ParticleSfM:Exploiting Dense Point Trajectories for Localizing Moving Cameras in the Wild——论文笔记
Posted m_buddy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ParticleSfM:Exploiting Dense Point Trajectories for Localizing Moving Cameras in the Wild——论文笔记相关的知识,希望对你有一定的参考价值。
参考代码:particle-sfm
1. 概述
介绍:基于运动恢复的重建算法其前提假设是所处的是静态场景,但在实际过程中该假设可能是不成立的,这就会导致位姿估计不准确和场景重建出错。为了处理动态场景问题,文章引入视频帧间光流信息作为输入,通过帧间光流信息构建多帧之间初始逐像素传导路径,并由这些路径通过网络推理得到场景中众多路径是否为属于运动物体,同时可以根据路径分类信息得到场景中运动目标的“分割mask”(与传统mask不一样,类似于点集的形式)。之后位姿估计和场景重建均在去除了运动目标区域(其中的像素)的基础上使用估计出的像素运动路径进行(替换了传统方案中的特征检测+匹配跟踪),从而极大提升了位姿估计和场景重建的准确性。
下图展示了文章方法得到的稠密重建结果:

2. 方法设计
2.1 整体pipeline
文章方法的整体pipeline见下图所示:
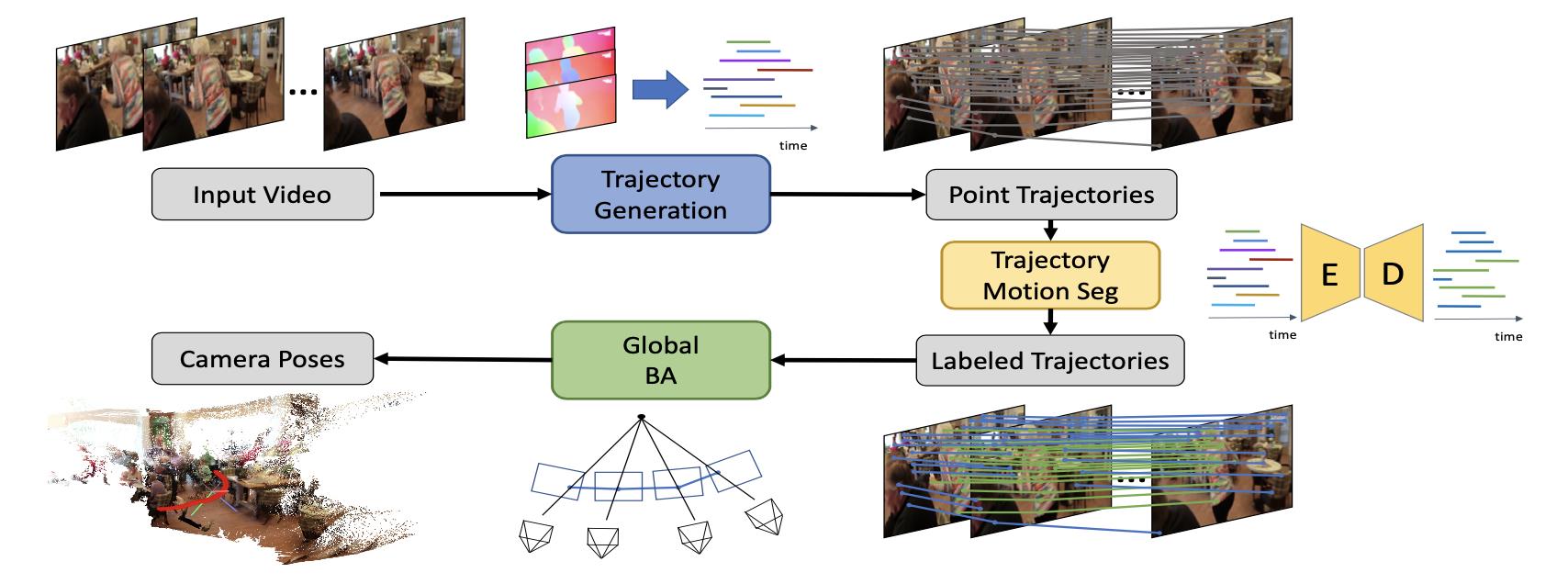
结合上图中的内容可以将完整步骤划分为:
- 1)帧间光流抽取像素运动路径:通过RAFT光流估计算法估计出帧间稠密光流信息,进而得到像素在多帧之间的转移轨迹,这些轨迹的更新与否(新的帧中像素是否加入)可通过设定的策略确定,一般为遇到遮挡不满足像素一致性假设而路径构建终止。
- 2)像素运动路径是否属于运动判定:对于抽取出的像素路径会经过统一补全之后结合深度新信息(源自与Midas深度估计网络)估计路径是否属于运动目标的分类结果。
- 3)排除运动目标进行位姿估计和场景重建:去除被路径分割网络判定为属于运动目标的像素,并用剩余的像素进行位姿估计和场景重建。
2.2 像素运动路径建立
使用RAFT光流估计算法估计帧
I
0
,
I
1
,
I
2
I_0,I_1,I_2
I0,I1,I2之间的光流
F
0
→
1
,
F
1
→
2
F_0\\rightarrow1,F_1\\rightarrow2
F0→1,F1→2,则按照光流的定义可以得到像素的传导关系:
p
1
′
=
p
0
+
F
0
→
1
(
p
0
)
,
p
2
′
=
p
1
′
+
F
1
→
2
(
p
1
′
)
p_1^'=p_0+F_0\\rightarrow1(p_0),p_2^'=p_1^'+F_1\\rightarrow2(p_1^')
p1′=p0+F0→1(p0),p2′=p1′+F1→2(p1′)
则可以根据上面像素的映射的关系(映射的误差)来判定像素迁移的路径是应该继续还是终止,为了增加时序数据的鲁棒性,文章提出了跨帧相似性的约束,也就是将像素映射的误差描述为:
L
=
(
p
1
−
p
1
′
)
2
+
(
p
2
−
(
p
0
+
F
0
→
2
(
p
0
)
)
)
2
+
(
p
2
−
(
p
1
+
F
1
→
2
(
p
1
)
)
)
2
L=(p_1-p_1^')^2+(p_2-(p_0+F_0\\rightarrow2(p_0)))^2+(p_2-(p_1+F_1\\rightarrow2(p_1)))^2
L=(p1−p1′)2+(p2−(p0+F0→2(p0)))2+(p2−(p1+F1→2(p1)))2
2.3 运动路径动静判别
在得到视频中像素的迁移路径之后,还需要判别该路径是否属于运动目标,则文章设计了一个网络用于完整这样的判定任务,其结构如下图所示:
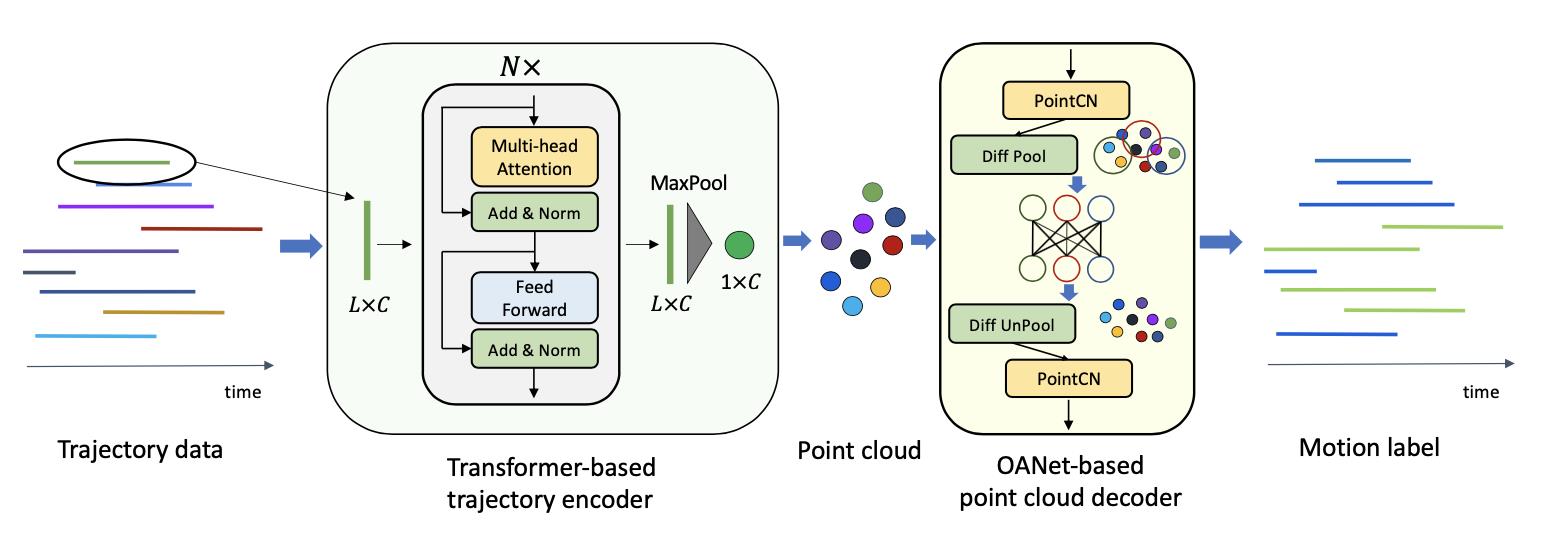
对于一个像素的迁移路径可以描述为
D
a
t
a
t
r
a
j
∈
R
N
∗
2
Data_traj\\in R^N*2
Datatraj∈RN∗2,为了送入网络方便会对它进行填补空缺值得到维度为
R
L
∗
2
R^L*2
RL∗2的数据。同时添加帧间运动感知维度的数据
(
Δ
u
i
,
Δ
v
i
)
,
i
∈
[
0
,
L
)
(\\Delta u_i,\\Delta v_i),i\\in[0,L)
(Δui,Δvi),i∈[0,L)作为额外运动信息输入。为了理解场景中的深度信息还通过Midas深度估计网络得到像素的相对深度
(
x
i
,
y
i
,
z
i
)
(x_i,y_i,z_i)
(xi,yi,zi),对应的其运动信息为
(
Δ
x
i
,
Δ
y
i
,
Δ
z
i
)
(\\Delta x_i,\\Delta y_i,\\Delta z_i)
(Δxi,Δyi,Δzi)。则送入到路径动静判别网络的数据维度是
R
L
∗
10
R^L*10
RL∗10,输出的是路径是否为运动的分类。文章的效果与其它一些运动分析方法进行比较,效果见下图所示:

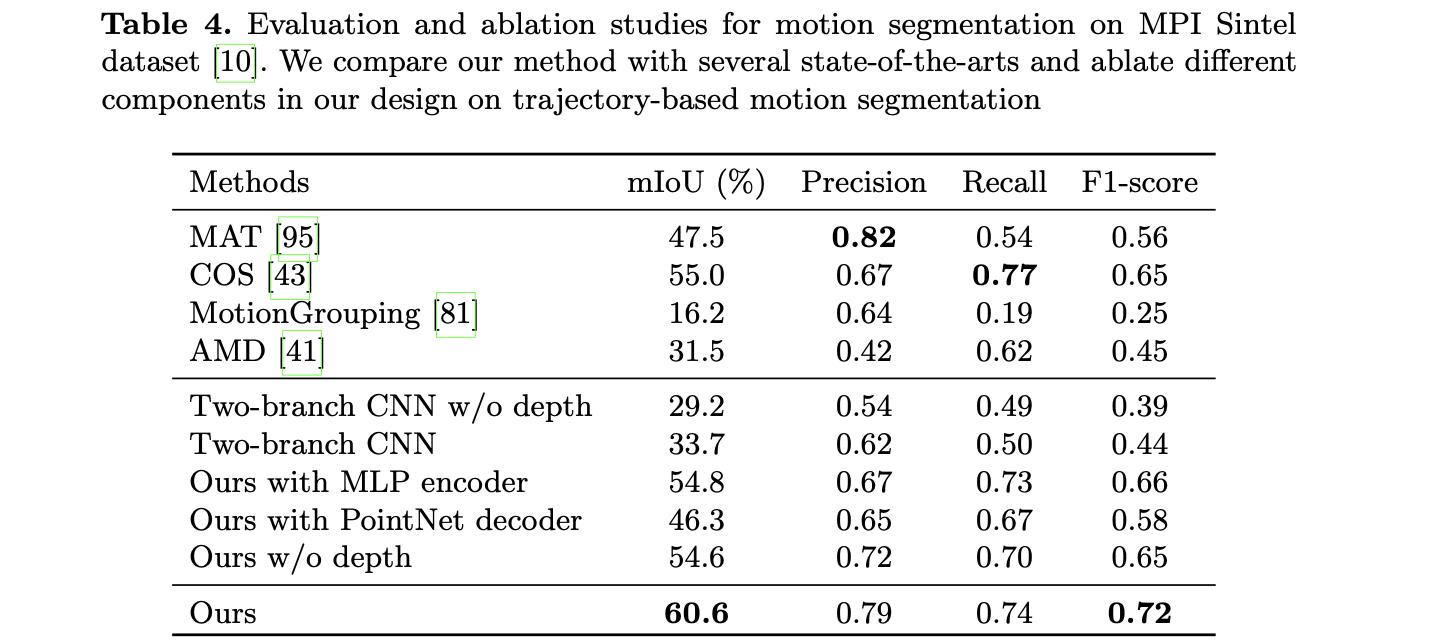
文中一些变量对于动静路径分割性能,见下表消融实验:
2.3 位姿估计与场景重建
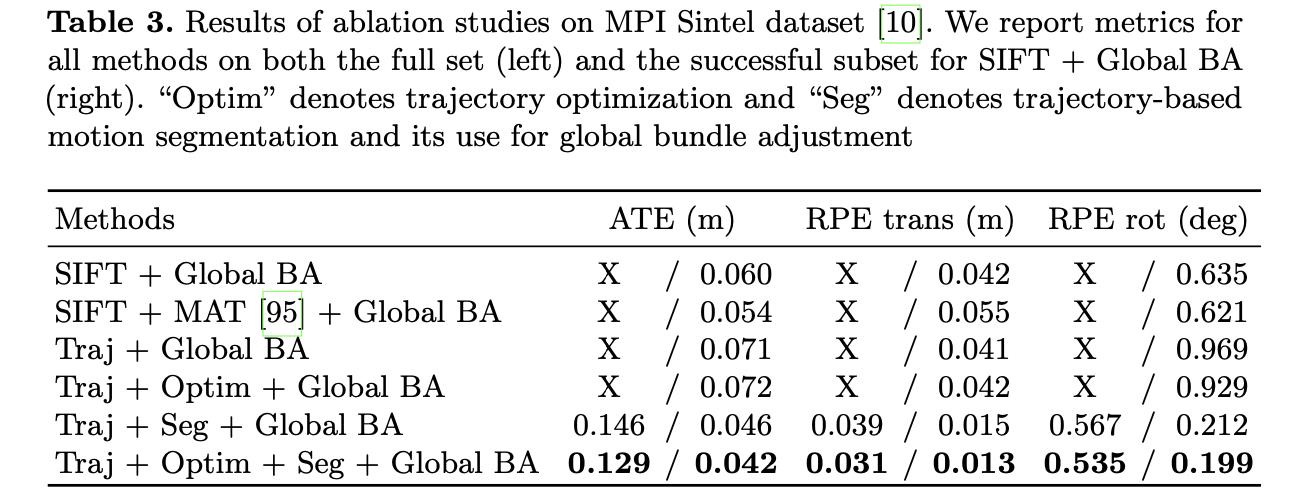
之后的工作便是去除属于运动目标的像素进行位姿估计和场景重建,需要注意是这里没有了特征点检测和匹配,直接使用像素路径进行的。文中的方法与其它一些策略在性能上的差异比较:
3. 实验结果
MPI Sintel数据集:
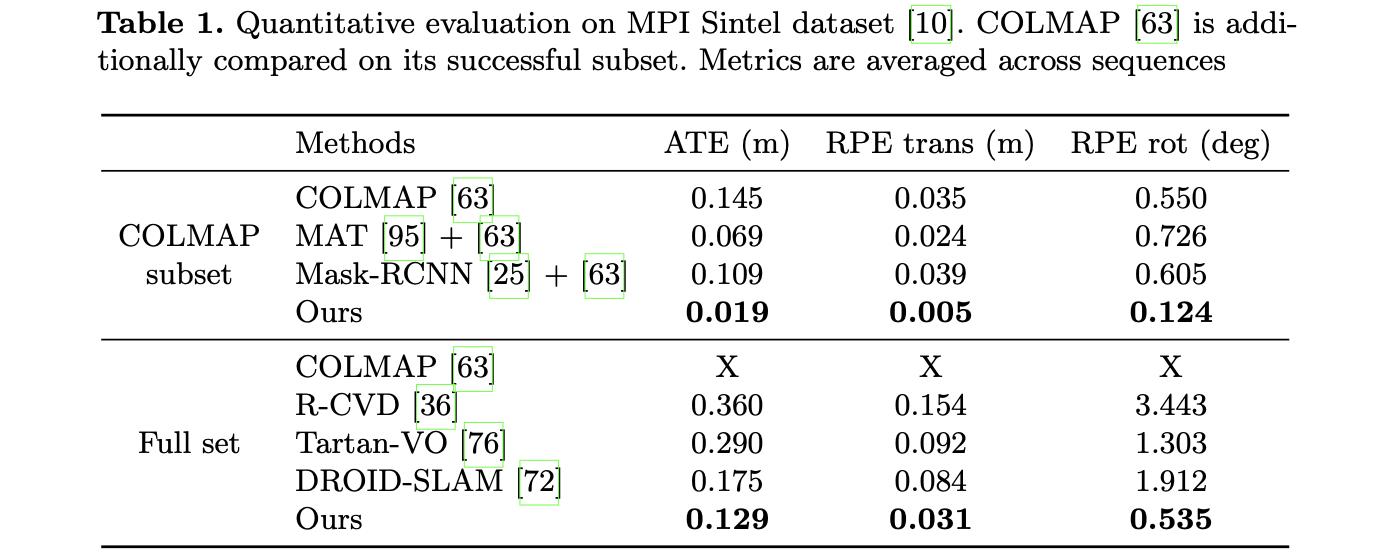
ScaneNet数据集:

以上是关于ParticleSfM:Exploiting Dense Point Trajectories for Localizing Moving Cameras in the Wild——论文笔记的主要内容,如果未能解决你的问题,请参考以下文章