谷歌翻译被曝“辱华”?官方回应来了
Posted Wang_AI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了谷歌翻译被曝“辱华”?官方回应来了相关的知识,希望对你有一定的参考价值。
谷歌翻译翻车了!
大部分人使用翻译软件时,对于翻译后的语言大部分都是看不懂的,所以除了选择相信翻译后的结果,并没有其他选择。
但如果翻译结果你能看懂,并且发现他翻译错了,那。。。

最近安徽省团委在微博上发现谷歌翻译会将一些艾滋病相关的词翻译为中国侮辱性词汇,引发网友对谷歌翻译的反感和愤怒。

在英翻中的英文对话框输入「新闻」,「传播」等词汇,中文部分显示的仍然是「新闻」和「传播」。
但在英文对话框输入「艾滋病毒」等类似词汇,中文翻译就会显示恶毒攻击中国的词汇。如输入「艾滋病人」,就会出现「武汉人」的中文翻译。
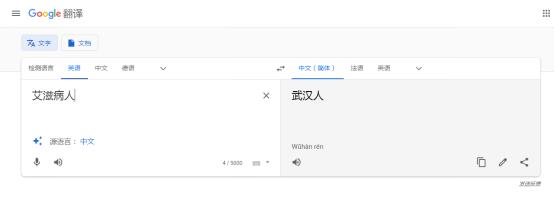
输入“艾滋患者”,翻译结果为“中央电视台”。
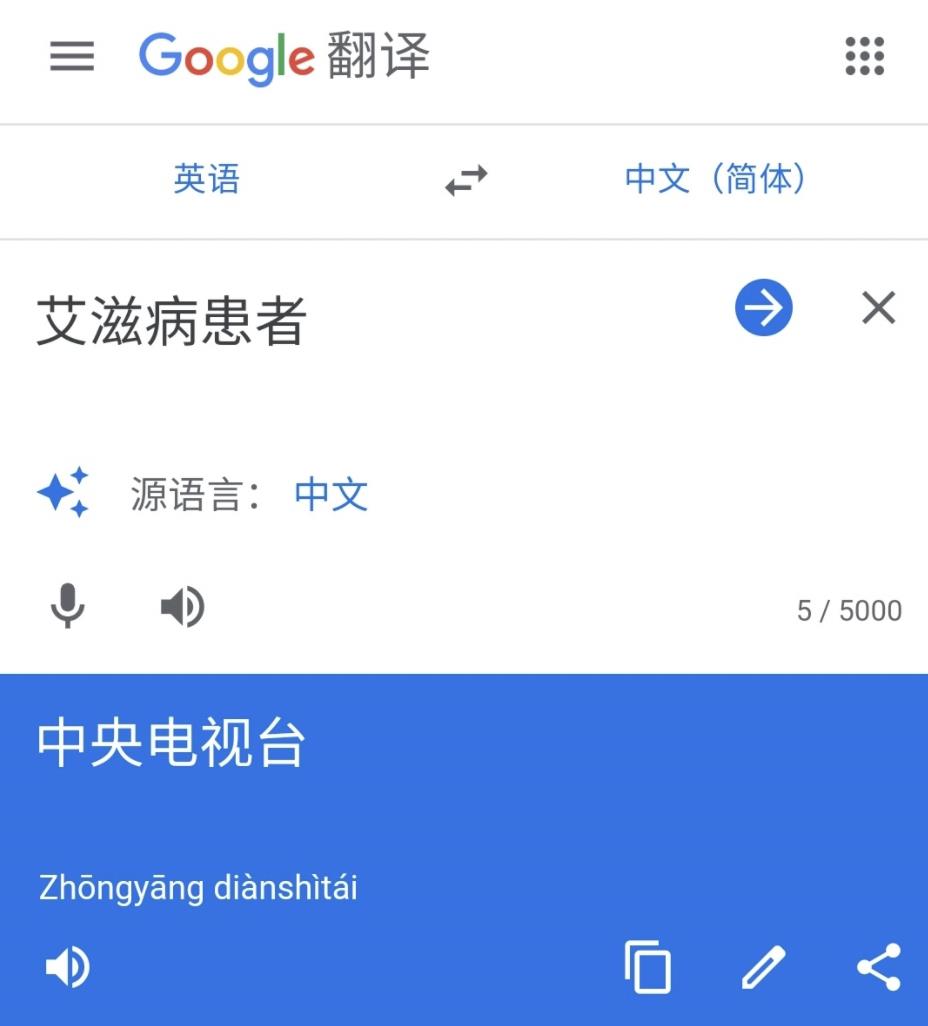
输入“艾滋病成人”,翻译结果为“新中国”。
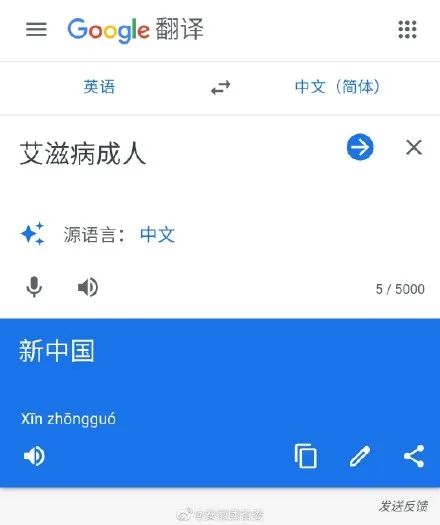
除了部分与“艾滋”相关词汇翻译后显示恶意攻击中国的内容外,还有网友发现,输入“埃博拉史”,翻译结果为“中国史”。
上述内容曝光后,短时间内便令大量网友炸锅。
目前谷歌翻译的问题已无法复现,有网友认为谷歌是在「夹带私货」,但Google 在微博上的解释是「模式」,也就是说训练语料要背大锅,如果训练语料存在夹带私货的情况,那翻译结果也不会准确。
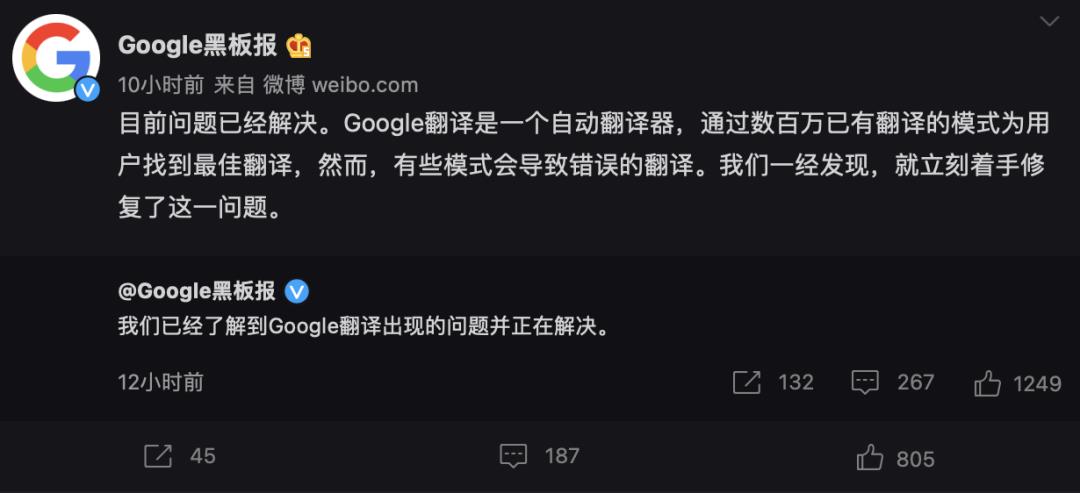
不过也有网友发现谷歌翻译也会将「埃博拉病毒」翻译为「纽约病毒」。
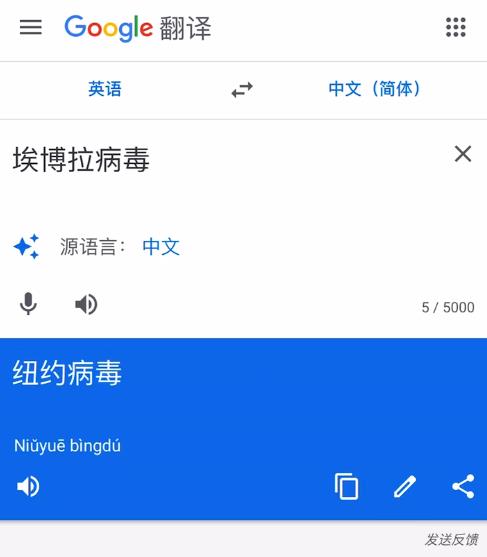
输入“艾滋病蠢”,翻译结果为“西方蠢”。
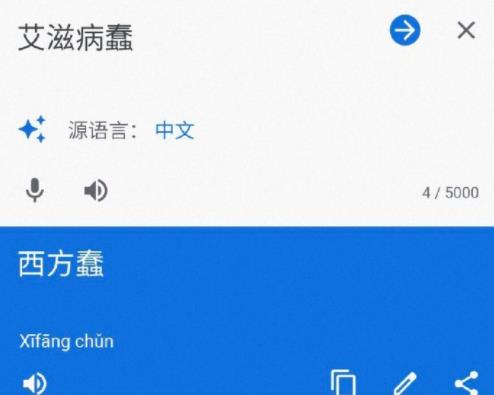
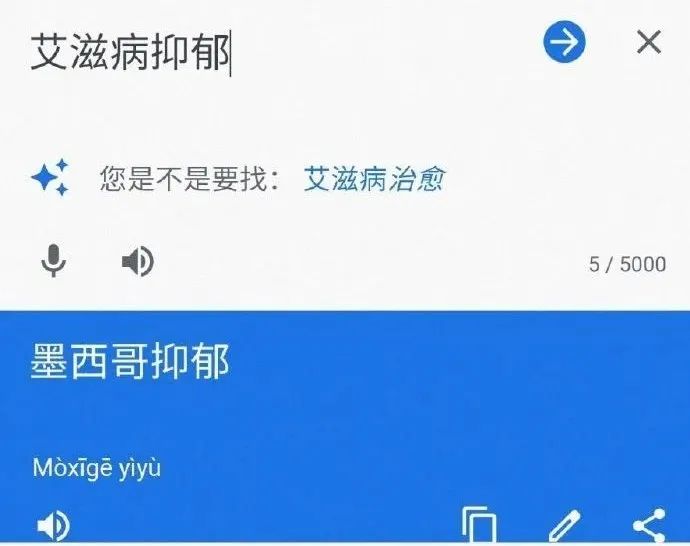
输入“艾滋病抑郁”,翻译结果为“墨西哥抑郁”。
在谷歌回应之后,安徽省团委也再次发文表示「希望广大网友们能理性对待,中国人民不可辱!」

对此,NeX8yte指出,国际互联网上中文的语料大部分并不掌握在我们自己手里,而且此类结果很可能是经过了中介语言,从而也就放大了错误。
顺便一提,谷歌2010 年退出中国内地市场。
时任工业和信息化部部长李毅中同年3月12日在回应「谷歌退出中国事件」时说,中国的互联网是开放的,进入中国市场就必须遵守中国法律。
翻车才是常态?
当然,不仅谷歌翻译,各种翻译软件也是经常翻车。
例如大量重复的翻译的内容相信经常使用翻译的用户都会遇到过。

古文翻译也是一个常见的翻译场景,但可能是翻译语料太少的缘故,常见的名人名言都无法正确翻译,不过语气词倒是翻译的很准确。

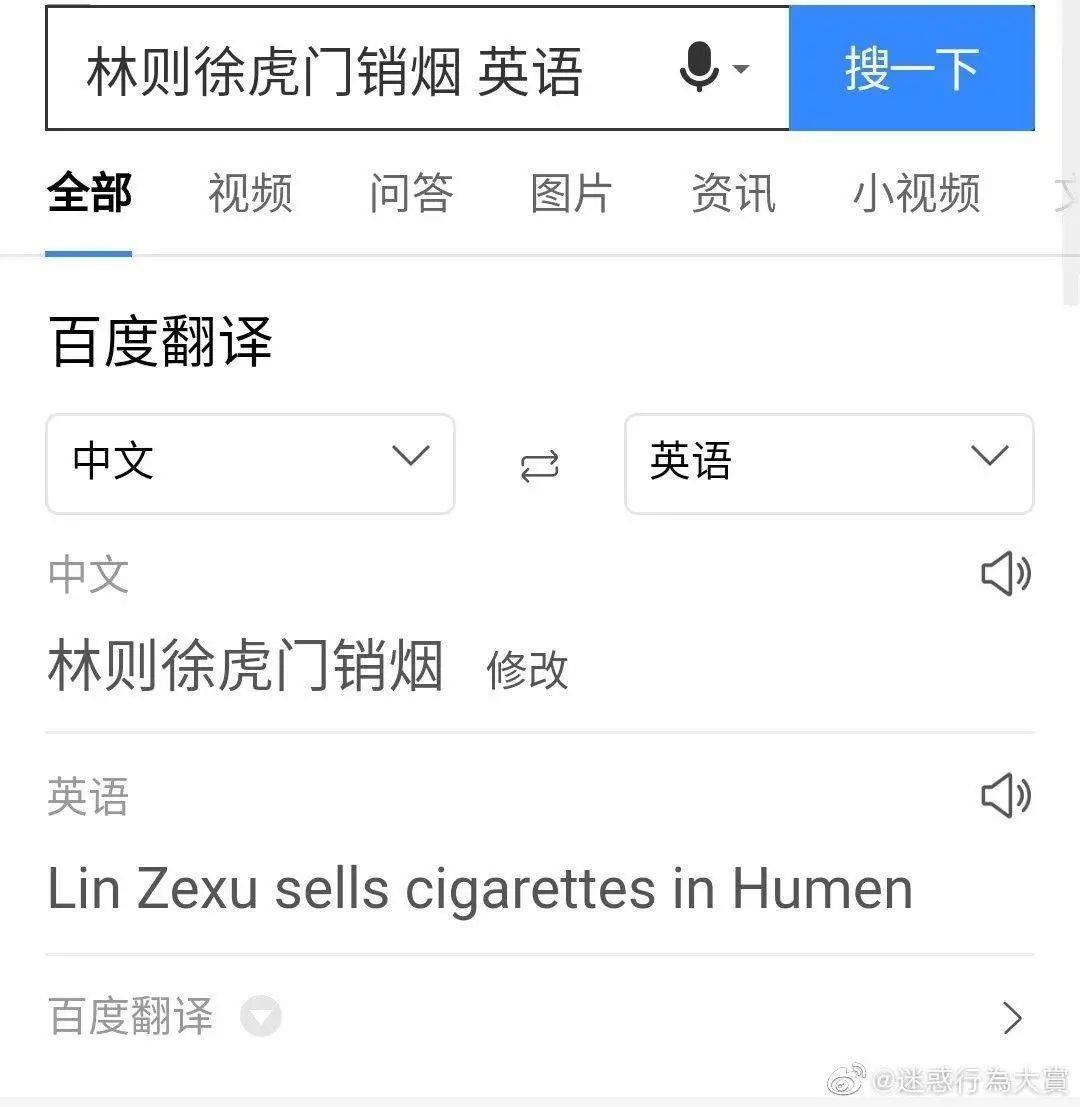
一些历史事件如虎门销烟(Destruction of opium at Humen),如果没有建立专门的短语库,也是一个大型翻车现场,例如百度翻译曾经把「林则徐虎门销烟」翻译为「林则徐在虎门卖烟」,目前该问题已经修复。
不过这也不能怪翻译软件,毕竟「销售」也是这个「销」,只能说中华文化博大精深,翻译软件也要倒在一词多义上。
一些明星与粉丝互动时也要依靠翻译软件,由于不懂目标语言,所以他们也无法检验翻译结果是否正确。
例如原本的意思是让没能到场的圣女们也能够high起来,然而也许是翻译软件太过于直白,弄出了一些虎狼之词

说到这里,就不得不说说机器翻译的发展。
在神经网络在NLP领域大火前,机器翻译界的主流方法都是Phrased-Based Machine Translation (PBMT),Google翻译使用的也是基于这个框架的算法。
所谓Phrased-based,即翻译的最小单位由任意连续的词(Word)组合成为的短语(Phrase)。
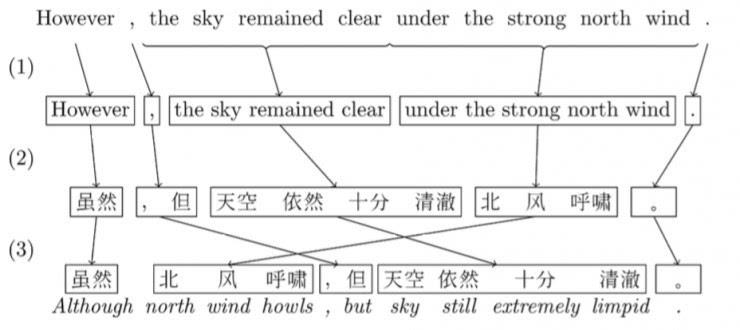
首先,算法会把句子打散成一个个由词语组成的词组(中文需要进行额外的分词);
然后,预先训练好的统计模型会对于每个词组,找到另一种语言中最佳对应的词组;
最后,需要将这样「硬生生」翻译过来的目标语言词组,通过重新排序,让它看起来尽量通顺以及符合目标语言的语法。
传统的PBMT的方法,一直被称为自然语言处理领域的终极任务之一。
因为整个翻译过程中,需要依次调用其他各种更底层的NLP算法,比如中文分词、词性标注、句法结构等等,最终才能生成正确的翻译。
这样像流水线一样的翻译方法,一环套一环,中间任意一个环节有了错误,这样的错误会一直传播下去,导致最终的结果出错。
因此,即使单个系统准确率可以高达95%,但是整个翻译流程走下来,最终累积的错误可能就不可接受了。
如果训练数据不干净,官方不加强审核机制,那以后谷歌翻译这样的「事故」还会更加多,人工智能的发展也应符合社会统一的道德要求,否则会对产品声誉造成巨大的负面影响。
觉得还不错就给我一个小小的鼓励吧!以上是关于谷歌翻译被曝“辱华”?官方回应来了的主要内容,如果未能解决你的问题,请参考以下文章