[Python系列-26]:importlib - 动态导入其他python模块库
Posted 文火冰糖的硅基工坊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[Python系列-26]:importlib - 动态导入其他python模块库相关的知识,希望对你有一定的参考价值。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/121777798
目录
第1章 模块导入概述
1.1 概述
以文件的方式组织各种程序是大多数编程语言组织工程文件的方式。
因此,我们经常需要动态的导入存放在其他文件中的python程序。
模块导入允许我们将一个个独立的程序功能分别实现,然后组合成一个复杂的系统。
1.2 模块的作用
(1)代码重用
可以多次重用模块代码。
(2)避免变量名的冲突
每个模块都将变量名封装进了自己包含的软件包,这可以避免变量名的冲突。
(3)便于组织大规模的工程文件
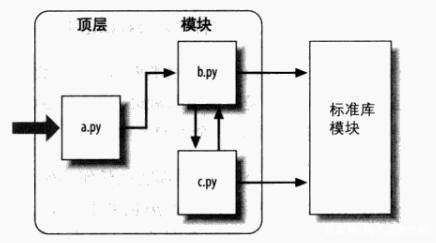
第2章 导入其他模块程序的方式
2.1 import 文件名
(1)导入库的方法
import time import torch
这种方式与C语言的include类似,导入其他模块的python程序,并生成一个同名的名字空间。
也可以在一行内导入多个模块:
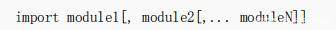
(2)Import as语句
“as”的作用是为名字空间取一个别名。
有时候你导入的模块或是模块属性名称已经在你的程序中使用了, 或者你不想使用导入的名字,或简化模块名称,可能是它太长不便输入什么的, 总之你不喜欢它。 这已经成为 Python 程序员的一个普遍需求: 使用自己想要的名字替换模块的原始名称。一个普遍的解决方案是把模块赋值给一个变量:
import numpy as np
(2)使用库的方法
# 通过多维数组构建numpy array
a = np.array([[1,2], [3,4]])
print(a)
print(a.shape)[[1 2] [3 4]] (2, 2)
# 通过多维数组构建张量
a = torch.Tensor([[1,2], [3,4]])
print(a)
print(a.shape) #tensor的维度tensor([[1., 2.],
[3., 4.]])
torch.Size([2, 2])
2. 2 from-import 语句
(1)导入
你可以在你的模块里导入指定的模块属性。 也就是把指定名称导入到当前作用域。 使用
from-import 语句可以实现我们的目的, 它的语法是:
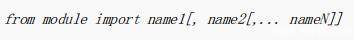
from gensim.models import Word2Vec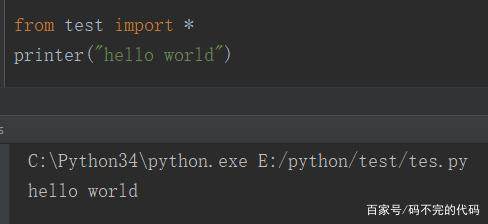
(2)使用
model = Word2Vec([raw_text], window=5, min_count=0, vector_size=100)(3)缺点
在实践中, "from module import *" 不是良好的编程风格。
如果使用from导入变量,且那些变量碰巧和作用域中现有变量同名,那么变量名就会被悄悄覆盖掉。
使用import语句的时候就不会发生这种问题,因为我们是通过模块名才获取的变量名,像module.attr不会和现有作用域的attr冲突。
2.3 动态导入module
动态导入module有点类似window的dll库,或linux so库。
在python中,是由一个专门的importlib库文件提供这种动态导入库的功能
(1)导入该静态库
from importlib import import_module(2)使用该库动态导入其他图
可以通过字符串来导入模块,同一文件夹下字符串为模块名,不同文件夹字符串为模块的路径,并通过"."来区分目录路径:
# 导入当前目录中的子目录models中的TextRNN模块。
dl_model = import_module("models.TextRNN")(3)使用方法
# 使用动态模块dl_model中的Config类,创建config对象实例
config = dl_model.Config(dataset, embedding)备注:
dl_model中的Config是一个类,上述代码是根据类,实例化一个对象。
(4)TextRNN模块源代码
# coding: UTF-8
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class Config(object):
"""配置参数"""
def __init__(self, dataset, embedding):
self.model_name = 'TextRNN'
self.train_path = dataset + '/data/train.txt' # 训练集
self.dev_path = dataset + '/data/dev.txt' # 验证集
self.test_path = dataset + '/data/test.txt' # 测试集
self.class_list = [x.strip() for x in open(
dataset + '/data/class.txt').readlines()] # 类别名单
self.vocab_path = dataset + '/data/vocab.pkl' # 词表
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt' # 模型训练结果
self.log_path = dataset + '/log/' + self.model_name
self.embedding_pretrained = torch.tensor(
np.load(dataset + '/data/' + embedding)["embeddings"].astype('float32'))\\
if embedding != 'random' else None # 预训练词向量
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
self.dropout = 0.5 # 随机失活
self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.n_vocab = 0 # 词表大小,在运行时赋值
self.num_epochs = 10 # epoch数
self.batch_size = 128 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 1e-3 # 学习率
self.embed = self.embedding_pretrained.size(1)\\
if self.embedding_pretrained is not None else 300 # 字向量维度, 若使用了预训练词向量,则维度统一
self.hidden_size = 128 # lstm隐藏层
self.num_layers = 2 # lstm层数
'''Recurrent Neural Network for Text Classification with Multi-Task Learning'''
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
self.lstm = nn.LSTM(config.embed, config.hidden_size, config.num_layers,
bidirectional=True, batch_first=True, dropout=config.dropout)
self.fc = nn.Linear(config.hidden_size * 2, config.num_classes)
def forward(self, x):
x, _ = x
out = self.embedding(x) # [batch_size, seq_len, embeding]=[128, 32, 300]
out, _ = self.lstm(out)
out = self.fc(out[:, -1, :]) # 句子最后时刻的 hidden state
return out
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/121777798
以上是关于[Python系列-26]:importlib - 动态导入其他python模块库的主要内容,如果未能解决你的问题,请参考以下文章