爬虫模拟对“有道在线翻译”发送请求(请求中的数据含需分析js来解出变化数据)
Posted 黑马蓝汐
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫模拟对“有道在线翻译”发送请求(请求中的数据含需分析js来解出变化数据)相关的知识,希望对你有一定的参考价值。
每日分享:
做好自己
世界上没有一份工作不辛苦,也没有一处人事不复杂,无论你当下正在经历什么,都要调整好心态,继续前行,继续努力!
总有人嫌你不够好,也总有人觉得你哪里都好,爱你的人自然会爱你,不爱你的人做再多也是错。
在长大、在失去、在努力、在接受、在好好生活。
不会js也可以解出来!!!
- 分析构建data数据
- 编写代码
一、分析js构建data数据(主要讲解)
1. 在隐身窗口或无痕模式登录有道在线翻译:https://fanyi.youdao.com/
2. 抓包 -> 输入要翻译的句子
3. 再新建一个隐身窗口执行步骤2,找到translate包,观察两次的Form Data有什么不同:

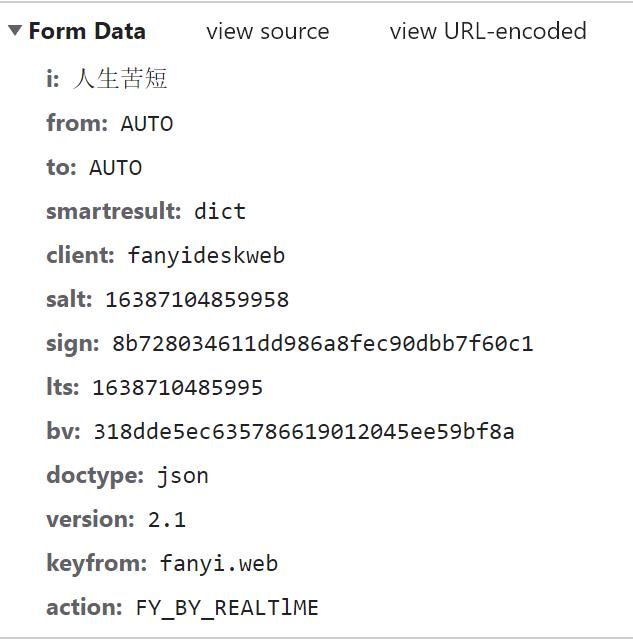
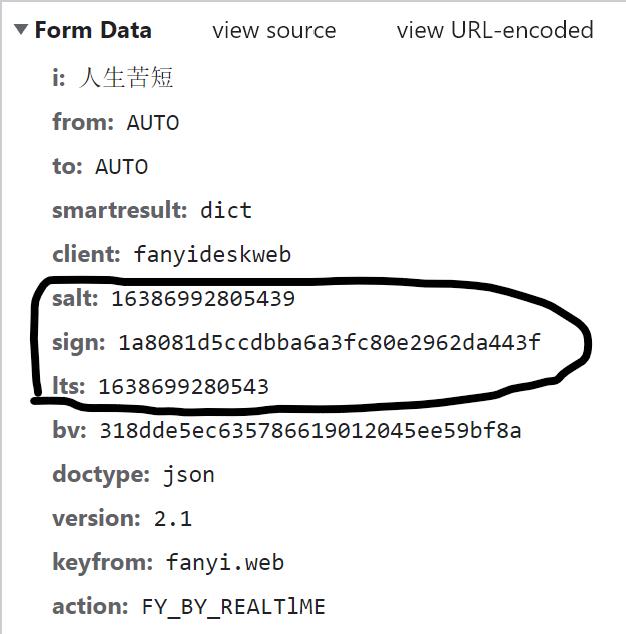
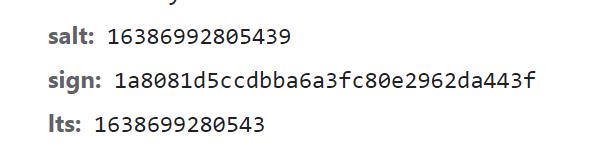
可以看到,表单中的 salt、sign、lts 这三个数据是变化的
4. 找到对应的js文件:
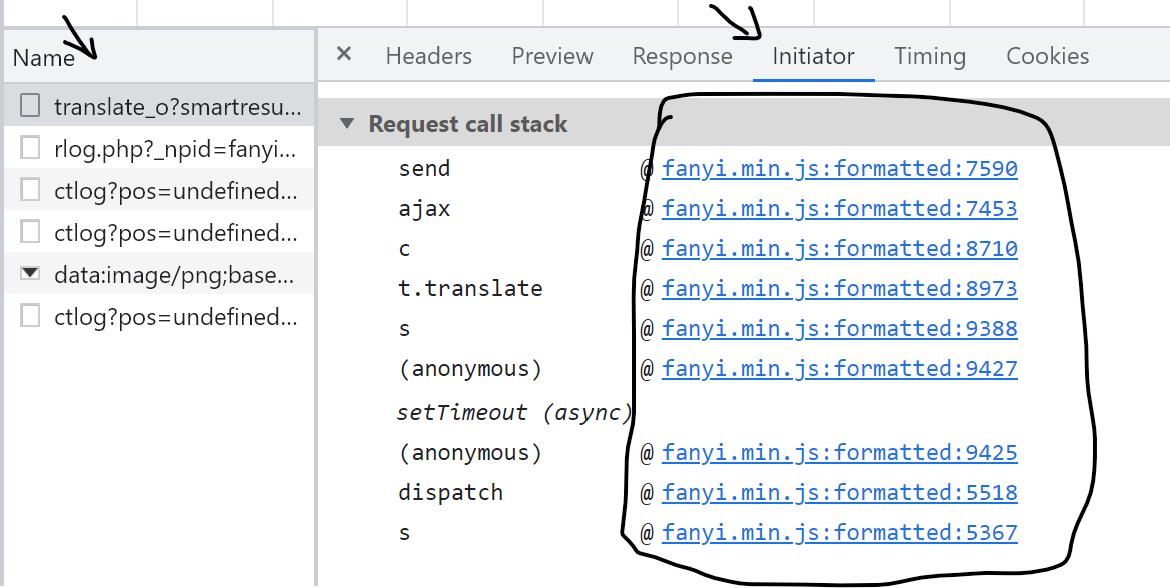
可以看到,js文件是同一个文件(后面的数字代表位置是在多少行) ,随意打开一个就行
5. 找一个Form Data中比较特殊的词,例如:smartresult(不要找像第一个数据 i ,因为 i 很可能会在js代码中出现很多次),之后直接在js代码中查找(Ctrl+f),找到如下代码:
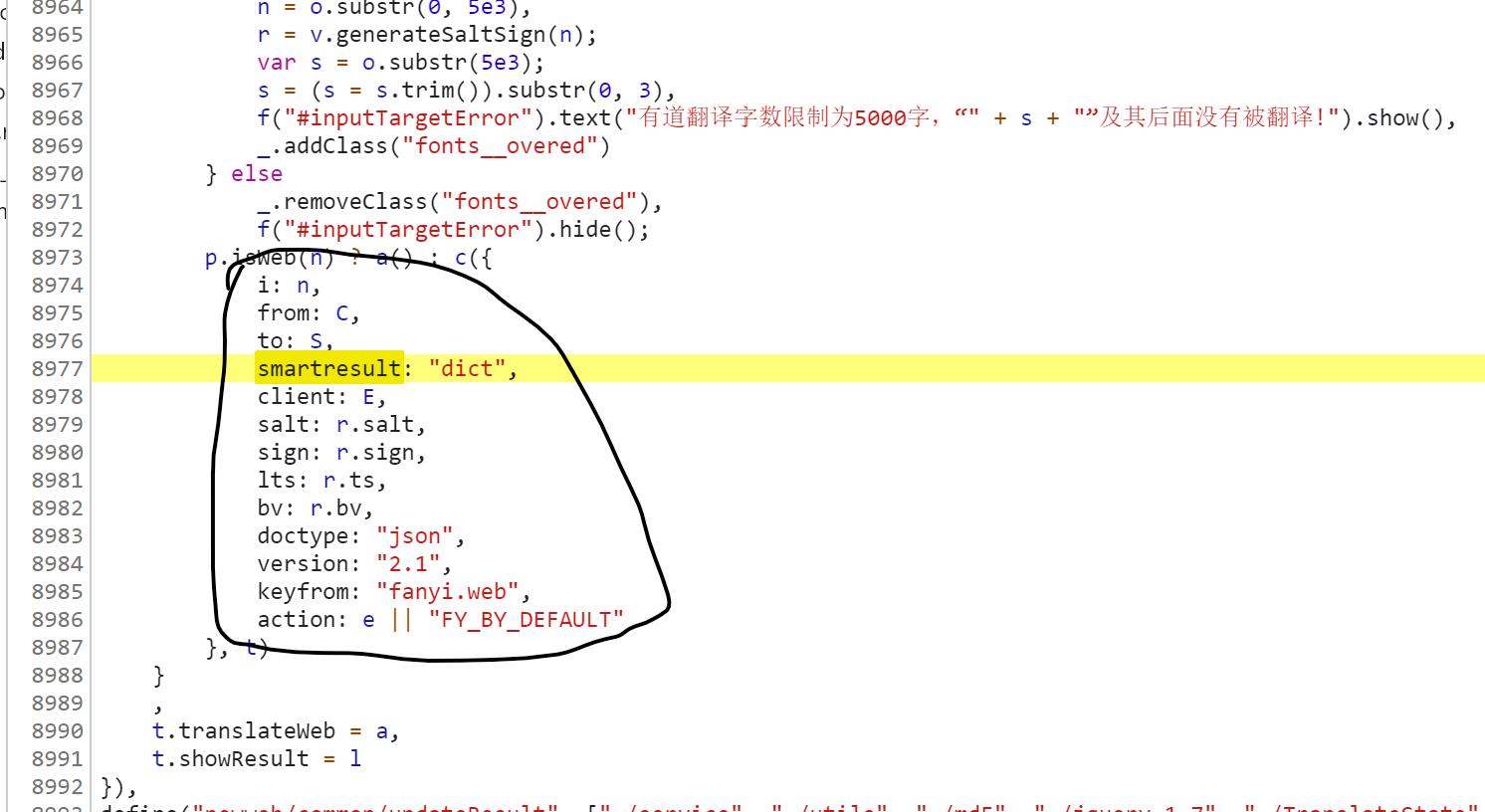
很明显可以看出,它就是js中构建Form Data的部分代码,我们可以根据它来分析 salt、sign、lts 这三个数据是如何得到的
6. 观察这三个数据,可以发现,它们都与 r 有关:
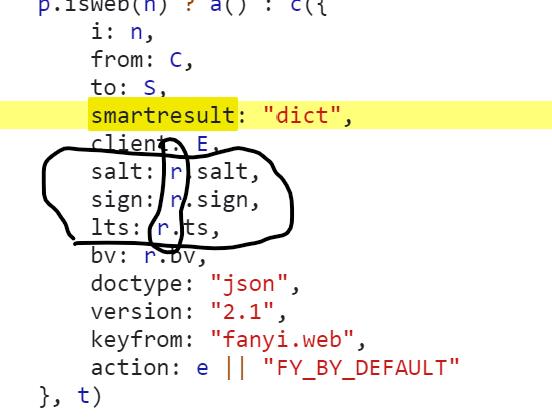
7. 之后就找 r 是什么,往上滑可以看到如下代码:
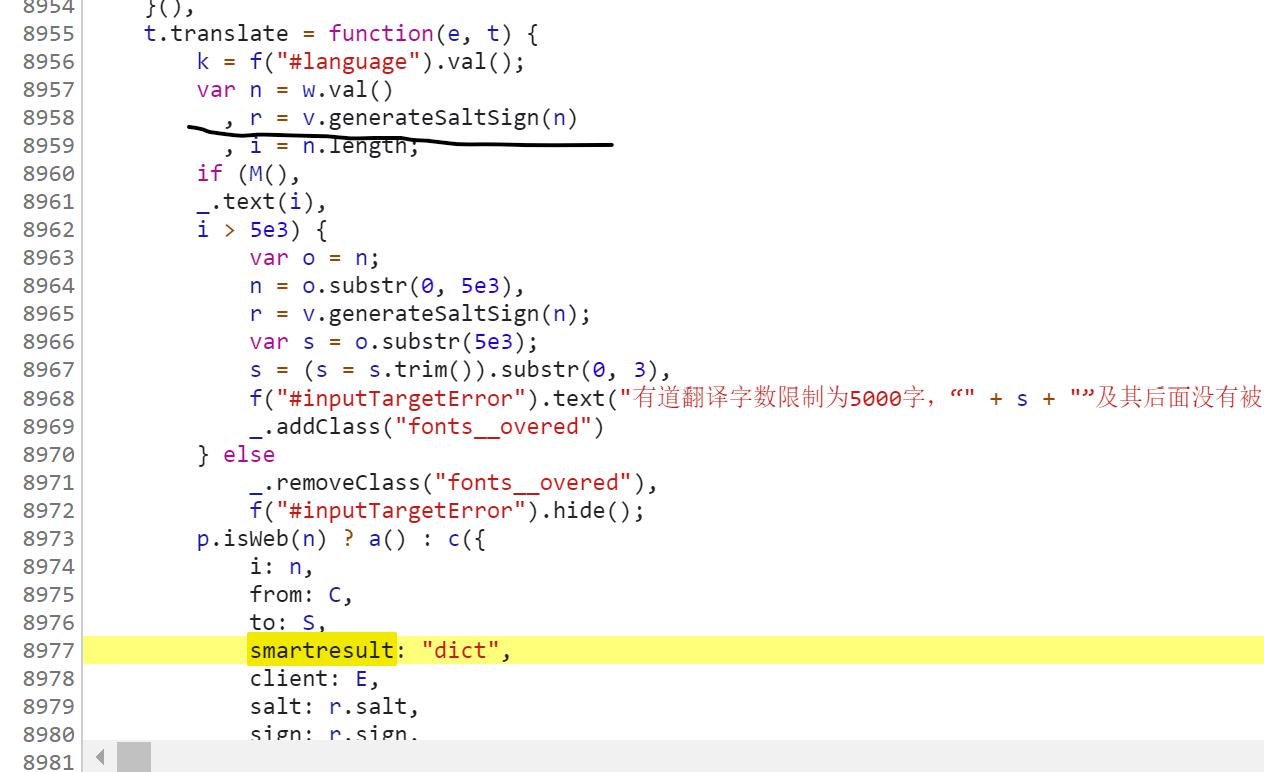
所以,r 肯定与generateSaltSign这个函数有关
8. 通过查找(Ctrl+f)generateSaltSign这个关键词,可以找到generateSaltSign函数是怎么来的(其他的地方都是调用这个函数):
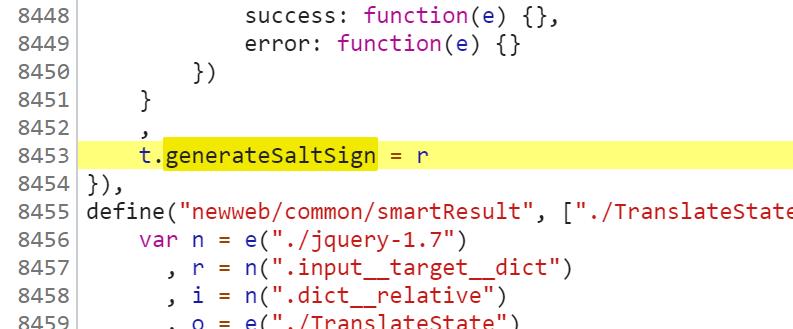
9. 我们可以发现,这行代码是把 r 的值给了generateSaltSign函数,那么说明,在这个大括号里(这一块代码)肯定有 r 的值,因此就在大括号中找 r 即可:
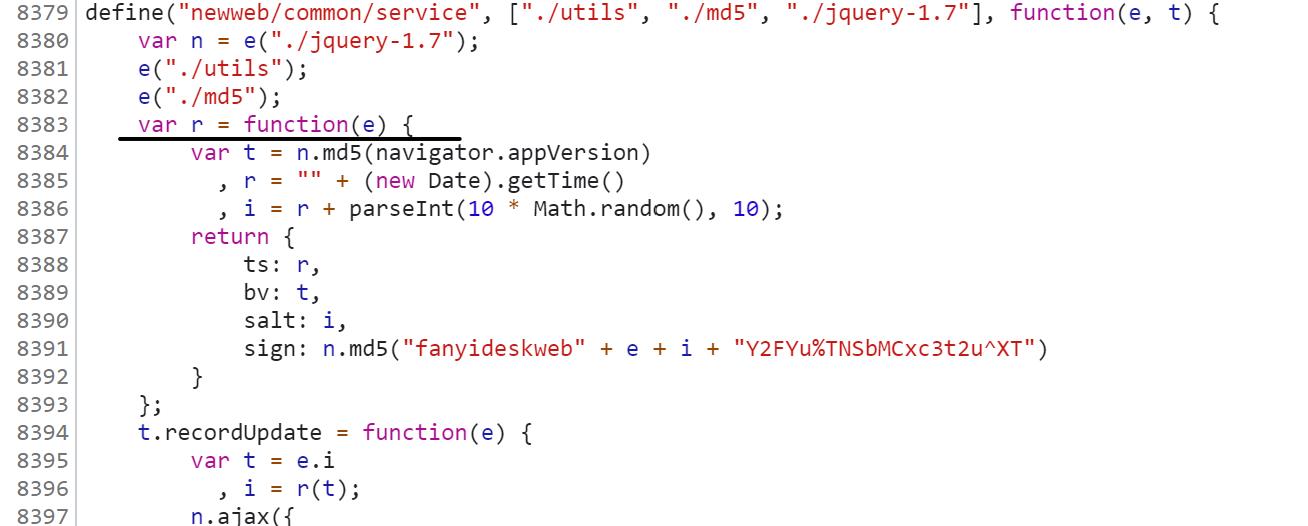
可以看出,划线代码就是 r 的定义
10. 可以在 r 的定义中找到 salt、sign、lts 这三个变化参数的来源:
lts:其实lts就是代码中的ts:
看lts的值:1638699280543,看到这一串数字要想到“时间戳”(也就是时间)
ts的值是 r 的值,而 r = "" + (new Date).getTime(),没学过js看不懂也没关系,我们可以复制这个语句:(new Date).getTime(),在如下图输入js代码:
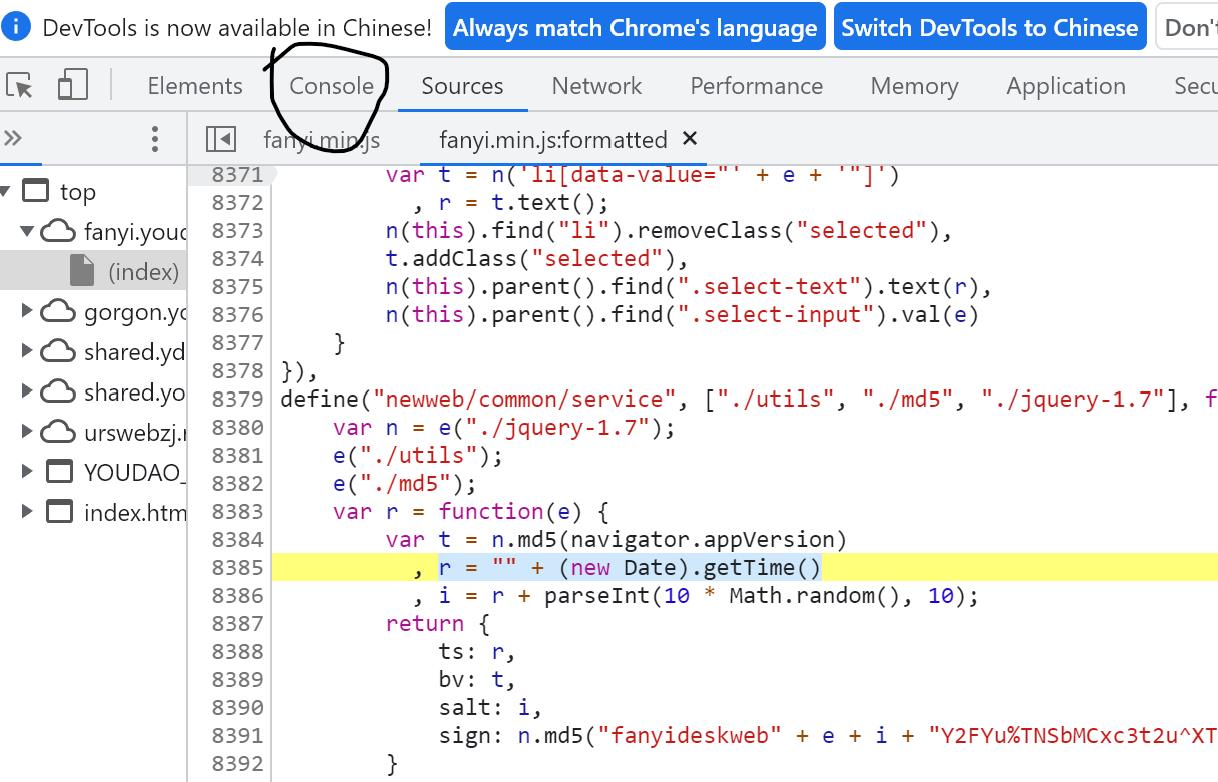
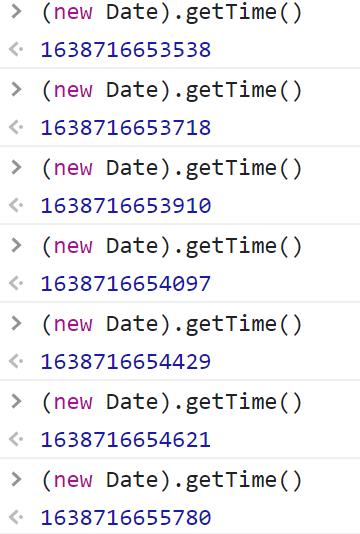
如上就是得到的结果,可以推断出,这行代码的作用就是获得时间戳;ts就是把时间戳变成了字符串类型,ts与lts数字的个数也一致,可以推断它们是一样的。
salt:细心的小伙伴可以发现,salt比lts就多了一位数字
salt的值就是 i 而 i = r + parseInt(10 * Math.random(), 10);其中r是时间戳,后面代码又看不懂了,继续在Console中多次输入parseInt(10 * Math.random(), 10):
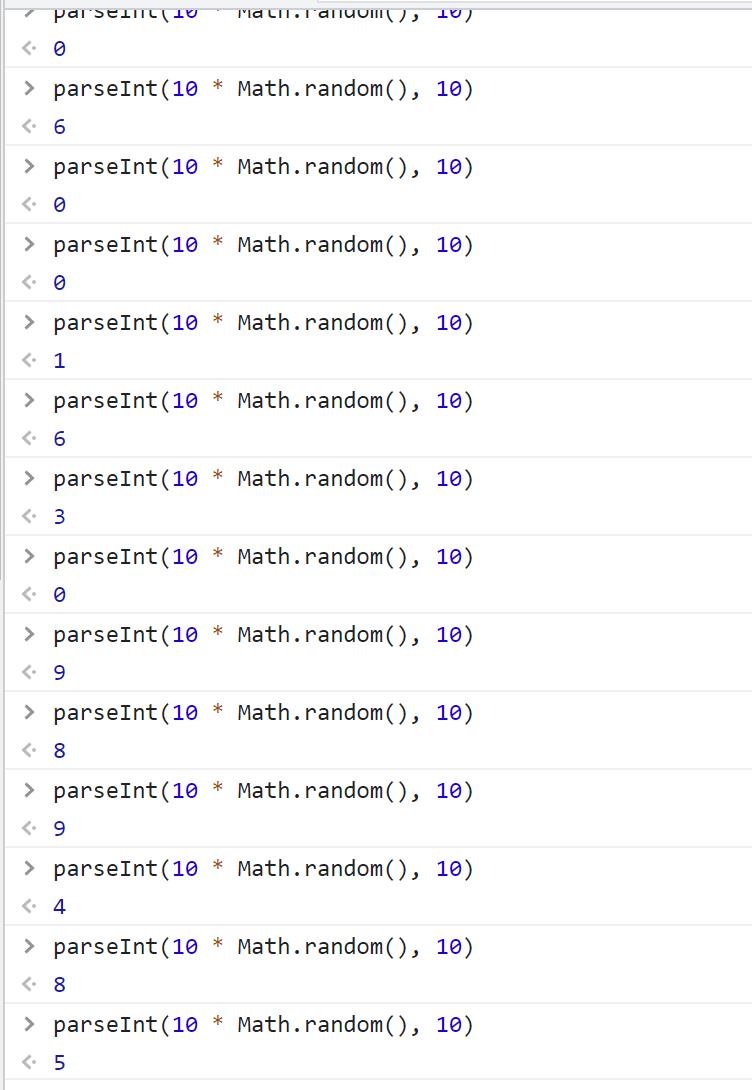
多次输入后你会发现,它是产生一个0-9的int型数据(没有10),也就是说salt的值就是lts的值后面加上了一个随机数
sign:首先可以看出它是十六进制
sign = n.md5("fanyideskweb" + e + i + "Y2FYu%TNSbMCxc3t2u^XT")
先说一下该表达式中的e:
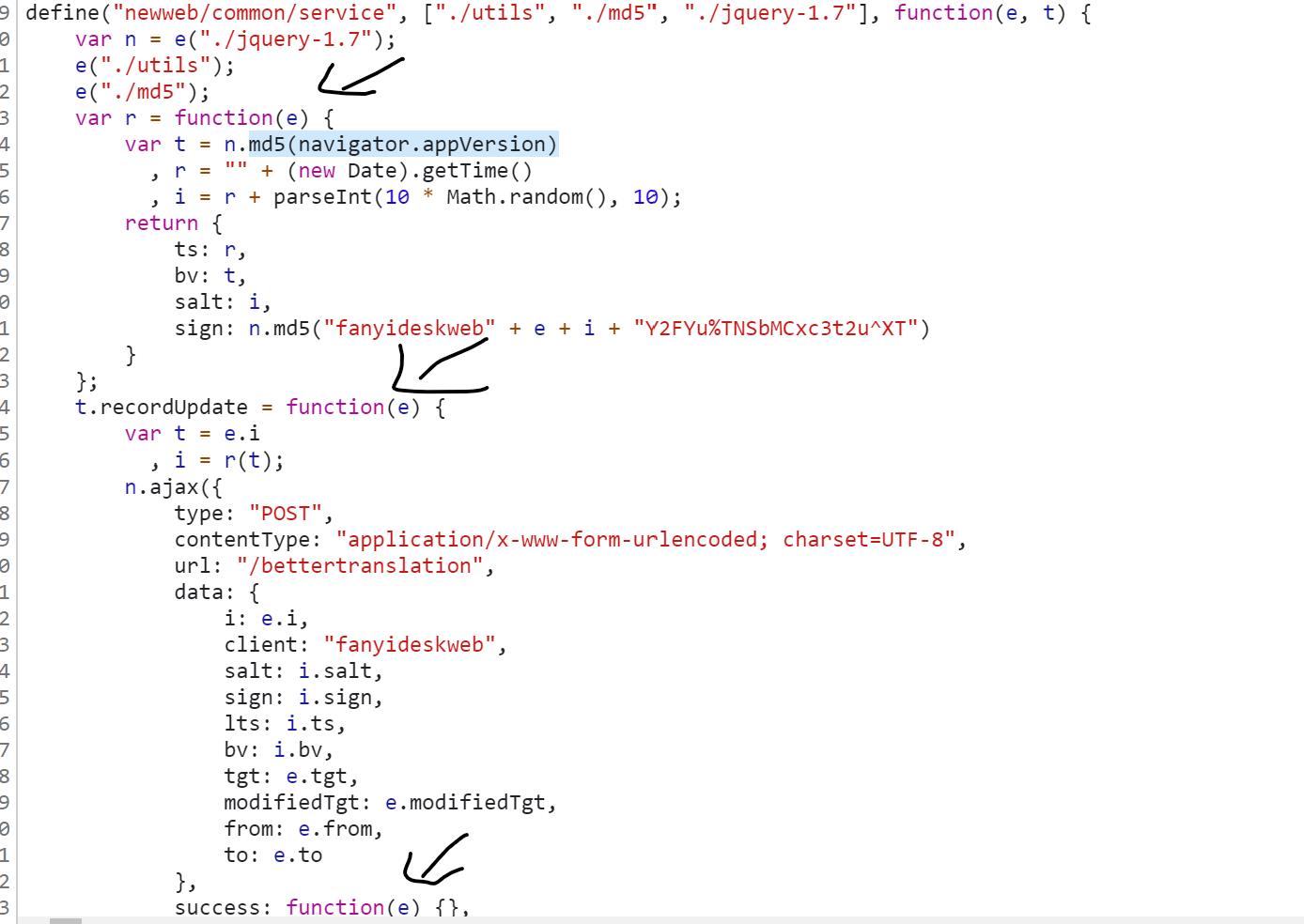
我们可以想一下,什么东西这么重要,使js代码中特别多的参数都是e,当然就是要翻译的词/句子了。
解析sign就需要我们知道python了,python中的hashlib模块中有md5方法

这两个是最常见的方法
下面通过代码,来了解md5:
import hashlib
# 进行hash运算的数据
data = 'python'
# 创建hash对象
md5 = hashlib.md5()
# 向hash对象中添加需要做hash运算的字符串
md5.update(data.encode())
# 获取字符串的hash值(十六进制输出)
result = md5.hexdigest()
print(result)结果:

在数据不是特别特别特别......大的时候,一个data对应一个md5后的值,一般不会出现重复
到此为止,Form Data 里面的值就都解决了,接下来写代码即可
二、源码
import requests
import hashlib
import time
import random
import json
from jsonpath import jsonpath
# 编写代码步骤:
# url
# headers
# form_data
# 发送请求,获取响应
# 解析数据(Response为json数据)
class You_dao(object):
def __init__(self, word):
self.url = 'https://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'
self.headers =
'User-Agent': '改为你的U-A',
'Referer': '改为你的Referer',
'Cookie': '改为你的Cookie'
self.form_data = None
self.word = word
# 获取数据
def generate_form_data(self):
"""
ts: "" + (new Date).getTime()
salt: ts + parseInt(10 * Math.random(), 10);
sign: n.md5("fanyideskweb" + word + salt + "Y2FYu%TNSbMCxc3t2u^XT")
"""
lts = str(int(time.time()*1000))
salt = lts + str(random.randint(0, 9))
data = "fanyideskweb" + self.word + salt + "Y2FYu%TNSbMCxc3t2u^XT"
md5 = hashlib.md5()
md5.update(data.encode())
sign = md5.hexdigest()
# 构建表单数据
self.form_data =
'i': self.word,
'from': 'AUTO',
'to': 'AUTO',
'smartresult': 'dict',
'client': 'fanyideskweb',
'salt': salt,
'sign': sign,
'lts': lts,
'bv': '318dde5ec635786619012045ee59bf8a',
'doctype': 'json',
'version': '2.1',
'keyfrom': 'fanyi.web',
'action': 'FY_BY_REALTlME'
def get_data(self):
response = requests.post(url=self.url, headers=self.headers, data=self.form_data)
return response.content
def run(self):
self.generate_form_data()
# 得到的数据为json类型
data = self.get_data()
# 将json转化为字典
data = json.loads(data)
data = jsonpath(data, '$..tgt')[0]
print(data)
if __name__ == '__main__':
Word = input('输入要翻译的单词或句子:')
you_dao = You_dao(Word)
you_dao.run()
以上是关于爬虫模拟对“有道在线翻译”发送请求(请求中的数据含需分析js来解出变化数据)的主要内容,如果未能解决你的问题,请参考以下文章