Quake 一个开源的知识管理元框架
Posted Phodal
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Quake 一个开源的知识管理元框架相关的知识,希望对你有一定的参考价值。
本文使用 Quake Web 应用编写,虽然只有基本的 Command + S 来保存标题 + 内容的功能。这个简单粗糙的页面,让我想起了多年前构建 Phodit 的场景, it works 作为开始就足够了。
来, 先上链接 GitHub: https://github.com/phodal/quake
缘由
半个月前,我在准备一个材料,好不容易从我的博客、Todo、Notes 里找到了一些相关的素材。我使用了不同的工具来管理知识,Microsoft To Do 管理 idea、Phodit + Phodal.com 发布文章、Apple Notes 记录笔记等等,知识被分散在各个工具中。不利于我进行洞见,寻找灵感,与此同时,还缺乏书写和记录的方式。
于是,我需要一个新的工具来融合到我的知识体系里,它应该是:
开源的。可以自由扩展。
分布式 + 本地化的。可以离线使用,方便于出差旅途中使用。
版本化的。可以自由查看变更历史。
开放的。可以自由与其它工具组合。如 Vim、VSCode 等。
易于扩展。可以结合习惯用的工具。诸如于,基于 DSL 的编辑-发布分离的类 Web 模式,用于展示。如 MxGraph、Mermaid、Ledge Framework 等
所以,就有了:https://github.com/phodal/quake
Quake:知识管理元框架
Quake 的目标是构建面向极客的知识管理元框架,它可以:
自由的文本内容管理。Todo 清单、文章管理、书评、笔记等。
构建知识网络体系。定制化 markdown 链接
抓住稍纵即逝的灵感。支持快速启动(CLI、TUI)与全局搜索
自由的呈现画布。DSL 与自由画板
简单来说,通过 Markdown 来记录数据,Git 来进行版本化,Terminal 来快速编辑,Web + Web Components 提供定制能力。
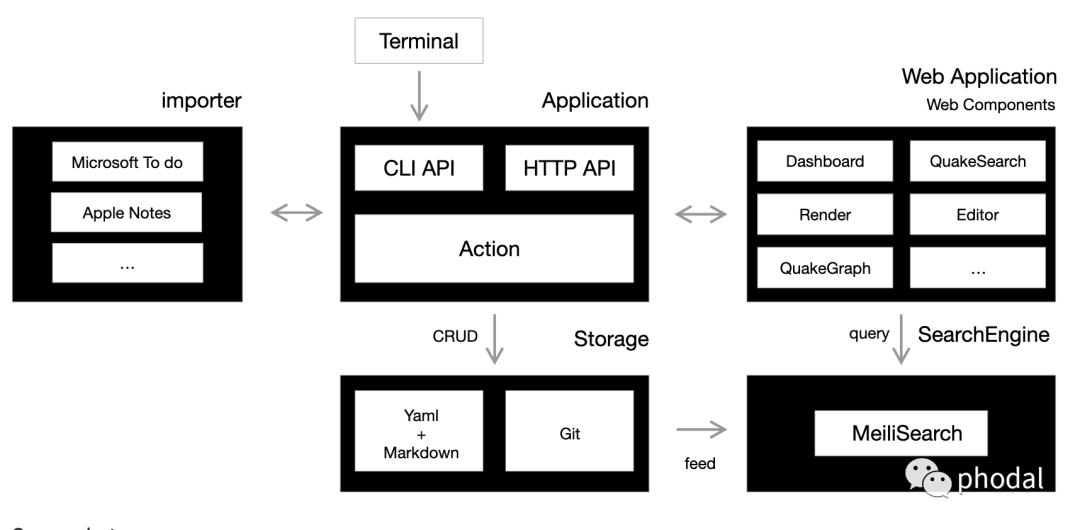
Quake 设计理念 1:数据代码化
Quake 延续了 Ledge Framework 中非常成功地思想:文档代码化 + Markdown 图表化 + Git,来提供对于数据的管理。尽管我们没有在 Quake 中引入数据库,但是依旧可以提供如下所功能:
数据迁移。
历史状态。设计一个拥有历史状态的内容是一件麻烦的事情。
数据查询与更新。
……
只是呢,现在的这些功能只能支持基本的开发。对于扩展来说,依旧是有问题的,未来需要提供简化版的 SQL,以提供更好的数据处理。而除了 SQL 之外,另外一种简单的方式,就是提供脚本语言的支持。
Quake 设计理念 2:自由定制
设计一个能支持不同数据模型的知识管理系统痛苦了,需要大量地前期工作。因此,我们先构建了一个可以自定义数据格式的元数据引擎。让每个人都可以自定义的数据格式,并能为这些数据自定义视图,就能简化大量的工作。
自定义数据类型
在 Quake 里,通过 YAML 来定义数据格式,也可以从导出的数据后生成(通过 quake cmd -i “quake.sync” ):
- type: notes
display: ""
fields:
- title: Title
- description: String
- category: String
- created_date: Date
- updated_date: Date
- author: String
actions: ~生成对应的 markdown 文件,形如: 0001-time-support.md 即 id + title 的形式,对文件再进行编辑:
---
title: time support
author:
content:
created_date: 2021-11-24 19:14:10
updated_date: 2021-11-24 19:14:10
---
ahaha考虑到生态兼容的问题,所以在 Quake 里直接采用了 Jekyll 的 Front Matter 语法来定义数据。我们对于文件的编辑操作,即内容和相关的内容信息,都是直接基于这个 markdown 文件的。
自定义显示组件
进行中。
现有的 Web 部分架构是基于 Web Component 构建的,以提供自定义的数据操作能力。如通过下述的代码,可以构建我们的编辑器,并进行对应的交互:
const editor = document.createElement('quake-editor');
editor.setAttribute('id', entry.id);
editor.setAttribute('title', entry.title);
editor.setAttribute('value', entry.content);
editor.addEventListener("onSave", function (event)
update_entry(params.type, params.id,
title: event.detail.title,
content: event.detail.value.replaceAll("\\\\\\n", "\\n")
)
);
return editor对于不同的内容来说,也是类似的,只需要创建好对应的组件,处理相应的结果即可。通过这种方式,构建出常用的各种数据类型,并让所有的开发者都可以自定义。
如何使用 Quake
现阶段,Quake 面向的群体主要是极客、软件工程师,又或者是具备一定 IT 基础的软件开发人员。毕竟,我们还没有 GUI,还需要一系列的应用封装工作。不过,GUI 从架构上来说太重了,构建一个基于本地 Web + Terminal 的 MVP 版本反而更加容易,还能验证自由度的可行性。
安装 Quake
Quake 的安装在现阶段,还是比较麻烦的,还只能在 CLI 下进行(所以,我们面向开发者,我还有得选吗?):
安装 Quake。
有 Rust 环境的话,可以直接 cargo install quake
没有 Rust 环境的话,可以从 Quake Release 页面下载。
安装搜索引擎(可选的)
macOS 用户,可以直接 brew install meilisearch
其它操作系统的用户,建议访问官方进行:https://github.com/meilisearch/MeiliSearch
引入 Web 页面。可以从 Quake Release 页面下载 web.zip,并解压到某个目录。
随后,到相应的文档目录,执行 `quake init`,就可以得到一个初始化的环境了。执行 quake server ,就可以进入 Web 页面使用了。
Quake Importer
回到文章的开头,首先我们要解决的是数据迁移的问题。所以,上周末,我的主要工作是在数据迁移上,将不同的数据源转化为 Markdown。如在 Quake Importer 中,有下述相关数据源的文档:
Django CMS 的相关文章
Apple Notes(备忘录)的相关备忘
Microsoft To do 的相关待办事项
从我的数据来看,我大概有 888 篇的文章,99 个 Todo,还有 302 篇的备忘。当然了,我还有一部分抓取的资料存储在 Microsoft OneNote 上,这部分在后续需要进一步完善了。
Quake Cmd
在导出相关数据,便可以通过 quake cmd -i “quake.sync” 命令同步生成定义不同内容类型的定义文件。
随后,可以直接创建新的内容,只需要通过 quake cmd -i “blog.add: Quake 一个知识管理元框架” 来快速创建新的 blog 内容。Quake 优先通过 Terminal 实现了基本的 CRUD 功能,如此一来,我们不需要缓慢地启动笔记工具,才能完成一个快速的想法。我们可以利用大量地再成的基于 Terminal 编辑器,如 Vim,快速完成记录。
在保存之后,我们将更新生成对应的 csv 数据索引文件,以面向 Terminal 提供快速的接口能力。
Quake Server
当我们需要寻找灵感时,便可以通过 quake server 启动我们的 Web 服务,在上面搜索、索引知识、管理知识等。基于本地的 Markdown + Meili 搜索引擎,我们能构建最好的本地体验。Quake 的 Web UI 界面是基于一个个的 Web Component 构建的,这就意味着,在我们提供 CRUD API 的基础上,你可以结合我们提供的组件能力,自由地构建你的 Web UI。通过在 Quake 的配置文件 .quake.yaml 中修改 server_location 参数,就能使用自己开发的页面了。在这时,Quake 只是作为一个 Markdown 的 CRUD API。示例:
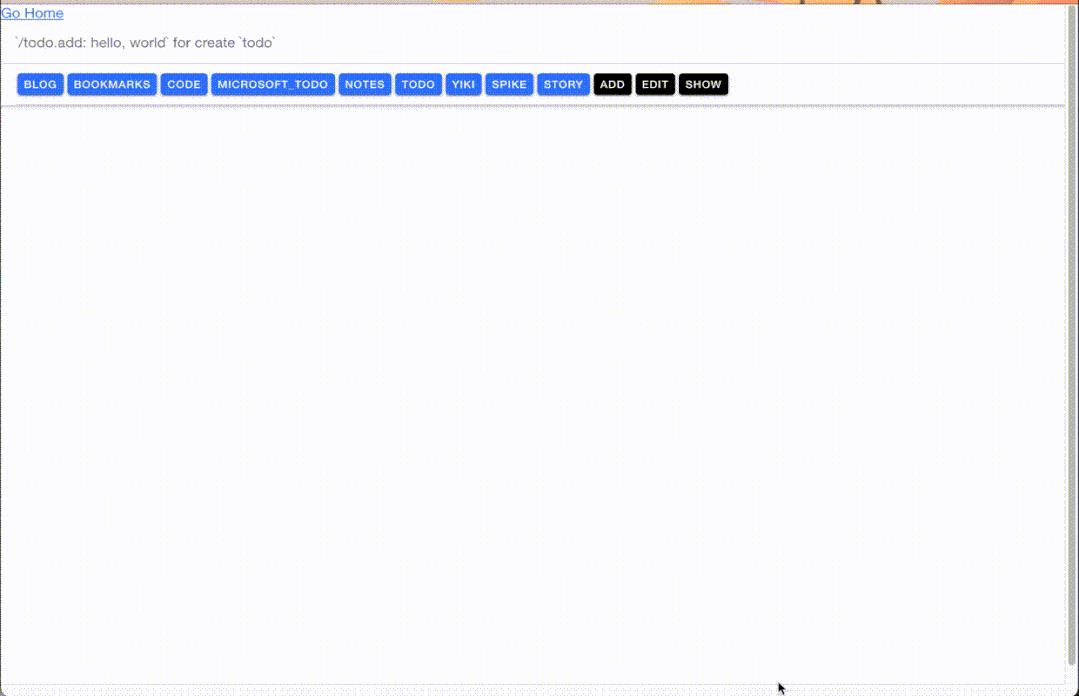
最后,因为所有的数据是围绕于 markdown + yaml 的,所以,我们可以结合 Git 进行版本化管理。(PS:这部分功能还没设计)
下一步
在完成了 MVP (最小可行产品)版本之后,依旧还有一系列的工作要做:
Terminal UI。已经有小伙伴工作在上面。
定制 Markdown 语法。用于支持诸如于双链、文本图表化、脑图
全局 GUI 入口。从全局搜索支持,类似于 Spotlight Search
Web 应用设计。现在的版本非常粗糙,缺乏各种功能。
更好的知识管理。
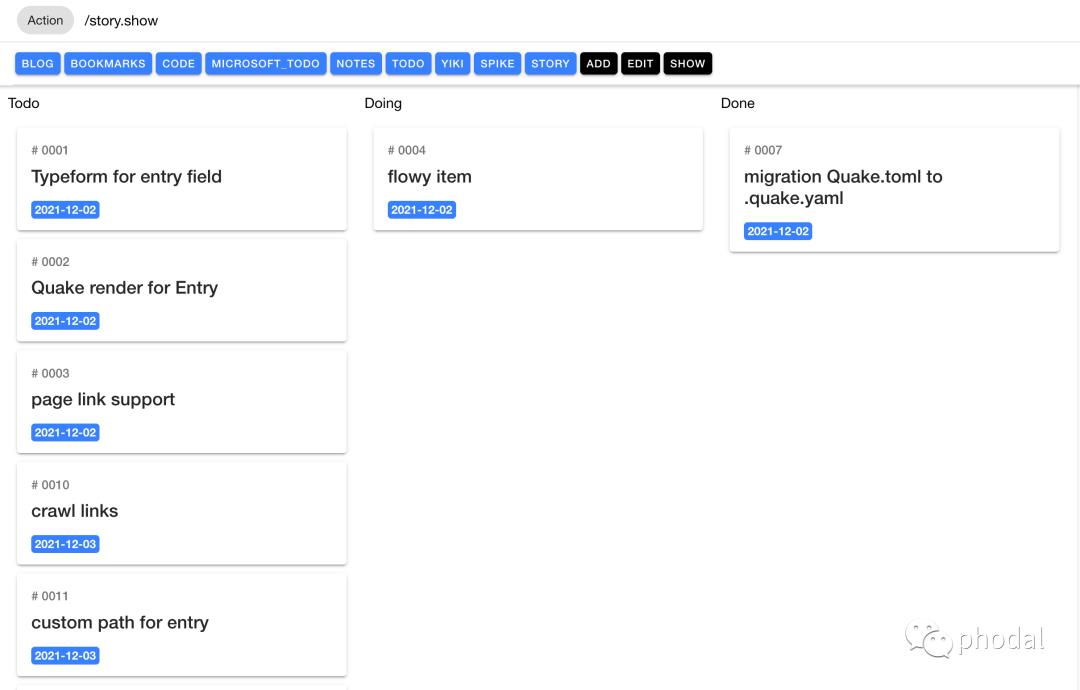
你可以在 Quake 的 Story 中看到更多的相关内容。
如果你也有兴趣,欢迎加入我们:

以上是关于Quake 一个开源的知识管理元框架的主要内容,如果未能解决你的问题,请参考以下文章
SpringCloud系列四:Eureka 服务发现框架(定义 Eureka 服务端Eureka 服务信息Eureka 发现管理Eureka 安全配置Eureka-HA(高可用) 机制Eur(代码片段