第 2 章 查询条件优化之等值查找
Posted 不剪发的Tony老师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第 2 章 查询条件优化之等值查找相关的知识,希望对你有一定的参考价值。
上一章介绍了索引的结构以及慢索引的原因。接下来我们将会学习如何发现并避免 SQL 语句中的这些问题,首先从 WHERE 子句开始。
WHERE 子句定义了 SQL 语句的搜索条件,因此它是索引快速查找数据的关键。虽然 WHERE 子句对性能的影响很大,我们经常过于粗心,导致数据库需要扫描索引中的大部分数据。结论就是:写得不好的 WHERE 子句是慢查询的第一个因素。
本章将会解释不同的操作符对索引使用的影响,以及如何让索引被用于尽可能多的查询语句。最后一节演示了一些常见的错误用法,以及如何修改并获得更好的性能。
等值查找
等号操作符(=)是最普通也最常用的 SQL 操作符。这种情况下的索引错误仍然很常见,尤其是 WHERE 子句包含多个条件时。
本节将会演示如何查看索引的使用情况,解释组合索引如何优化组合查询条件。
主键查找
我们从最简单最常见的 WHERE 子句开始:主键查找。本章使用的示例表 EMPLOYEES 如下:
CREATE TABLE employees (
employee_id NUMBER NOT NULL,
first_name VARCHAR2(1000) NOT NULL,
last_name VARCHAR2(1000) NOT NULL,
date_of_birth DATE NOT NULL,
phone_number VARCHAR2(1000) NOT NULL,
CONSTRAINT employees_pk PRIMARY KEY (employee_id)
)
数据库会自动为主键创建索引。这意味着字段 EMPLOYEE_ID 上存在一个索引,即使我们没有 create index 语句创建索引。
📝附录 C “示例模式” 包含了创建 EMPLOYEES 表和示例数据的脚本。该表中包含 1000 行数据。
以下查询使用主键查询某个员工的姓名:
SELECT first_name, last_name
FROM employees
WHERE employee_id = 123
WHERE 子句最多匹配一行数据,因为主键约束确保了 EMPLOYEE_ID 的唯一性。数据库不需要遍历索引叶子节点,只需要遍历索引树即可。以下是该语句的执行计划:
-- Oracle
---------------------------------------------------------------
|Id |Operation | Name | Rows | Cost |
---------------------------------------------------------------
| 0 |SELECT STATEMENT | | 1 | 2 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 1 | 2 |
|*2 | INDEX UNIQUE SCAN | EMPLOYEES_PK | 1 | 1 |
---------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("EMPLOYEE_ID"=123)
-- mysql,Type const 等价于 Oracle 中的 INDEX UNIQUE SCAN.
+----+-----------+-------+---------+---------+------+-------+
| id | table | type | key | key_len | rows | Extra |
+----+-----------+-------+---------+---------+------+-------+
| 1 | employees | const | PRIMARY | 5 | 1 | |
+----+-----------+-------+---------+---------+------+-------+
-- PostgreSQL,Index Scan 包含了 INDEX [UNIQUE/RANGE] SCAN 以及 TABLE ACCES BY INDEX ROWID 操作。
-- 执行计划中无法显示索引访问是否会返回多行记录。
QUERY PLAN
-------------------------------------------
Index Scan using employees_pk on employees
(cost=0.00..8.27 rows=1 width=14)
Index Cond: (employee_id = 123::numeric)
-- SQL Server,INDEX SEEK 和 RID Lookup 分别对应了 Oracle 中的 INDEX RANGE SCAN 以及 TABLE ACCESS BY ROWID。
-- 与 Oracle 不同的是, SQL Server 明确显示了通过索引查找表数据的嵌套循环连接。
|--Nested Loops(Inner Join)
|--Index Seek(OBJECT:employees_pk,
| SEEK:employees.employee_id=@1
| ORDERED FORWARD)
|--RID Lookup(OBJECT:employees,
SEEK:Bmk1000=Bmk1000
LOOKUP ORDERED FORWARD)
Oracle 执行计划显示为 INDEX UNIQUE SCAN,该操作只需要遍历索引树。它可以充分利用索引的对数可伸缩性,非常快速找到对应的索引项,性能几乎不受表大小的影响。
📝执行计划(解释计划或者查询计划)显示了数据库执行 SQL 语句的步骤。关于执行计划的获取和解读,可以参考这篇文章。
访问索引之后,数据库还需要再执行一步操作:TABLE ACCESS BY INDEX ROWID,获取表中存储的数据(FIRST_NAME, LAST_NAME)。这一步操作可能会成为性能瓶颈(参考上一章),不过 INDEX UNIQUE SCAN 不存在这个问题。因为索引唯一扫描最多返回一条记录,也就意味着最多一次表访问。INDEX UNIQUE SCAN 不会导致慢查询。
📝没有唯一索引的主键:主键不一定需要唯一索引,也可以使用非唯一索引。此时,Oracle 执行计划不会使用 INDEX UNIQUE SCAN,而是 INDEX RANGE SCAN。尽管如此,主键约束仍然能够确保字段的唯一性,因此索引查找最多还是只会返回一条记录。
主键使用非唯一索引的一个原因是为了支持可延迟约束(deferrable constraint)。可延迟约束和普通约束不同的是,它不是在语句执行时验证数据的合格性,而是推迟到事务提交时验证。将数据插入到具有循环依赖关系的表中需要延迟约束。
组合索引
即使数据库会自动为主键创建索引,如果主键由多个字段组成时,仍然可能存在手动优化的余地。这种情况下,数据库基于所有的主键字段创建索引,被称为组合索引(多列索引、复合索引或者联合索引)。注意,组合索引中字段的顺序对于它的可用性非常重要,因此需要小心选择。
为了演示,我们假设某个公司需要进行合并。另一个公司的员工需要增加到该公司的 EMPLOYEES 表中,使得该表增长了十倍。问题只有一个:两个公司的 EMPLOYEE_ID 不唯一,存在冲突。我们需要扩展主键,引入一个额外的标识符,例如 子公司 ID。因此,新的主键包含了两个字段重建唯一性:原来的 EMPLOYEE_ID 以及新的 SUBSIDIARY_ID。
新主键的索引可以使用以下命令创建:
CREATE UNIQUE INDEX employees_pk
ON employees (employee_id, subsidiary_id)
查找特定员工时,需要考虑完整的主键字段,也就是需要包含 SUBSIDIARY_ID:
SELECT first_name, last_name
FROM employees
WHERE employee_id = 123
AND subsidiary_id = 30
当查询使用了完整的主键,数据库可以使用 INDEX UNIQUE SCAN,无论索引包含多少个字段。但是,如果查询条件中只包含了一个字段,例如查找某个子公司中的所有员工,结果会怎么样呢?
SELECT first_name, last_name
FROM employees
WHERE subsidiary_id = 20
执行计划显示数据库不会使用主键索引,而是执行了全表扫描(TABLE ACCESS FULL)。结果就是数据库扫描了整个表并将每一行数据和 WHERE 子句进行比较。执行时间随着表的大小而增长:如果表增长十倍,TABLE ACCESS FULL 花费的时间也增长十倍。这种操作的危害性在于,如果是很小的开发环境,通常性能很快,但是它会在生产环境中导致严重的性能问题。
📝全表扫描:TABLE ACCESS FULL,也被称为全表扫描,在某些情况下可能是最高效的访问方式,尤其是查询需要返回表中大部分的数据时。
部分原因在于索引查找占用的时间,TABLE ACCESS FULL 不会存在这些消耗。主要的原因是索引查找每次只会读取一个索引块,因为数据库只有处理完当前索引块才能确定下一个需要读取的索引块。FULL TABLE SCAN 无论如何都需要读取整个表,所以数据库可以一次读取更大的块(多块读取)。虽然数据库读取了更多数据,但是它可能执行了更少的读取操作。
数据库没有使用主键索引是因为它无法随意使用组合索引中的单个字段。仔细查看一下索引结构就清楚了。
组合索引也是一个 B-树索引,也是通过一个排序链表存储了被索引的数据。数据库使用索引定义中的字段顺序进行排序,首先按照第一个字段进行排序,只有当第一个字段的值相同时才使用第二个字段排序,依此类推。
⚠️组合索引是基于多个字段的单个索引。
基于两个字段的索引顺序和电话目录类似:首先按照姓氏排序,然后按照名字排序。这意味着基于两个字段的索引不支持单独使用第二个字段的搜索,这种搜索就像时在电话目录中使用名字查找一样。
图 2.1 组合索引
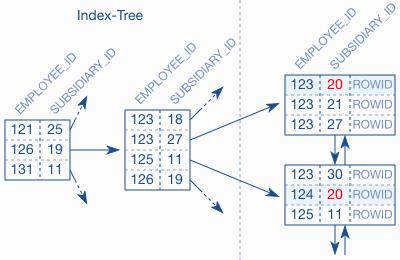
图 2.1 中的索引片段显示了子公司 20 的员工没有存储在相邻的位置,而且树节点中没有 SUBSIDIARY_ID = 20 的索引项,而是存储在了叶子节点。索引树对于这个查询而言没有什么用途。
📝将索引可视化可以帮助我们理解该索引支持的查询。通过查询可以按照顺序返回索引中的记录(SQL:2008 语法,也可以使用数据库特有的 LIMIT、TOP 或者 ROWNUM 语法):
SELECT <INDEX COLUMN LIST>
FROM <TABLE>
ORDER BY <INDEX COLUMN LIST>
FETCH FIRST 100 ROWS ONLY如果将索引和表名替换到以上查询中,你就可以获得该索引中的一部分数据。如果需要查询的数据行没有聚集在一起,索引树遍历就无法找到所需的数据。
当然,我们可以基于 SUBSIDIARY_ID 再创建一个索引,优化查询性能。但是还有一个更好的方案,如果我们认为单独基于 EMPLOYEE_ID 查找数据没有意义的话。
我们可以利用一个事实:索引的第一个字段总是可以用于搜索数据。这一点同样和电话目录类似:查找姓氏不需要知道名字。因此,我们可以将索引中的 SUBSIDIARY_ID 字段放到第一位:
CREATE UNIQUE INDEX EMPLOYEES_PK
ON EMPLOYEES (SUBSIDIARY_ID, EMPLOYEE_ID)
这两个字段的组合仍然具有唯一性,因此基于整个主键的查询仍然可以使用 INDEX UNIQUE SCAN,不过索引项的顺序完全不同了。SUBSIDIARY_ID 现在成为了第一个排序字段,这意味着同一个子公司的员工在索引中是连续的,因此数据库可以使用 B-树查找他们的位置。
⚠️定义组合索引时最重要的事情就是选择字段的顺序,使得它可以被用于尽可能多的查询。
执行计划显示数据库使用了调整字段顺序后的索引。单独的 SUBSIDIARY_ID 字段不再具有唯一性,因此数据库必须遍历叶子节点,从而找到所有匹配的数据:所以它使用了 INDEX RANGE SCAN。
-- Oracle
---------------------------------------------------------------
|Id |Operation | Name | Rows | Cost |
---------------------------------------------------------------
| 0 |SELECT STATEMENT | | 106 | 75 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 106 | 75 |
|*2 | INDEX RANGE SCAN | EMPLOYEES_PK | 106 | 2 |
---------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("SUBSIDIARY_ID"=20)
-- MySQL,访问类型 ref 等价于 Oracle 数据库中的 INDEX RANGE SCAN。
+----+-----------+------+---------+---------+------+-------+
| id | table | type | key | key_len | rows | Extra |
+----+-----------+------+---------+---------+------+-------+
| 1 | employees | ref | PRIMARY | 5 | 123 | |
+----+-----------+------+---------+---------+------+-------+
-- PostgreSQL,这种情况下包含了两个操作:Bitmap Index Scan 以及 Bitmap Heap Scan。它们大体上对应于 Oracle 中的 INDEX RANGE SCAN 和 TABLE ACCESS BY INDEX ROWID,但是存在一个重要的区别:它首先从索引中获取所有的结果(Bitmap Index Scan),然后根据数据行在堆表中的物理存储位置进行排序,排序之后从表中返回数据(Bitmap Heap Scan)。这种方法减少了表上的随机 IO 次数。
QUERY PLAN
----------------------------------------------
Bitmap Heap Scan on employees
(cost=24.63..1529.17 rows=1080 width=13)
Recheck Cond: (subsidiary_id = 2::numeric)
-> Bitmap Index Scan on employees_pk
(cost=0.00..24.36 rows=1080 width=0)
Index Cond: (subsidiary_id = 2::numeric)
-- SQL Server
|--Nested Loops(Inner Join)
|--Index Seek(OBJECT:employees_pk,
| SEEK:subsidiary_id=20
| ORDERED FORWARD)
|--RID Lookup(OBJECT:employees,
SEEK:Bmk1000=Bmk1000
LOOKUP ORDERED FORWARD)
一般来说,数据库使用最左侧的前置列查找数据时可以使用索引。基于三个字段的索引可以用于查找第一个字段、查找前两个字段以及查找所有字段。
虽然创建两个索引也可以很好地优化查询性能,但是推荐使用组合索引。这样不仅可以减少存储空间,还可以减少维护第二个索引的开销。索引越少,插入、删除和更新的性能越好。
为了能够定义最佳索引,不仅仅需要理解索引的原理,还需要了解应用程序如何查询数据。这意味着我们需要知道 WHERE 子句中字段的组合方式。
因此,对于外部顾问而言,很难定义最佳索引,因为他们不知道应用程序的查询情况。顾问通常只能帮助优化单个查询,无法通过索引为其他查询带来好处。数据库管理员也类似,他们了解数据库的模式,但是并不一定深入理解查询语句的访问路径。
开发部门结合了数据库技术知识和业务领域的功能知识。开发人员了解数据的使用情况,他们可以为应用程序建立合适的索引,获得最佳的性能。
慢索引:第二部分
前文介绍了如何通过修改索引字段的顺序从已有索引获得更多的性能优化,不过以上示例只考虑了两个 SQL 语句,修改索引可能会影响针对该表的所有查询。本节介绍数据库选择索引的方法,同时演示修改已有索引可能带来的副作用。
EMPLOYEES_PK 索引可以优化基于子公司的查询。实际上它可以用于所有基于 SUBSIDIARY_ID 搜索数据的查询,无论查询中是否包含其他的搜索条件。这意味着该索引可以用于原本使用其他索引的查询,这些查询的 WHERE 子句中还包含其他条件。在这种情况下,数据库存在多个访问数据的路径,优化器需要选择一个最佳的访问方式。
查询优化器:查询优化器,或者查询计划器,是数据库的一个组件,用于将 SQL 语句转换为一个执行计划。这个过程也被称为编译或者解析。优化器包含两种类型:
基于成本的优化器(CBO)可以生成很多不同的执行计划,并且计算每个计划的成本值。成本的计算基于所需的操作和评估的数据行。最终成本值用于选择“最佳”执行计划。
基于规则的优化器(RBO)通过一个固定的规则集生成执行计划。基于规则的优化器缺乏灵活性,现在已经很少使用。
修改索引可能会导致不好的副作用。在以上示例中的体现就是内部的电话目录应用程序由于合并变得很慢。初步分析确认以下查询是主要的原因:
SELECT first_name, last_name, subsidiary_id, phone_number
FROM employees
WHERE last_name = 'WINAND'
AND subsidiary_id = 30
执行计划如下:
示例 2.1 调整主键索引后的执行计划
---------------------------------------------------------------
|Id |Operation | Name | Rows | Cost |
---------------------------------------------------------------
| 0 |SELECT STATEMENT | | 1 | 30 |
|*1 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 1 | 30 |
|*2 | INDEX RANGE SCAN | EMPLOYEES_PK | 40 | 2 |
---------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("LAST_NAME"='WINAND')
2 - access("SUBSIDIARY_ID"=30)
执行计划使用了索引,总的成本值为 30。目前看起来还可以。尽管如此,值得怀疑的是它使用了我们刚刚修改的索引。这足以让我们怀疑是索引修改导致了性能问题,尤其是考虑到原来的索引以 EMPLOYEE_ID 字段开始,它完全没有出现在 WHERE 子句中。该查询之前不可能使用 EMPLOYEES_PK 索引。
为了进一步分析,我们可以比较索引修改前后的执行计划。为了得到原始的执行计划,我们可以重新创建原理的索引,不过大多数数据库提供了一个更简单的方法,可以阻止查询使用某个索引。以下示例使用 Oracle 优化器提示实现该目的:
SELECT /*+ NO_INDEX(EMPLOYEES EMPLOYEES_PK) */
first_name, last_name, subsidiary_id, phone_number
FROM employees
WHERE last_name = 'WINAND'
AND subsidiary_id = 30
在索引变更之前可能使用的执行计划完全没有使用索引:
----------------------------------------------------
| Id | Operation | Name | Rows | Cost |
----------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 477 |
|* 1 | TABLE ACCESS FULL| EMPLOYEES | 1 | 477 |
----------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("LAST_NAME"='WINAND' AND "SUBSIDIARY_ID"=30)
虽然 TABLE ACCESS FULL 需要读取并处理整个表,但是在这个查询中它比索引更快。这种情况很不寻常,因为它只匹配了一行数据。使用索引查找单行数据应该比全表扫描快很多,但是在这个示例中不是如此,索引似乎更慢一些。
在这种情况下,最好的方法就是查看执行计划的详细步骤。第一步是 EMPLOYEES_PK 索引上的 INDEX RANGE SCAN。该索引没有包含 LAST_NAME 字段,INDEX RANGE SCAN 只考虑了 SUBSIDIARY_ID 过滤。Oracle 数据库在执行计划的“Predicate Information”部分显示了该信息(执行计划的第 2 项)。这一部分显示了每个操作应用的条件。
📝附录 A“执行计划”解释了如何在其他数据库中查找“Predicate Information”。
操作 ID 为 2 的 INDEX RANGE SCAN (示例 2.1)只应用了 SUBSIDIARY_ID=30 过滤。这意味着它遍历索引树找到第一个 SUBSIDIARY_ID=30 的索引项。然后遍历叶子节点链查找该子公司的所有索引项。INDEX RANGE SCAN 的结果是一个满足 SUBSIDIARY_ID 条件的 ROWID 列表:结果可能包含很少的行,也可能包含数百行,取决于子公司的大小。
下一步就是 TABLE ACCESS BY INDEX ROWID 操作。它利用上一步返回的 ROWID 获取数据,包含了表中的全表字段。一旦获得了 LAST_NAME 字段,数据库就可以判断 WHERE 子句的中其他条件。这意味着数据库需要或者 SUBSIDIARY_ID=30 的所有数据行,然后应该 LAST_NAME 过滤数据。
该语句的响应时间不取决于结果的大小,而是特定子公司的员工数量。如果子公司的员工很少,INDEX RANGE SCAN 性能更好。不过,TABLE ACCESS FULL 对于大型的子公司性能更好,因为它每次可以读取更多的数据(参考上文中的全表扫描)。
查询慢的原因是索引查找返回了很多 ROWID,每个员工一条记录,数据库必须分别获取这些员工的数据。这个示例完美地结合了慢索引的两个因素:数据库扫描了大量的索引,同时必须逐一获取很多的数据行。
选择最佳执行计划还取决于表中的数据分布,所以优化器会利用数据库的统计信息进行决策。以上示例中,数据库使用了以子公司为单位的员工分布直方图。这种直方图使得优化器可以评估索引查找可能返回的行数,从而用于成本计算。
📝统计信息:基于成本的优化器会使用表、字段以及索引的统计信息。大多数的统计信息基于字段进行收集:字段中不同值的数据、最小值和最大值(数据范围),NULL 出现的次数以及字段的直方图(数据分布)。最重要的表统计信息是它的大小(行数和数据块)。
最重要的索引统计信息是树的深度、叶子节点的数量、不同键的数据以及聚集因子(clustering factor,参见第 5 章。)
优化器使用这些数据评估 WHERE 子句中谓词的选择性。
如果没有可用的统计信息(例如统计信息被删除了),优化器将会使用默认值。Oracle 数据库默认的统计信息为索引较小、选择性中等,此时 INDEX RANGE SCAN 将会返回 40 行数据,执行计划中的 Rows 列显示了这个估计值。显然,这是一个被严重低估了的值,因为该子公司有 1000 名员工。
如果我们提供正确的统计信息,优化器可以做得更好。以下执行计划显示了新的评估值:INDEX RANGE SCAN 返回了 1000 行数据。因此,后续表访问操作的成本更高。
---------------------------------------------------------------
|Id |Operation | Name | Rows | Cost |
---------------------------------------------------------------
| 0 |SELECT STATEMENT | | 1 | 680 |
|*1 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 1 | 680 |
|*2 | INDEX RANGE SCAN | EMPLOYEES_PK | 1000 | 4 |
---------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("LAST_NAME"='WINAND')
2 - access("SUBSIDIARY_ID"=30)
成本值 680 比使用 FULL TABLE SCAN(470)的执行计划更高,所以优化器选择了 FULL TABLE SCAN。
这个慢索引的示例并没有否定一个事实:合适的索引是最佳的解决方案。查找名字的最佳方法当然是通过 LAST_NAME 字段上的索引:
CREATE INDEX emp_name ON employees (last_name)
使用新的索引时,优化器计算出的成本为 3:
示例 2.2 专用索引的执行计划
--------------------------------------------------------------
| Id | Operation | Name | Rows | Cost |
--------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 3 |
|* 1 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 1 | 3 |
|* 2 | INDEX RANGE SCAN | EMP_NAME | 1 | 1 |
--------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("SUBSIDIARY_ID"=30)
2 - access("LAST_NAME"='WINAND')
基于优化器的评估,索引访问只返回了一行记录。因此,数据库只需要从表中返回该行数据,这显然比 FULL TABLE SCAN 更快。一个合适的索引仍然比全表扫描更好。
示例 2.1 和示例 2.2 的执行计划几乎相同。数据库执行了相同的操作,优化器计算了类似的成本值,只不过第二个执行计划更好。INDEX RANGE SCAN 的效率可能存在很大的差异,尤其是后续需要访问表时。使用索引并不一定意味着就是最佳访问方式。
以上是关于第 2 章 查询条件优化之等值查找的主要内容,如果未能解决你的问题,请参考以下文章