满足给定条件的诸元组,记作:
σF(R) = t|t∈R ∧ F(t)='真'
其中F表示选择条件,它是一个逻辑表达式,取逻辑值‘真’或‘假’。
逻辑表达式F的基本形式为:
X1 θ Y1 [ φ X2 θ Y2 ]
θ表示比较运算符,它可以是>、≥、<、≤、=或≠。X1、Y1等是属性名或常量或简单函数。属性名也可以用它的序号来代替。φ表示逻辑运算符,它可以是フ、∧或∨。[ ]表示任选项,即[ ]中的部分可以要也可以不要,...表示上述格式可以重复下去。
因此选择运算实际上是从关系R中选取使逻辑表达式F为真的元组。这是从行的角度进行的运算。
2. 投影(Projection)
关系R上的投影是从R中选择出若干属性列组成新的关系。记作:
ΠA(R) = t[A] | t∈R
其中A为R中的属性列。
3. 连接(Join)
Join 是从两个关系的笛卡尔积中,选取属性间满足一定条件的元组。
连接运算从R和S的笛卡尔积R×S中选取(R关系)在A属性组上的值与(S关系)在B属性组上值满足比较关系θ的元组。
连接运算中有两种最为重要也最为常用的连接:
1.等值连接(Equal join)
2.自然连接(Natural join)
θ为“=”的连接运算称为等值连接。它是从关系R与S的笛卡尔积中选取A、B属性值相等的那些元组。
自然连接(Natural join)是一种特殊的等值连接,它要求两个关系中进行比较的分量必须是相同的属性组,并且要在结果中把重复的属性去掉。
一般的连接操作是从行的角度进行运算。但自然连接还需要取消了重复列,所以是同时从行和列的角度进行运算。
4. 除(Division)
除法运算是一个复合的二目运算。如果把笛卡尔积看作“乘法”运算,则除法运算可以看作这个“乘法”的逆运算。
给定关系R(X,Y)和S(Y,Z),其中X、Y、Z为属性组。R中的Y与S中的Y可以有不同的属性名,但必须出自相同的域集。R与S的除运算得到一个新的关系P(X),P是R中满足下列条件的元组在X属性列上的投影:元组在X上的分量值x的像集YX包含S在Y上投影的集合。记作:
R÷S=t_r [X]|t_r∈R, π_r(S)Y_x
其中,Y_x 为 x在R中的像集,x=t_r [X]。显然,除操作是同时从行和列的角度进行运算。
根据关系运算的除法定义,可以得出它的运算步骤。
(1) 将被除关系的属性分为像集属性和结果属性两部分;与除关系相同的属性属于像集属性;不相同的属性属于结果属性。
(2) 在除关系中,对像集属性投影,得到除目标数据集。
(3) 将被除关系分组。分组原则是:结果属性值一样的元组分为一组。
(4) 逐一考察每个组,如果它的像集属性值中包括目标数据集,则对应的结果属性应属于该除法运算结果集。
番外篇
历史小传:美国国家标准协会(American National Standard Institute, ANSI)的数据库管理系统研究小组于1978年提出了标准化的建议,将数据库结构分为3级:
1.面向用户或应用程序员的用户级、
2.面向建立和维护数据库人员的概念级、
3.面向系统程序员的物理级。
Database 3-Level Architecture: Three Schema Architecture of DBMS
The three schema architecture describes how the data is represented or viewed by the user in the database. This architecture is also known as three-level architecture and is sometimes called